 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting gestational age at birth in the context of preterm birth from multi-modal fetal MRI
Jun 18, 2026Preterm birth is associated with significant mortality and a risk for lifelong morbidity. The complex multifactorial aetiology hampers accurate prediction and thus optimal care. A pipeline consisting of bespoke machine learning methods for data imputation, feature selection, and regression models to predict gestational age (GA) at birth was developed and evaluated from comprehensive multi-modal morphological and functional fetal MRI data from 333 control cases and 93 preterm birth cases. The GA at birth predictions were classified into term and preterm categories and their accuracy, sensitivity, and specificity were reported. An ablation study was performed to further validate the design of the pipeline. Performance was evaluated using stratified 10-fold cross-validation. The pipeline achieves an R2 score of 0.13 and a mean absolute error of 2.74 weeks. It also achieves a 0.77 accuracy, 0.59 sensitivity, and 0.82 specificity across folds. The predominant features selected by the pipeline include cervical length and statistics derived from placental T2* values. The confluence of fast, motion-robust and multi-modal fetal MRI techniques and machine learning prediction allowed the prediction of the gestation at birth. This information is essential for any pregnancy. To the best of our knowledge, preterm birth had only been addressed as a classification problem in the literature. Therefore, this work provides a proof of concept. Future work will increase the cohort size to allow for finer stratification within the preterm birth cohort. Our code is available at https://github.com/dfajardorojas/ml-for-preterm-birth-.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2026:013
Speech-Guided Multimodal Learning for Vocal Tract Segmentation in Real-Time MRI
May 18, 2026Segmenting vocal tract articulators in real-time MRI (rtMRI) is a challenging dynamic image segmentation problem characterized by low contrast, rapid motion, and limited spatial resolution. However, while rtMRI acquisitions may provide synchronized acoustic signals, existing methods discard this information, and the few multimodal approaches that incorporate audio cannot be deployed when audio is unavailable. We propose a three-stage framework that leverages acoustic and phonological supervision during training while requiring only the rtMRI image at inference: phonological representations are converted into spatial bounding-box priors for articulator localization, visual and acoustic encoders are aligned via dual-level cross-modal contrastive pretraining, and the learned representations are fused through a cross-attention decoder, effectively transferring multimodal knowledge into a single-modality inference pipeline. Evaluated on 75-Speaker~Annot-16 and USC-TIMIT datasets, our method outperforms existing unimodal and multimodal methods, demonstrating that multimodal supervision provides transferable benefits for precise and clinically deployable vocal tract segmentation.
SIREM: Speech-Informed MRI Reconstruction with Learned Sampling
May 18, 2026Real-time magnetic resonance imaging (rtMRI) of speech production enables non-invasive visualization of dynamic vocal-tract motion and is valuable for speech science and clinical assessment. However, rtMRI is fundamentally constrained by trade-offs among spatial resolution, temporal resolution, and acquisition speed, often leading to undersampled k-space measurements and degraded reconstructions. We propose SIREM, a speech-informed MRI reconstruction framework that uses synchronized speech as a cross-modal prior. The central idea is that vocal-tract configurations during speech are correlated with the produced acoustics, making part of the image content predictable from audio. SIREM models each frame as a fusion of an audio-driven component and an MRI-driven component through a spatial weighting map. The audio branch predicts articulator-related structure from speech, while the MRI branch reconstructs complementary content from measured k-space data. We further introduce a learnable soft weighting profile over spiral arms, enabling a differentiable study of how k-space arm usage interacts with speech-informed fusion. This yields a unified multimodal formulation that combines audio-driven prediction, MRI reconstruction, and sampling adaptation. We evaluate SIREM on the USC speech rtMRI benchmark against standard baselines, including gridding, wavelet-based compressed sensing, and total variation. SIREM introduces a speech-informed reconstruction paradigm that operates in a substantially higher-throughput regime than iterative methods while preserving anatomically plausible vocal-tract structure. These results establish an initial benchmark for multimodal speech-informed rtMRI reconstruction and highlight the potential of synchronized speech as an auxiliary prior for fast reconstruction. The source code is available at https://github.com/mdhasanai/SIREM
