 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Self-Supervised Speech Representations for Cross-lingual Dysarthria Detection in Parkinson's Disease
Mar 23, 2026The limited availability of dysarthric speech data makes cross-lingual detection an important but challenging problem. A key difficulty is that speech representations often encode language-dependent structure that can confound dysarthria detection. We propose a representation-level language shift (LS) that aligns source-language self-supervised speech representations with the target-language distribution using centroid-based vector adaptation estimated from healthy-control speech. We evaluate the approach on oral DDK recordings from Parkinson's disease speech datasets in Czech, German, and Spanish under both cross-lingual and multilingual settings. LS substantially improves sensitivity and F1 in cross-lingual settings, while yielding smaller but consistent gains in multilingual settings. Representation analysis further shows that LS reduces language identity in the embedding space, supporting the interpretation that LS removes language-dependent structure.
The PARLO Dementia Corpus: A German Multi-Center Resource for Alzheimer's Disease
Mar 05, 2026Early and accessible detection of Alzheimer's disease (AD) remains a major challenge, as current diagnostic methods often rely on costly and invasive biomarkers. Speech and language analysis has emerged as a promising non-invasive and scalable approach to detecting cognitive impairment, but research in this area is hindered by the lack of publicly available datasets, especially for languages other than English. This paper introduces the PARLO Dementia Corpus (PDC), a new multi-center, clinically validated German resource for AD collected across nine academic memory clinics in Germany. The dataset comprises speech recordings from individuals with AD-related mild cognitive impairment and mild to moderate dementia, as well as cognitively healthy controls. Speech was elicited using a standardized test battery of eight neuropsychological tasks, including confrontation naming, verbal fluency, word repetition, picture description, story reading, and recall tasks. In addition to audio recordings, the dataset includes manually verified transcriptions and detailed demographic, clinical, and biomarker metadata. Baseline experiments on ASR benchmarking, automated test evaluation, and LLM-based classification illustrate the feasibility of automatic, speech-based cognitive assessment and highlight the diagnostic value of recall-driven speech production. The PDC thus establishes the first publicly available German benchmark for multi-modal and cross-lingual research on neurodegenerative diseases.
Bias and Fairness in Self-Supervised Acoustic Representations for Cognitive Impairment Detection
Mar 03, 2026Speech-based detection of cognitive impairment (CI) offers a promising non-invasive approach for early diagnosis, yet performance disparities across demographic and clinical subgroups remain underexplored, raising concerns around fairness and generalizability. This study presents a systematic bias analysis of acoustic-based CI and depression classification using the DementiaBank Pitt Corpus. We compare traditional acoustic features (MFCCs, eGeMAPS) with contextualized speech embeddings from Wav2Vec 2.0 (W2V2), and evaluate classification performance across gender, age, and depression-status subgroups. For CI detection, higher-layer W2V2 embeddings outperform baseline features (UAR up to 80.6\%), but exhibit performance disparities; specifically, females and younger participants demonstrate lower discriminative power (\(AUC\): 0.769 and 0.746, respectively) and substantial specificity disparities (\(Δ_{spec}\) up to 18\% and 15\%, respectively), leading to a higher risk of misclassifications than their counterparts. These disparities reflect representational biases, defined as systematic differences in model performance across demographic or clinical subgroups. Depression detection within CI subjects yields lower overall performance, with mild improvements from low and mid-level W2V2 layers. Cross-task generalization between CI and depression classification is limited, indicating that each task depends on distinct representations. These findings emphasize the need for fairness-aware model evaluation and subgroup-specific analysis in clinical speech applications, particularly in light of demographic and clinical heterogeneity in real-world applications.
