 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Self-Supervised Speech Representations for Cross-lingual Dysarthria Detection in Parkinson's Disease
Mar 23, 2026The limited availability of dysarthric speech data makes cross-lingual detection an important but challenging problem. A key difficulty is that speech representations often encode language-dependent structure that can confound dysarthria detection. We propose a representation-level language shift (LS) that aligns source-language self-supervised speech representations with the target-language distribution using centroid-based vector adaptation estimated from healthy-control speech. We evaluate the approach on oral DDK recordings from Parkinson's disease speech datasets in Czech, German, and Spanish under both cross-lingual and multilingual settings. LS substantially improves sensitivity and F1 in cross-lingual settings, while yielding smaller but consistent gains in multilingual settings. Representation analysis further shows that LS reduces language identity in the embedding space, supporting the interpretation that LS removes language-dependent structure.
Physics-informed GNN for medium-high voltage AC power flow with edge-aware attention and line search correction operator
Sep 26, 2025Physics-informed graph neural networks (PIGNNs) have emerged as fast AC power-flow solvers that can replace classic Newton--Raphson (NR) solvers, especially when thousands of scenarios must be evaluated. However, current PIGNNs still need accuracy improvements at parity speed; in particular, the physics loss is inoperative at inference, which can deter operational adoption. We address this with PIGNN-Attn-LS, combining an edge-aware attention mechanism that explicitly encodes line physics via per-edge biases, capturing the grid's anisotropy, with a backtracking line-search-based globalized correction operator that restores an operative decrease criterion at inference. Training and testing use a realistic High-/Medium-Voltage scenario generator, with NR used only to construct reference states. On held-out HV cases consisting of 4--32-bus grids, PIGNN-Attn-LS achieves a test RMSE of 0.00033 p.u. in voltage and 0.08$^\circ$ in angle, outperforming the PIGNN-MLP baseline by 99.5\% and 87.1\%, respectively. With streaming micro-batches, it delivers 2--5$\times$ faster batched inference than NR on 4--1024-bus grids.
Water Demand Forecasting of District Metered Areas through Learned Consumer Representations
Sep 09, 2025Advancements in smart metering technologies have significantly improved the ability to monitor and manage water utilities. In the context of increasing uncertainty due to climate change, securing water resources and supply has emerged as an urgent global issue with extensive socioeconomic ramifications. Hourly consumption data from end-users have yielded substantial insights for projecting demand across regions characterized by diverse consumption patterns. Nevertheless, the prediction of water demand remains challenging due to influencing non-deterministic factors, such as meteorological conditions. This work introduces a novel method for short-term water demand forecasting for District Metered Areas (DMAs) which encompass commercial, agricultural, and residential consumers. Unsupervised contrastive learning is applied to categorize end-users according to distinct consumption behaviors present within a DMA. Subsequently, the distinct consumption behaviors are utilized as features in the ensuing demand forecasting task using wavelet-transformed convolutional networks that incorporate a cross-attention mechanism combining both historical data and the derived representations. The proposed approach is evaluated on real-world DMAs over a six-month period, demonstrating improved forecasting performance in terms of MAPE across different DMAs, with a maximum improvement of 4.9%. Additionally, it identifies consumers whose behavior is shaped by socioeconomic factors, enhancing prior knowledge about the deterministic patterns that influence demand.
Audio-Vision Contrastive Learning for Phonological Class Recognition
Jul 23, 2025Accurate classification of articulatory-phonological features plays a vital role in understanding human speech production and developing robust speech technologies, particularly in clinical contexts where targeted phonemic analysis and therapy can improve disease diagnosis accuracy and personalized rehabilitation. In this work, we propose a multimodal deep learning framework that combines real-time magnetic resonance imaging (rtMRI) and speech signals to classify three key articulatory dimensions: manner of articulation, place of articulation, and voicing. We perform classification on 15 phonological classes derived from the aforementioned articulatory dimensions and evaluate the system with four audio/vision configurations: unimodal rtMRI, unimodal audio signals, multimodal middle fusion, and contrastive learning-based audio-vision fusion. Experimental results on the USC-TIMIT dataset show that our contrastive learning-based approach achieves state-of-the-art performance, with an average F1-score of 0.81, representing an absolute increase of 0.23 over the unimodal baseline. The results confirm the effectiveness of contrastive representation learning for multimodal articulatory analysis. Our code and processed dataset will be made publicly available at https://github.com/DaE-plz/AC_Contrastive_Phonology to support future research.
