 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PARLO Dementia Corpus: A German Multi-Center Resource for Alzheimer's Disease
Mar 05, 2026Early and accessible detection of Alzheimer's disease (AD) remains a major challenge, as current diagnostic methods often rely on costly and invasive biomarkers. Speech and language analysis has emerged as a promising non-invasive and scalable approach to detecting cognitive impairment, but research in this area is hindered by the lack of publicly available datasets, especially for languages other than English. This paper introduces the PARLO Dementia Corpus (PDC), a new multi-center, clinically validated German resource for AD collected across nine academic memory clinics in Germany. The dataset comprises speech recordings from individuals with AD-related mild cognitive impairment and mild to moderate dementia, as well as cognitively healthy controls. Speech was elicited using a standardized test battery of eight neuropsychological tasks, including confrontation naming, verbal fluency, word repetition, picture description, story reading, and recall tasks. In addition to audio recordings, the dataset includes manually verified transcriptions and detailed demographic, clinical, and biomarker metadata. Baseline experiments on ASR benchmarking, automated test evaluation, and LLM-based classification illustrate the feasibility of automatic, speech-based cognitive assessment and highlight the diagnostic value of recall-driven speech production. The PDC thus establishes the first publicly available German benchmark for multi-modal and cross-lingual research on neurodegenerative diseases.
Pitfalls and Limits in Automatic Dementia Assessment
Aug 06, 2025



Current work on speech-based dementia assessment focuses on either feature extraction to predict assessment scales, or on the automation of existing test procedures. Most research uses public data unquestioningly and rarely performs a detailed error analysis, focusing primarily on numerical performance. We perform an in-depth analysis of an automated standardized dementia assessment, the Syndrom-Kurz-Test. We find that while there is a high overall correlation with human annotators, due to certain artifacts, we observe high correlations for the severely impaired individuals, which is less true for the healthy or mildly impaired ones. Speech production decreases with cognitive decline, leading to overoptimistic correlations when test scoring relies on word naming. Depending on the test design, fallback handling introduces further biases that favor certain groups. These pitfalls remain independent of group distributions in datasets and require differentiated analysis of target groups.
Infusing Acoustic Pause Context into Text-Based Dementia Assessment
Aug 27, 2024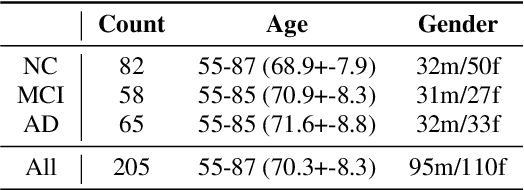
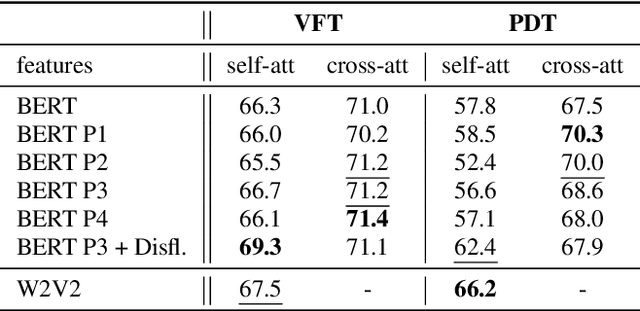
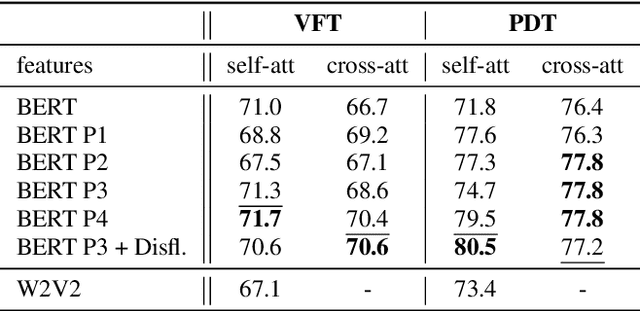
Speech pauses, alongside content and structure, offer a valuable and non-invasive biomarker for detecting dementia. This work investigates the use of pause-enriched transcripts in transformer-based language models to differentiate the cognitive states of subjects with no cognitive impairment, mild cognitive impairment, and Alzheimer's dementia based on their speech from a clinical assessment. We address three binary classification tasks: Onset, monitoring, and dementia exclusion. The performance is evaluated through experiments on a German Verbal Fluency Test and a Picture Description Test, comparing the model's effectiveness across different speech production contexts. Starting from a textual baseline, we investigate the effect of incorporation of pause information and acoustic context. We show the test should be chosen depending on the task, and similarly, lexical pause information and acoustic cross-attention contribute differently.