Unsupervised Anomaly Detection of Diseases in the Female Pelvis for Real-Time MR Imaging
Feb 05, 2026Pelvic diseases in women of reproductive age represent a major global health burden, with diagnosis frequently delayed due to high anatomical variability, complicating MRI interpretation. Existing AI approaches are largely disease-specific and lack real-time compatibility, limiting generalizability and clinical integration. To address these challenges, we establish a benchmark framework for disease- and parameter-agnostic, real-time-compatible unsupervised anomaly detection in pelvic MRI. The method uses a residual variational autoencoder trained exclusively on healthy sagittal T2-weighted scans acquired across diverse imaging protocols to model normal pelvic anatomy. During inference, reconstruction error heatmaps indicate deviations from learned healthy structure, enabling detection of pathological regions without labeled abnormal data. The model is trained on 294 healthy scans and augmented with diffusion-generated synthetic data to improve robustness. Quantitative evaluation on the publicly available Uterine Myoma MRI Dataset yields an average area-under-the-curve (AUC) value of 0.736, with 0.828 sensitivity and 0.692 specificity. Additional inter-observer clinical evaluation extends analysis to endometrial cancer, endometriosis, and adenomyosis, revealing the influence of anatomical heterogeneity and inter-observer variability on performance interpretation. With a reconstruction time of approximately 92.6 frames per second, the proposed framework establishes a baseline for unsupervised anomaly detection in the female pelvis and supports future integration into real-time MRI. Code is available upon request (https://github.com/AniKnu/UADPelvis), prospective data sets are available for academic collaboration.
Diffusing the Blind Spot: Uterine MRI Synthesis with Diffusion Models
Aug 11, 2025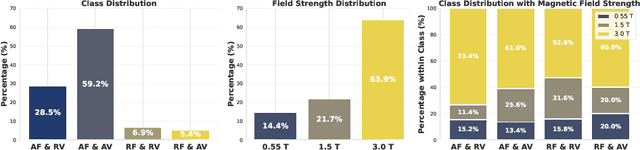
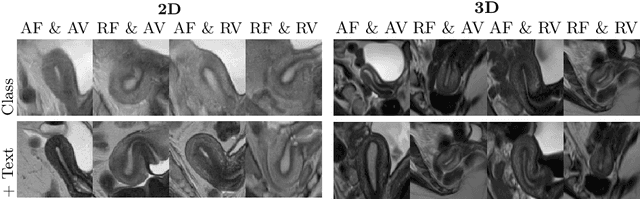
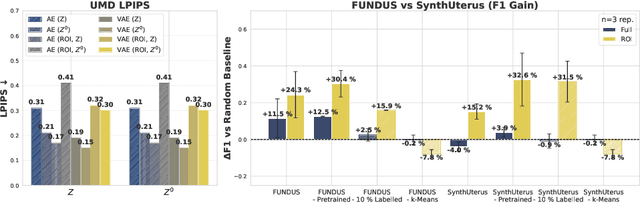
Despite significant progress in generative modelling, existing diffusion models often struggle to produce anatomically precise female pelvic images, limiting their application in gynaecological imaging, where data scarcity and patient privacy concerns are critical. To overcome these barriers, we introduce a novel diffusion-based framework for uterine MRI synthesis, integrating both unconditional and conditioned Denoising Diffusion Probabilistic Models (DDPMs) and Latent Diffusion Models (LDMs) in 2D and 3D. Our approach generates anatomically coherent, high fidelity synthetic images that closely mimic real scans and provide valuable resources for training robust diagnostic models. We evaluate generative quality using advanced perceptual and distributional metrics, benchmarking against standard reconstruction methods, and demonstrate substantial gains in diagnostic accuracy on a key classification task. A blinded expert evaluation further validates the clinical realism of our synthetic images. We release our models with privacy safeguards and a comprehensive synthetic uterine MRI dataset to support reproducible research and advance equitable AI in gynaecology.
Audio-Vision Contrastive Learning for Phonological Class Recognition
Jul 23, 2025Accurate classification of articulatory-phonological features plays a vital role in understanding human speech production and developing robust speech technologies, particularly in clinical contexts where targeted phonemic analysis and therapy can improve disease diagnosis accuracy and personalized rehabilitation. In this work, we propose a multimodal deep learning framework that combines real-time magnetic resonance imaging (rtMRI) and speech signals to classify three key articulatory dimensions: manner of articulation, place of articulation, and voicing. We perform classification on 15 phonological classes derived from the aforementioned articulatory dimensions and evaluate the system with four audio/vision configurations: unimodal rtMRI, unimodal audio signals, multimodal middle fusion, and contrastive learning-based audio-vision fusion. Experimental results on the USC-TIMIT dataset show that our contrastive learning-based approach achieves state-of-the-art performance, with an average F1-score of 0.81, representing an absolute increase of 0.23 over the unimodal baseline. The results confirm the effectiveness of contrastive representation learning for multimodal articulatory analysis. Our code and processed dataset will be made publicly available at https://github.com/DaE-plz/AC_Contrastive_Phonology to support future research.