Towards Inclusive ASR: Investigating Voice Conversion for Dysarthric Speech Recognition in Low-Resource Languages
May 20, 2025Automatic speech recognition (ASR) for dysarthric speech remains challenging due to data scarcity, particularly in non-English languages. To address this, we fine-tune a voice conversion model on English dysarthric speech (UASpeech) to encode both speaker characteristics and prosodic distortions, then apply it to convert healthy non-English speech (FLEURS) into non-English dysarthric-like speech. The generated data is then used to fine-tune a multilingual ASR model, Massively Multilingual Speech (MMS), for improved dysarthric speech recognition. Evaluation on PC-GITA (Spanish), EasyCall (Italian), and SSNCE (Tamil) demonstrates that VC with both speaker and prosody conversion significantly outperforms the off-the-shelf MMS performance and conventional augmentation techniques such as speed and tempo perturbation. Objective and subjective analyses of the generated data further confirm that the generated speech simulates dysarthric characteristics.
Personalized Fine-Tuning with Controllable Synthetic Speech from LLM-Generated Transcripts for Dysarthric Speech Recognition
May 19, 2025In this work, we present our submission to the Speech Accessibility Project challenge for dysarthric speech recognition. We integrate parameter-efficient fine-tuning with latent audio representations to improve an encoder-decoder ASR system. Synthetic training data is generated by fine-tuning Parler-TTS to mimic dysarthric speech, using LLM-generated prompts for corpus-consistent target transcripts. Personalization with x-vectors consistently reduces word error rates (WERs) over non-personalized fine-tuning. AdaLoRA adapters outperform full fine-tuning and standard low-rank adaptation, achieving relative WER reductions of ~23% and ~22%, respectively. Further improvements (~5% WER reduction) come from incorporating wav2vec 2.0-based audio representations. Training with synthetic dysarthric speech yields up to ~7% relative WER improvement over personalized fine-tuning alone.
A Speech-to-Video Synthesis Approach Using Spatio-Temporal Diffusion for Vocal Tract MRI
Mar 15, 2025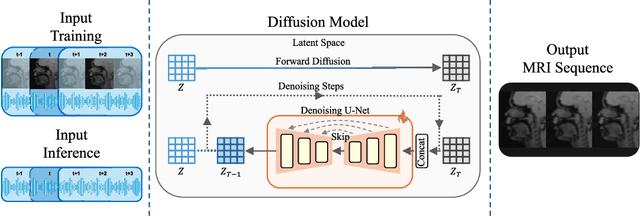
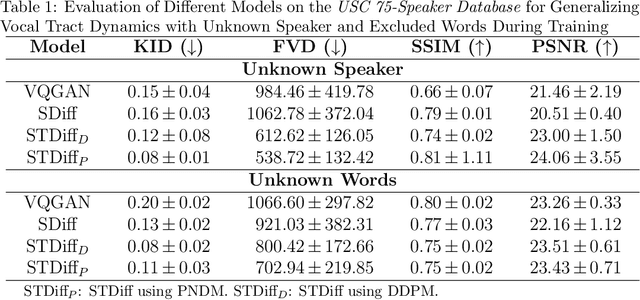
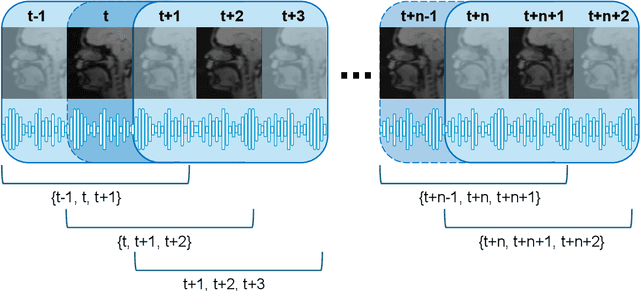

Understanding the relationship between vocal tract motion during speech and the resulting acoustic signal is crucial for aided clinical assessment and developing personalized treatment and rehabilitation strategies. Toward this goal, we introduce an audio-to-video generation framework for creating Real Time/cine-Magnetic Resonance Imaging (RT-/cine-MRI) visuals of the vocal tract from speech signals. Our framework first preprocesses RT-/cine-MRI sequences and speech samples to achieve temporal alignment, ensuring synchronization between visual and audio data. We then employ a modified stable diffusion model, integrating structural and temporal blocks, to effectively capture movement characteristics and temporal dynamics in the synchronized data. This process enables the generation of MRI sequences from new speech inputs, improving the conversion of audio into visual data. We evaluated our framework on healthy controls and tongue cancer patients by analyzing and comparing the vocal tract movements in synthesized videos. Our framework demonstrated adaptability to new speech inputs and effective generalization. In addition, positive human evaluations confirmed its effectiveness, with realistic and accurate visualizations, suggesting its potential for outpatient therapy and personalized simulation of vocal tract visualizations.