A Survey of Music Generation in the Context of Interaction
Feb 23, 2024



In recent years, machine learning, and in particular generative adversarial neural networks (GANs) and attention-based neural networks (transformers), have been successfully used to compose and generate music, both melodies and polyphonic pieces. Current research focuses foremost on style replication (eg. generating a Bach-style chorale) or style transfer (eg. classical to jazz) based on large amounts of recorded or transcribed music, which in turn also allows for fairly straight-forward "performance" evaluation. However, most of these models are not suitable for human-machine co-creation through live interaction, neither is clear, how such models and resulting creations would be evaluated. This article presents a thorough review of music representation, feature analysis, heuristic algorithms, statistical and parametric modelling, and human and automatic evaluation measures, along with a discussion of which approaches and models seem most suitable for live interaction.
Classifying Dementia in the Presence of Depression: A Cross-Corpus Study
Aug 16, 2023Automated dementia screening enables early detection and intervention, reducing costs to healthcare systems and increasing quality of life for those affected. Depression has shared symptoms with dementia, adding complexity to diagnoses. The research focus so far has been on binary classification of dementia (DEM) and healthy controls (HC) using speech from picture description tests from a single dataset. In this work, we apply established baseline systems to discriminate cognitive impairment in speech from the semantic Verbal Fluency Test and the Boston Naming Test using text, audio and emotion embeddings in a 3-class classification problem (HC vs. MCI vs. DEM). We perform cross-corpus and mixed-corpus experiments on two independently recorded German datasets to investigate generalization to larger populations and different recording conditions. In a detailed error analysis, we look at depression as a secondary diagnosis to understand what our classifiers actually learn.
The Importance of Speech Stimuli for Pathologic Speech Classification
Oct 28, 2022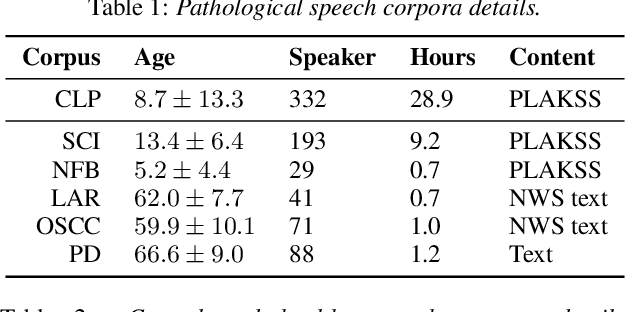
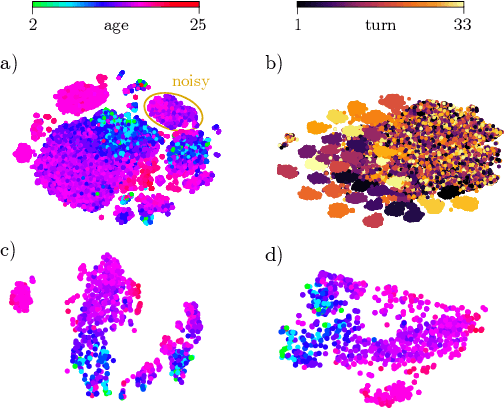