Advances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025



Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
Towards contrast- and pathology-agnostic clinical fetal brain MRI segmentation using SynthSeg
Apr 14, 2025



Magnetic resonance imaging (MRI) has played a crucial role in fetal neurodevelopmental research. Structural annotations of MR images are an important step for quantitative analysis of the developing human brain, with Deep learning providing an automated alternative for this otherwise tedious manual process. However, segmentation performances of Convolutional Neural Networks often suffer from domain shift, where the network fails when applied to subjects that deviate from the distribution with which it is trained on. In this work, we aim to train networks capable of automatically segmenting fetal brain MRIs with a wide range of domain shifts pertaining to differences in subject physiology and acquisition environments, in particular shape-based differences commonly observed in pathological cases. We introduce a novel data-driven train-time sampling strategy that seeks to fully exploit the diversity of a given training dataset to enhance the domain generalizability of the trained networks. We adapted our sampler, together with other existing data augmentation techniques, to the SynthSeg framework, a generator that utilizes domain randomization to generate diverse training data, and ran thorough experimentations and ablation studies on a wide range of training/testing data to test the validity of the approaches. Our networks achieved notable improvements in the segmentation quality on testing subjects with intense anatomical abnormalities (p < 1e-4), though at the cost of a slighter decrease in performance in cases with fewer abnormalities. Our work also lays the foundation for future works on creating and adapting data-driven sampling strategies for other training pipelines.
A Speech-to-Video Synthesis Approach Using Spatio-Temporal Diffusion for Vocal Tract MRI
Mar 15, 2025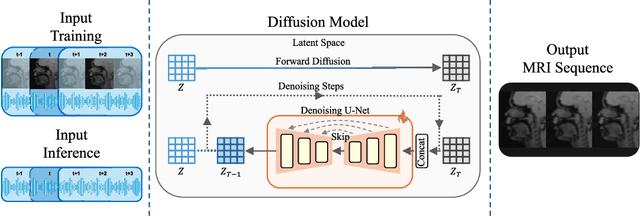
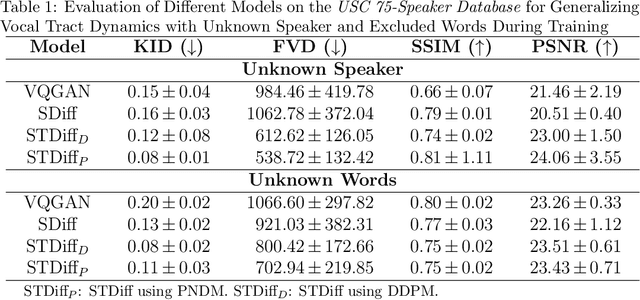
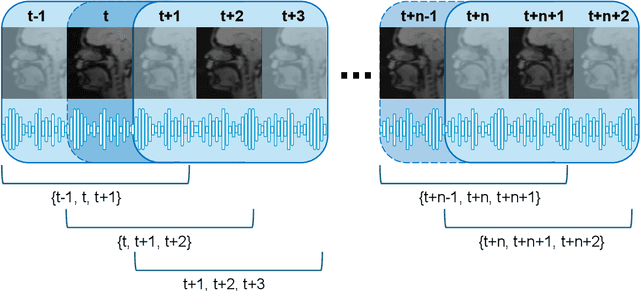

Understanding the relationship between vocal tract motion during speech and the resulting acoustic signal is crucial for aided clinical assessment and developing personalized treatment and rehabilitation strategies. Toward this goal, we introduce an audio-to-video generation framework for creating Real Time/cine-Magnetic Resonance Imaging (RT-/cine-MRI) visuals of the vocal tract from speech signals. Our framework first preprocesses RT-/cine-MRI sequences and speech samples to achieve temporal alignment, ensuring synchronization between visual and audio data. We then employ a modified stable diffusion model, integrating structural and temporal blocks, to effectively capture movement characteristics and temporal dynamics in the synchronized data. This process enables the generation of MRI sequences from new speech inputs, improving the conversion of audio into visual data. We evaluated our framework on healthy controls and tongue cancer patients by analyzing and comparing the vocal tract movements in synthesized videos. Our framework demonstrated adaptability to new speech inputs and effective generalization. In addition, positive human evaluations confirmed its effectiveness, with realistic and accurate visualizations, suggesting its potential for outpatient therapy and personalized simulation of vocal tract visualizations.
