 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Fine-Tuning with Controllable Synthetic Speech from LLM-Generated Transcripts for Dysarthric Speech Recognition
May 19, 2025In this work, we present our submission to the Speech Accessibility Project challenge for dysarthric speech recognition. We integrate parameter-efficient fine-tuning with latent audio representations to improve an encoder-decoder ASR system. Synthetic training data is generated by fine-tuning Parler-TTS to mimic dysarthric speech, using LLM-generated prompts for corpus-consistent target transcripts. Personalization with x-vectors consistently reduces word error rates (WERs) over non-personalized fine-tuning. AdaLoRA adapters outperform full fine-tuning and standard low-rank adaptation, achieving relative WER reductions of ~23% and ~22%, respectively. Further improvements (~5% WER reduction) come from incorporating wav2vec 2.0-based audio representations. Training with synthetic dysarthric speech yields up to ~7% relative WER improvement over personalized fine-tuning alone.
Digital Operating Mode Classification of Real-World Amateur Radio Transmissions
Jan 13, 2025



This study presents an ML approach for classifying digital radio operating modes evaluated on real-world transmissions. We generated 98 different parameterized radio signals from 17 digital operating modes, transmitted each of them on the 70 cm (UHF) amateur radio band, and recorded our transmissions with two different architectures of SDR receivers. Three lightweight ML models were trained exclusively on spectrograms of limited non-transmitted signals with random characters as payloads. This training involved an online data augmentation pipeline to simulate various radio channel impairments. Our best model, EfficientNetB0, achieved an accuracy of 93.80% across the 17 operating modes and 85.47% across all 98 parameterized radio signals, evaluated on our real-world transmissions with Wikipedia articles as payloads. Furthermore, we analyzed the impact of varying signal durations & the number of FFT bins on classification, assessed the effectiveness of our simulated channel impairments, and tested our models across multiple simulated SNRs.
Large Language Models for Dysfluency Detection in Stuttered Speech
Jun 16, 2024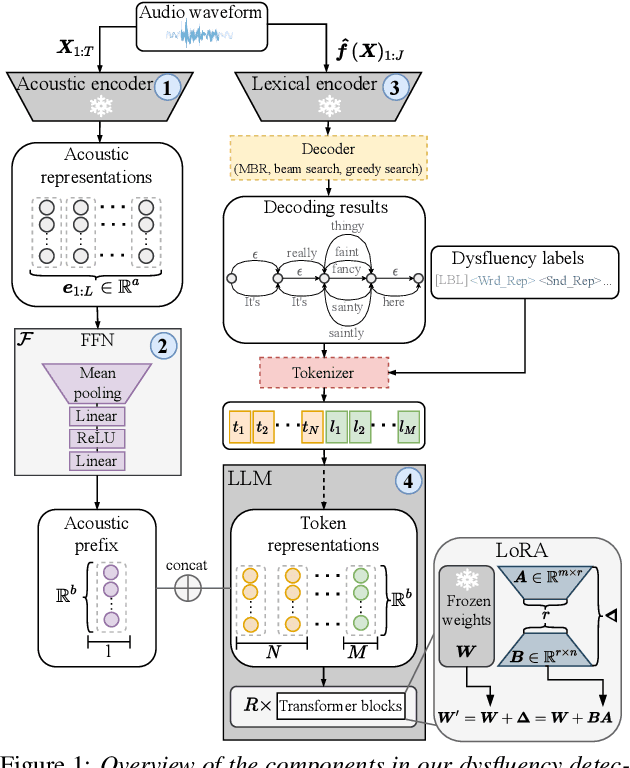
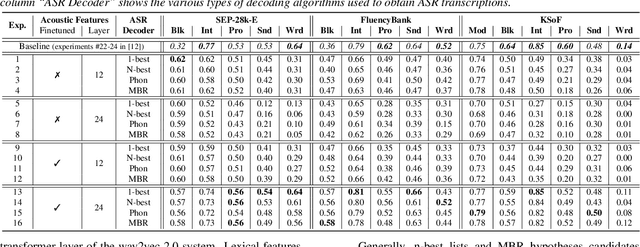
Accurately detecting dysfluencies in spoken language can help to improve the performance of automatic speech and language processing components and support the development of more inclusive speech and language technologies. Inspired by the recent trend towards the deployment of large language models (LLMs) as universal learners and processors of non-lexical inputs, such as audio and video, we approach the task of multi-label dysfluency detection as a language modeling problem. We present hypotheses candidates generated with an automatic speech recognition system and acoustic representations extracted from an audio encoder model to an LLM, and finetune the system to predict dysfluency labels on three datasets containing English and German stuttered speech. The experimental results show that our system effectively combines acoustic and lexical information and achieves competitive results on the multi-label stuttering detection task.