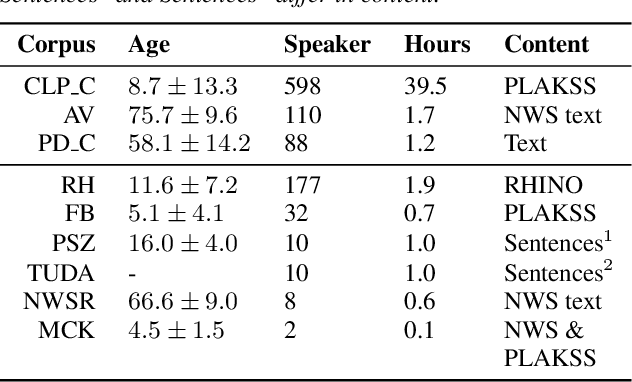
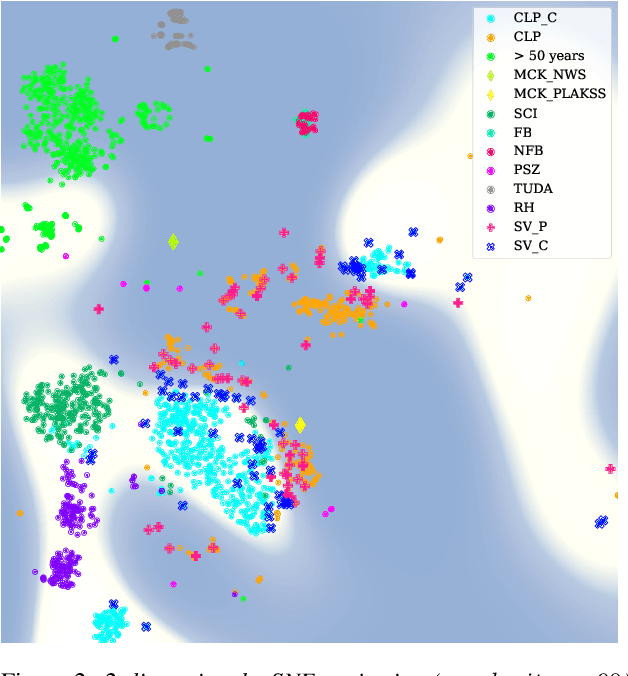
Current findings show that pre-trained wav2vec 2.0 models can be successfully used as feature extractors to discriminate on speaker-based tasks. We demonstrate that latent representations extracted at different layers of a pre-trained wav2vec 2.0 system can be effectively used for binary classification of various types of pathologic speech. We examine the pathologies laryngectomy, oral squamous cell carcinoma, parkinson's disease and cleft lip and palate for this purpose. The results show that a distinction between pathological and healthy voices, especially with latent representations from the lower layers, performs well with the lowest accuracy from 77.2% for parkinson's disease to 100% for laryngectomy classification. However, cross-pathology and cross-healthy tests show that the trained classifiers seem to be biased. The recognition rates vary considerably if there is a mismatch between training and out-of-domain test data, e.g., in age, spoken content or acoustic conditions.
Multi-class Detection of Pathological Speech with Latent Features: How does it perform on unseen data?
Oct 27, 2022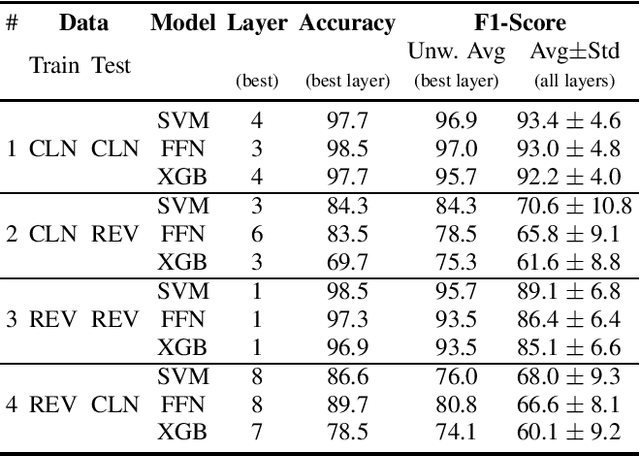

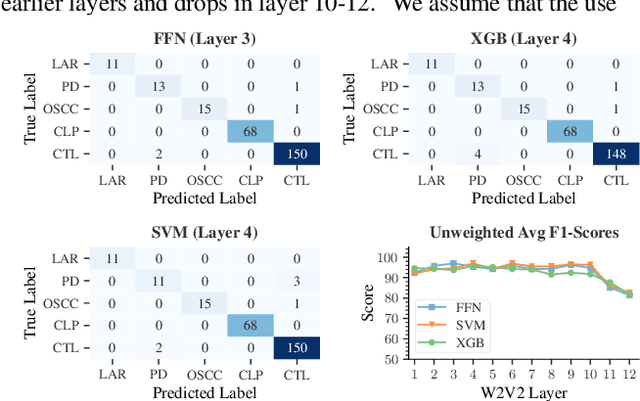
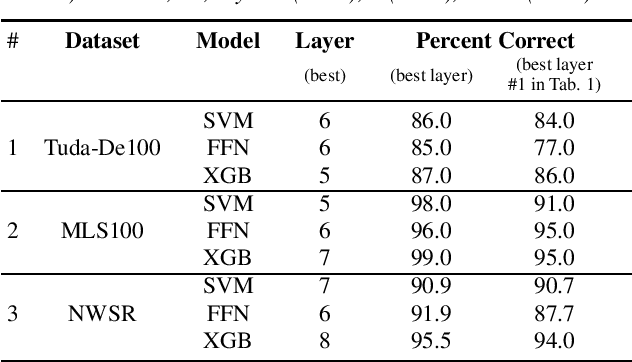
The detection of pathologies from speech features is usually defined as a binary classification task with one class representing a specific pathology and the other class representing healthy speech. In this work, we train neural networks, large margin classifiers, and tree boosting machines to distinguish between four different pathologies: Parkinson's disease, laryngeal cancer, cleft lip and palate, and oral squamous cell carcinoma. We demonstrate that latent representations extracted at different layers of a pre-trained wav2vec 2.0 system can be effectively used to classify these types of pathological voices. We evaluate the robustness of our classifiers by adding room impulse responses to the test data and by applying them to unseen speech corpora. Our approach achieves unweighted average F1-Scores between 74.1% and 96.4%, depending on the model and the noise conditions used. The systems generalize and perform well on unseen data of healthy speakers sampled from a variety of different sources.