Maximizing domain generalization in fetal brain tissue segmentation: the role of synthetic data generation, intensity clustering and real image fine-tuning
Nov 11, 2024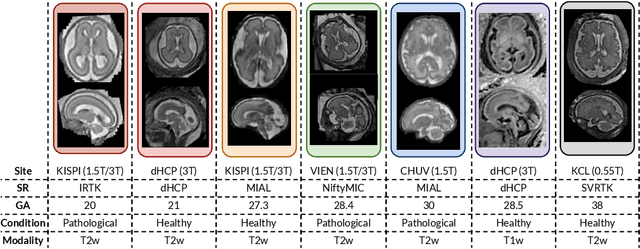
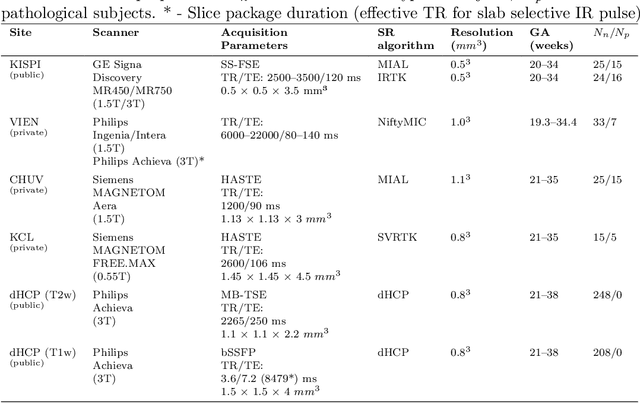
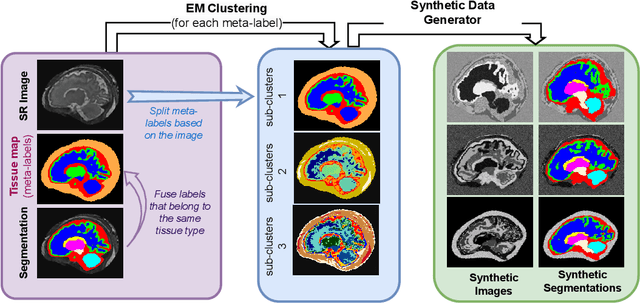
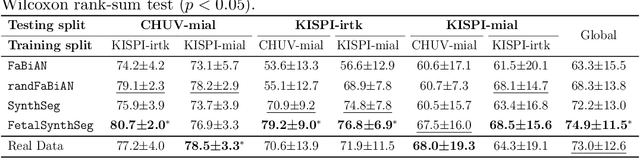
Fetal brain tissue segmentation in magnetic resonance imaging (MRI) is a crucial tool that supports the understanding of neurodevelopment, yet it faces challenges due to the heterogeneity of data coming from different scanners and settings, and due to data scarcity. Recent approaches based on domain randomization, like SynthSeg, have shown a great potential for single source domain generalization, by simulating images with randomized contrast and image resolution from the label maps. In this work, we investigate how to maximize the out-of-domain (OOD) generalization potential of SynthSeg-based methods in fetal brain MRI. Specifically, when studying data generation, we demonstrate that the simple Gaussian mixture models used in SynthSeg enable more robust OOD generalization than physics-informed generation methods. We also investigate how intensity clustering can help create more faithful synthetic images, and observe that it is key to achieving a non-trivial OOD generalization capability when few label classes are available. Finally, by combining for the first time SynthSeg with modern fine-tuning approaches based on weight averaging, we show that fine-tuning a model pre-trained on synthetic data on a few real image-segmentation pairs in a new domain can lead to improvements in the target domain, but also in other domains. We summarize our findings as five key recommendations that we believe can guide practitioners who would like to develop SynthSeg-based approaches in other organs or modalities.