Optimized Speculative Sampling for GPU Hardware Accelerators
Jun 16, 2024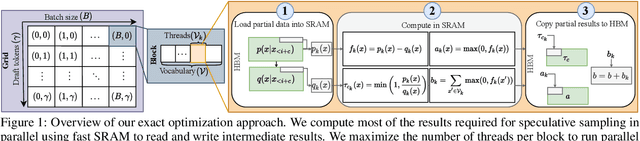
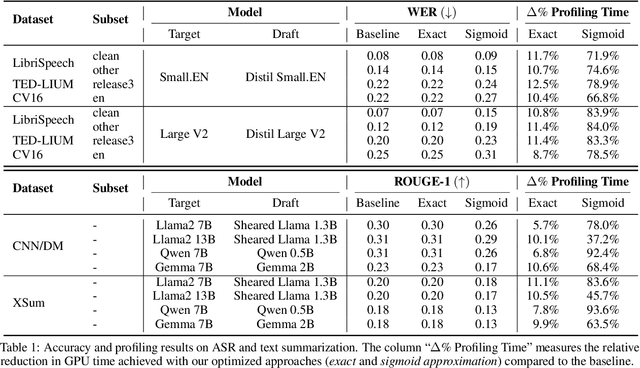


In this work, we optimize speculative sampling for parallel hardware accelerators to improve sampling speed. We notice that substantial portions of the intermediate matrices necessary for speculative sampling can be computed concurrently. This allows us to distribute the workload across multiple GPU threads, enabling simultaneous operations on matrix segments within thread blocks. Additionally, we use fast on-chip memory to store intermediate results, thereby minimizing the frequency of slow read and write operations across different types of memory. This results in profiling time improvements ranging from 6% to 13% relative to the baseline implementation, without compromising accuracy. To further accelerate speculative sampling, probability distributions parameterized by softmax are approximated by sigmoid. This approximation approach results in significantly greater relative improvements in profiling time, ranging from 37% to 94%, with a slight decline in accuracy. We conduct extensive experiments on both automatic speech recognition and summarization tasks to validate the effectiveness of our optimization methods.
Outlier Reduction with Gated Attention for Improved Post-training Quantization in Large Sequence-to-sequence Speech Foundation Models
Jun 16, 2024This paper explores the improvement of post-training quantization (PTQ) after knowledge distillation in the Whisper speech foundation model family. We address the challenge of outliers in weights and activation tensors, known to impede quantization quality in transformer-based language and vision models. Extending this observation to Whisper, we demonstrate that these outliers are also present when transformer-based models are trained to perform automatic speech recognition, necessitating mitigation strategies for PTQ. We show that outliers can be reduced by a recently proposed gating mechanism in the attention blocks of the student model, enabling effective 8-bit quantization, and lower word error rates compared to student models without the gating mechanism in place.
A Survey of Music Generation in the Context of Interaction
Feb 23, 2024



In recent years, machine learning, and in particular generative adversarial neural networks (GANs) and attention-based neural networks (transformers), have been successfully used to compose and generate music, both melodies and polyphonic pieces. Current research focuses foremost on style replication (eg. generating a Bach-style chorale) or style transfer (eg. classical to jazz) based on large amounts of recorded or transcribed music, which in turn also allows for fairly straight-forward "performance" evaluation. However, most of these models are not suitable for human-machine co-creation through live interaction, neither is clear, how such models and resulting creations would be evaluated. This article presents a thorough review of music representation, feature analysis, heuristic algorithms, statistical and parametric modelling, and human and automatic evaluation measures, along with a discussion of which approaches and models seem most suitable for live interaction.
