 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMUTF: Multimodal Multimedia Event Argument Extraction with Unified Template Filling
Paper and Code
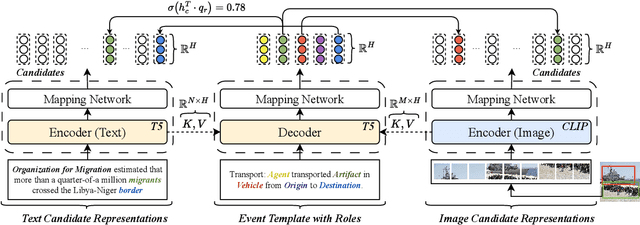
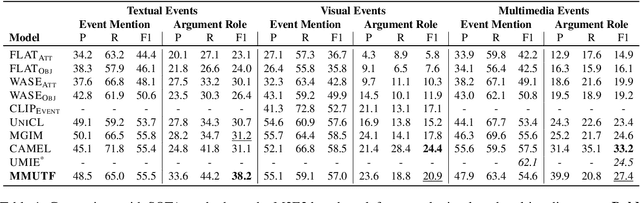
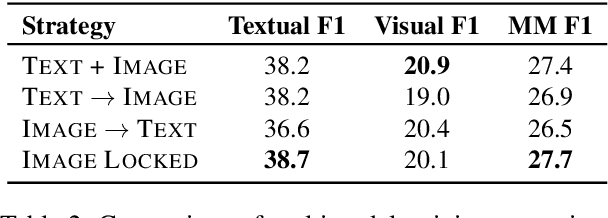
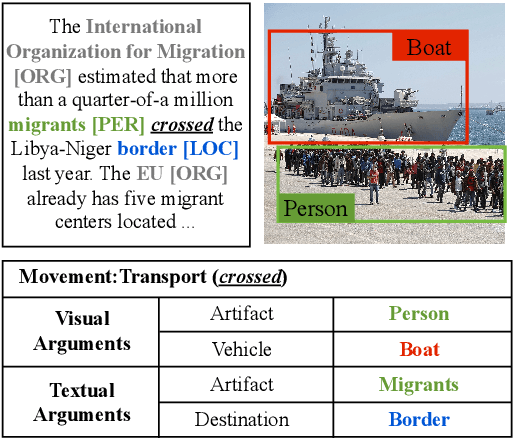
With the advancement of multimedia technologies, news documents and user-generated content are often represented as multiple modalities, making Multimedia Event Extraction (MEE) an increasingly important challenge. However, recent MEE methods employ weak alignment strategies and data augmentation with simple classification models, which ignore the capabilities of natural language-formulated event templates for the challenging Event Argument Extraction (EAE) task. In this work, we focus on EAE and address this issue by introducing a unified template filling model that connects the textual and visual modalities via textual prompts. This approach enables the exploitation of cross-ontology transfer and the incorporation of event-specific semantics. Experiments on the M2E2 benchmark demonstrate the effectiveness of our approach. Our system surpasses the current SOTA on textual EAE by +7% F1, and performs generally better than the second-best systems for multimedia EAE.