Large Language Models for Dysfluency Detection in Stuttered Speech
Jun 16, 2024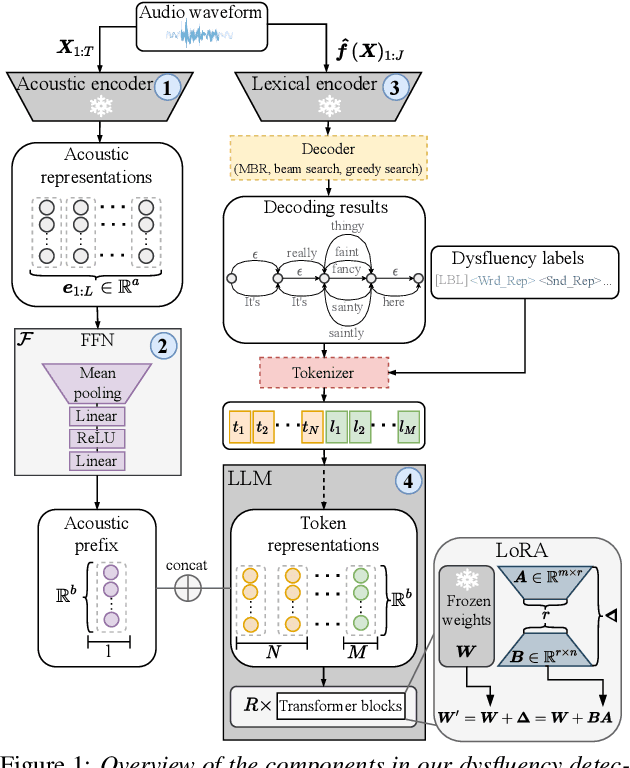
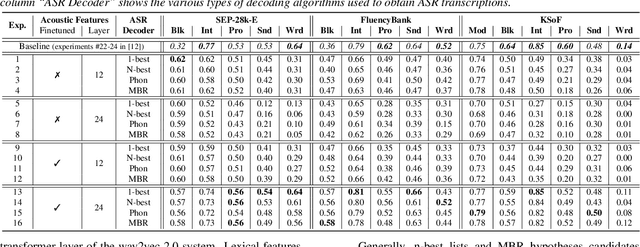
Accurately detecting dysfluencies in spoken language can help to improve the performance of automatic speech and language processing components and support the development of more inclusive speech and language technologies. Inspired by the recent trend towards the deployment of large language models (LLMs) as universal learners and processors of non-lexical inputs, such as audio and video, we approach the task of multi-label dysfluency detection as a language modeling problem. We present hypotheses candidates generated with an automatic speech recognition system and acoustic representations extracted from an audio encoder model to an LLM, and finetune the system to predict dysfluency labels on three datasets containing English and German stuttered speech. The experimental results show that our system effectively combines acoustic and lexical information and achieves competitive results on the multi-label stuttering detection task.
Classifying Dementia in the Presence of Depression: A Cross-Corpus Study
Aug 16, 2023Automated dementia screening enables early detection and intervention, reducing costs to healthcare systems and increasing quality of life for those affected. Depression has shared symptoms with dementia, adding complexity to diagnoses. The research focus so far has been on binary classification of dementia (DEM) and healthy controls (HC) using speech from picture description tests from a single dataset. In this work, we apply established baseline systems to discriminate cognitive impairment in speech from the semantic Verbal Fluency Test and the Boston Naming Test using text, audio and emotion embeddings in a 3-class classification problem (HC vs. MCI vs. DEM). We perform cross-corpus and mixed-corpus experiments on two independently recorded German datasets to investigate generalization to larger populations and different recording conditions. In a detailed error analysis, we look at depression as a secondary diagnosis to understand what our classifiers actually learn.