Vocoder-Free Non-Parallel Conversion of Whispered Speech With Masked Cycle-Consistent Generative Adversarial Networks
Jun 10, 2023



Cycle-consistent generative adversarial networks have been widely used in non-parallel voice conversion (VC). Their ability to learn mappings between source and target features without relying on parallel training data eliminates the need for temporal alignments. However, most methods decouple the conversion of acoustic features from synthesizing the audio signal by using separate models for conversion and waveform synthesis. This work unifies conversion and synthesis into a single model, thereby eliminating the need for a separate vocoder. By leveraging cycle-consistent training and a self-supervised auxiliary training task, our model is able to efficiently generate converted high-quality raw audio waveforms. Subjective listening tests show that our method outperforms the baseline in whispered speech conversion (up to 6.7% relative improvement), and mean opinion score predictions yield competitive results in conventional VC (between 0.5% and 2.4% relative improvement).
A Stutter Seldom Comes Alone -- Cross-Corpus Stuttering Detection as a Multi-label Problem
May 30, 2023Most stuttering detection and classification research has viewed stuttering as a multi-class classification problem or a binary detection task for each dysfluency type; however, this does not match the nature of stuttering, in which one dysfluency seldom comes alone but rather co-occurs with others. This paper explores multi-language and cross-corpus end-to-end stuttering detection as a multi-label problem using a modified wav2vec 2.0 system with an attention-based classification head and multi-task learning. We evaluate the method using combinations of three datasets containing English and German stuttered speech, one containing speech modified by fluency shaping. The experimental results and an error analysis show that multi-label stuttering detection systems trained on cross-corpus and multi-language data achieve competitive results but performance on samples with multiple labels stays below over-all detection results.
Speaker Adaptation for End-To-End Speech Recognition Systems in Noisy Environments
Nov 16, 2022
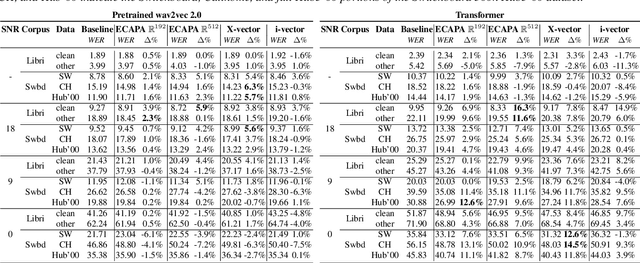
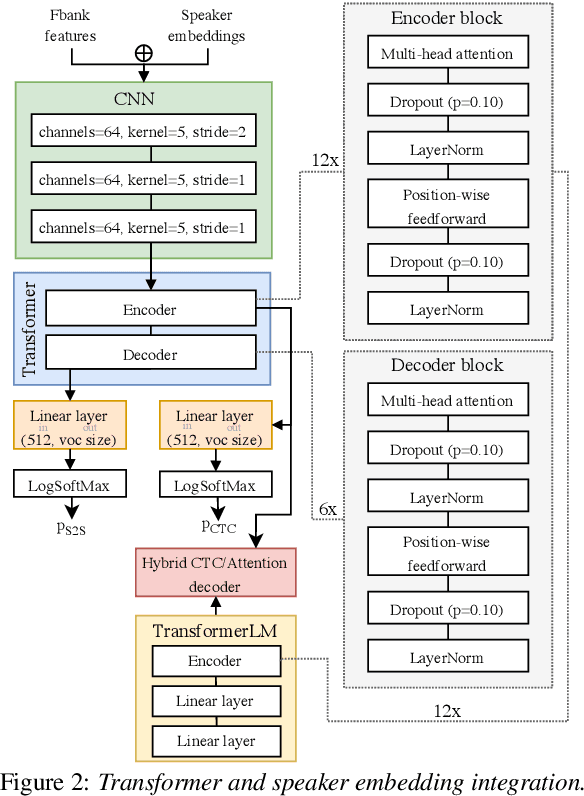
We analyze the impact of speaker adaptation in end-to-end architectures based on transformers and wav2vec 2.0 under different noise conditions. We demonstrate that the proven method of concatenating speaker vectors to the acoustic features and supplying them as an auxiliary model input remains a viable option to increase the robustness of end-to-end architectures. By including speaker embeddings obtained from x-vector and ECAPA-TDNN models, we achieve relative word error rate improvements of up to 9.6% on LibriSpeech and up to 14.5% on Switchboard. The effect on transformer-based architectures is approximately inversely proportional to the signal-to-noise ratio (SNR) and is strongest in heavily noised environments ($SNR=0$). The most substantial benefit of speaker adaption in systems based on wav2vec 2.0 can be achieved under moderate noise conditions ($SNR\geq18$). We also find that x-vectors tend to yield larger improvements than ECAPA-TDNN embeddings.