Automated Evaluation of Standardized Dementia Screening Tests
Jun 13, 2022
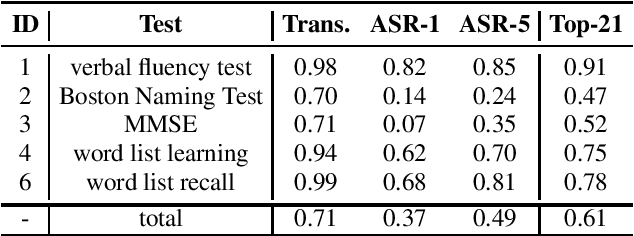
For dementia screening and monitoring, standardized tests play a key role in clinical routine since they aim at minimizing subjectivity by measuring performance on a variety of cognitive tasks. In this paper, we report on a study that consists of a semi-standardized history taking followed by two standardized neuropsychological tests, namely the SKT and the CERAD-NB. The tests include basic tasks such as naming objects, learning word lists, but also widely used tools such as the MMSE. Most of the tasks are performed verbally and should thus be suitable for automated scoring based on transcripts. For the first batch of 30 patients, we analyze the correlation between expert manual evaluations and automatic evaluations based on manual and automatic transcriptions. For both SKT and CERAD-NB, we observe high to perfect correlations using manual transcripts; for certain tasks with lower correlation, the automatic scoring is stricter than the human reference since it is limited to the audio. Using automatic transcriptions, correlations drop as expected and are related to recognition accuracy; however, we still observe high correlations of up to 0.98 (SKT) and 0.85 (CERAD-NB). We show that using word alternatives helps to mitigate recognition errors and subsequently improves correlation with expert scores.
Going Beyond the Cookie Theft Picture Test: Detecting Cognitive Impairments using Acoustic Features
Jun 10, 2022

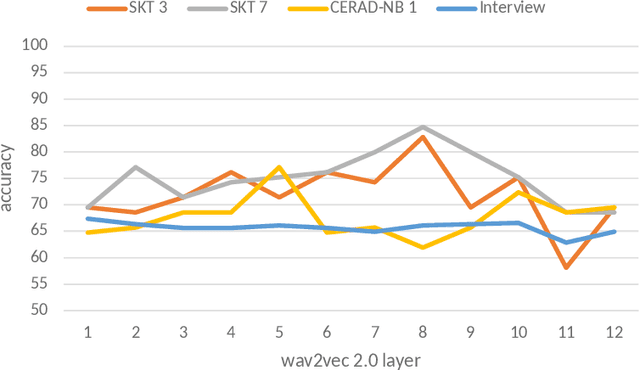
Standardized tests play a crucial role in the detection of cognitive impairment. Previous work demonstrated that automatic detection of cognitive impairment is possible using audio data from a standardized picture description task. The presented study goes beyond that, evaluating our methods on data taken from two standardized neuropsychological tests, namely the German SKT and a German version of the CERAD-NB, and a semi-structured clinical interview between a patient and a psychologist. For the tests, we focus on speech recordings of three sub-tests: reading numbers (SKT 3), interference (SKT 7), and verbal fluency (CERAD-NB 1). We show that acoustic features from standardized tests can be used to reliably discriminate cognitively impaired individuals from non-impaired ones. Furthermore, we provide evidence that even features extracted from random speech samples of the interview can be a discriminator of cognitive impairment. In our baseline experiments, we use OpenSMILE features and Support Vector Machine classifiers. In an improved setup, we show that using wav2vec 2.0 features instead, we can achieve an accuracy of up to 85%.