A Stutter Seldom Comes Alone -- Cross-Corpus Stuttering Detection as a Multi-label Problem
May 30, 2023Most stuttering detection and classification research has viewed stuttering as a multi-class classification problem or a binary detection task for each dysfluency type; however, this does not match the nature of stuttering, in which one dysfluency seldom comes alone but rather co-occurs with others. This paper explores multi-language and cross-corpus end-to-end stuttering detection as a multi-label problem using a modified wav2vec 2.0 system with an attention-based classification head and multi-task learning. We evaluate the method using combinations of three datasets containing English and German stuttered speech, one containing speech modified by fluency shaping. The experimental results and an error analysis show that multi-label stuttering detection systems trained on cross-corpus and multi-language data achieve competitive results but performance on samples with multiple labels stays below over-all detection results.
The Importance of Speech Stimuli for Pathologic Speech Classification
Oct 28, 2022
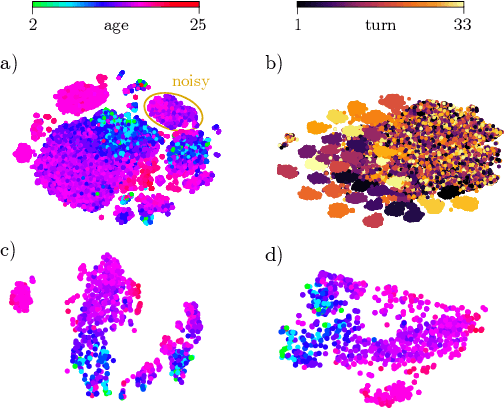
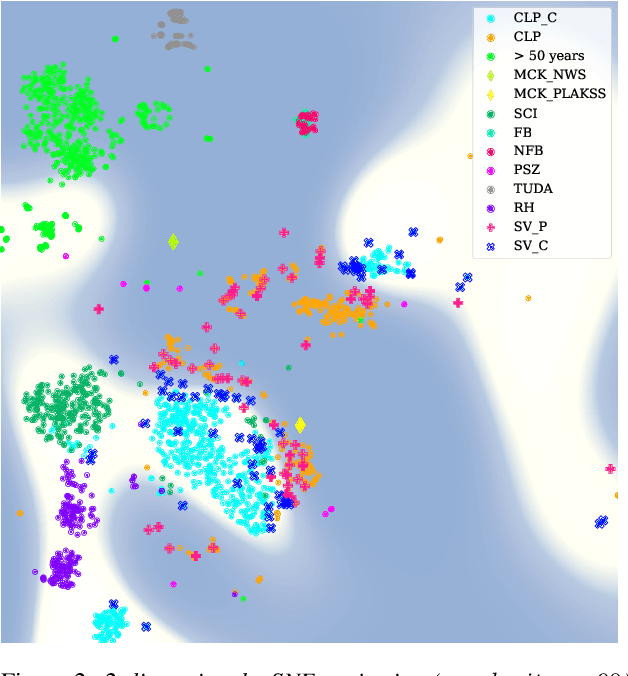
Current findings show that pre-trained wav2vec 2.0 models can be successfully used as feature extractors to discriminate on speaker-based tasks. We demonstrate that latent representations extracted at different layers of a pre-trained wav2vec 2.0 system can be effectively used for binary classification of various types of pathologic speech. We examine the pathologies laryngectomy, oral squamous cell carcinoma, parkinson's disease and cleft lip and palate for this purpose. The results show that a distinction between pathological and healthy voices, especially with latent representations from the lower layers, performs well with the lowest accuracy from 77.2% for parkinson's disease to 100% for laryngectomy classification. However, cross-pathology and cross-healthy tests show that the trained classifiers seem to be biased. The recognition rates vary considerably if there is a mismatch between training and out-of-domain test data, e.g., in age, spoken content or acoustic conditions.