The Importance of Speech Stimuli for Pathologic Speech Classification
Oct 28, 2022
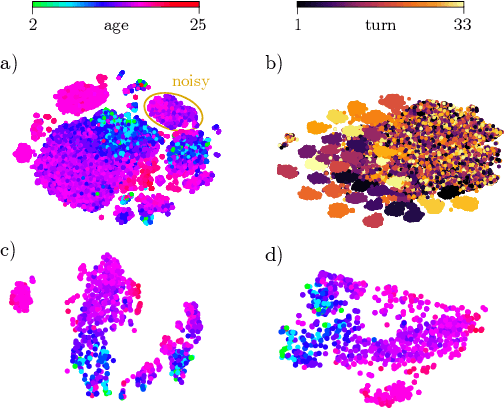
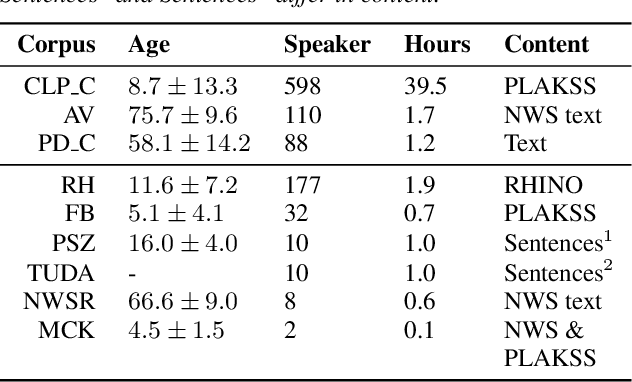
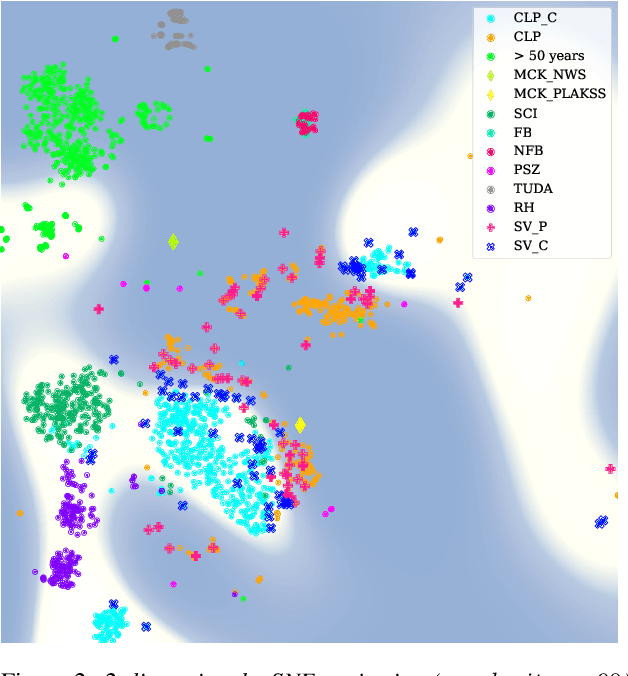
Current findings show that pre-trained wav2vec 2.0 models can be successfully used as feature extractors to discriminate on speaker-based tasks. We demonstrate that latent representations extracted at different layers of a pre-trained wav2vec 2.0 system can be effectively used for binary classification of various types of pathologic speech. We examine the pathologies laryngectomy, oral squamous cell carcinoma, parkinson's disease and cleft lip and palate for this purpose. The results show that a distinction between pathological and healthy voices, especially with latent representations from the lower layers, performs well with the lowest accuracy from 77.2% for parkinson's disease to 100% for laryngectomy classification. However, cross-pathology and cross-healthy tests show that the trained classifiers seem to be biased. The recognition rates vary considerably if there is a mismatch between training and out-of-domain test data, e.g., in age, spoken content or acoustic conditions.