A Speech-to-Video Synthesis Approach Using Spatio-Temporal Diffusion for Vocal Tract MRI
Mar 15, 2025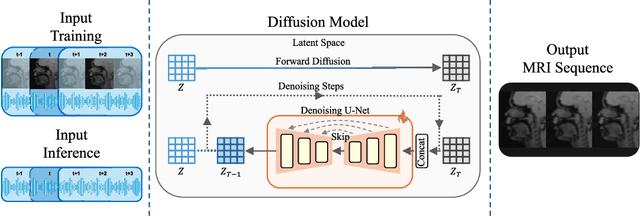
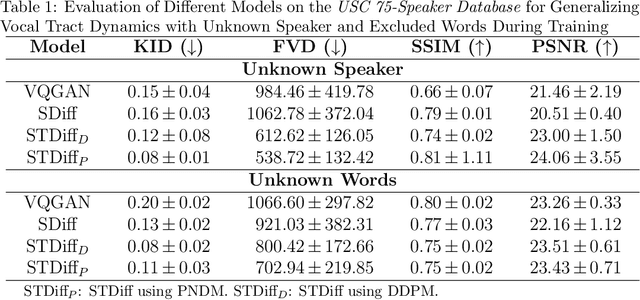
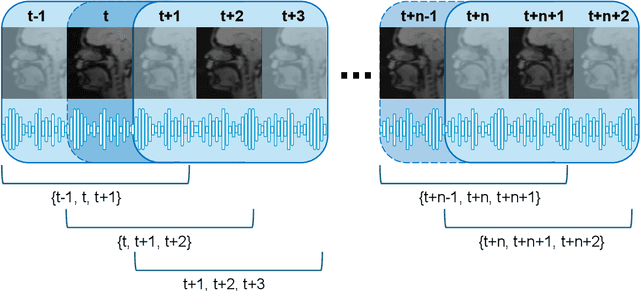

Understanding the relationship between vocal tract motion during speech and the resulting acoustic signal is crucial for aided clinical assessment and developing personalized treatment and rehabilitation strategies. Toward this goal, we introduce an audio-to-video generation framework for creating Real Time/cine-Magnetic Resonance Imaging (RT-/cine-MRI) visuals of the vocal tract from speech signals. Our framework first preprocesses RT-/cine-MRI sequences and speech samples to achieve temporal alignment, ensuring synchronization between visual and audio data. We then employ a modified stable diffusion model, integrating structural and temporal blocks, to effectively capture movement characteristics and temporal dynamics in the synchronized data. This process enables the generation of MRI sequences from new speech inputs, improving the conversion of audio into visual data. We evaluated our framework on healthy controls and tongue cancer patients by analyzing and comparing the vocal tract movements in synthesized videos. Our framework demonstrated adaptability to new speech inputs and effective generalization. In addition, positive human evaluations confirmed its effectiveness, with realistic and accurate visualizations, suggesting its potential for outpatient therapy and personalized simulation of vocal tract visualizations.
Common Phone: A Multilingual Dataset for Robust Acoustic Modelling
Jan 31, 2022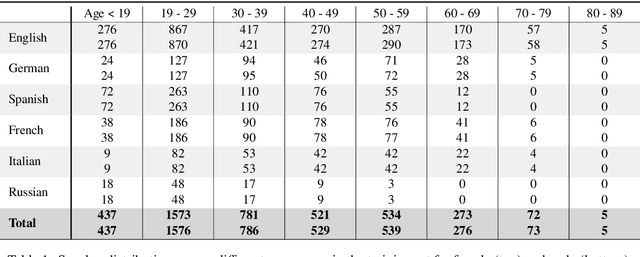
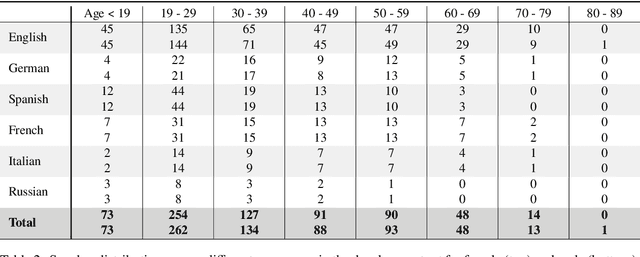
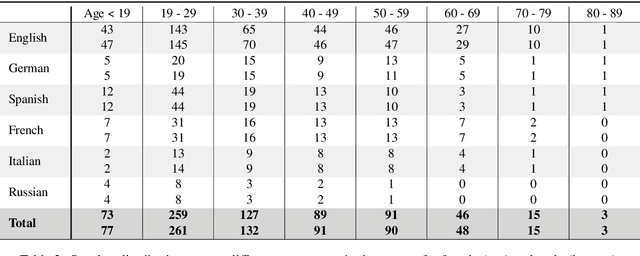
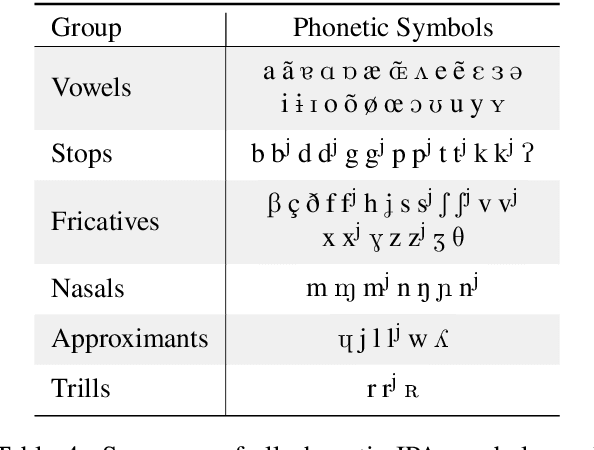
Current state of the art acoustic models can easily comprise more than 100 million parameters. This growing complexity demands larger training datasets to maintain a decent generalization of the final decision function. An ideal dataset is not necessarily large in size, but large with respect to the amount of unique speakers, utilized hardware and varying recording conditions. This enables a machine learning model to explore as much of the domain-specific input space as possible during parameter estimation. This work introduces Common Phone, a gender-balanced, multilingual corpus recorded from more than 11.000 contributors via Mozilla's Common Voice project. It comprises around 116 hours of speech enriched with automatically generated phonetic segmentation. A Wav2Vec 2.0 acoustic model was trained with the Common Phone to perform phonetic symbol recognition and validate the quality of the generated phonetic annotation. The architecture achieved a PER of 18.1 % on the entire test set, computed with all 101 unique phonetic symbols, showing slight differences between the individual languages. We conclude that Common Phone provides sufficient variability and reliable phonetic annotation to help bridging the gap between research and application of acoustic models.
The Phonetic Footprint of Parkinson's Disease
Dec 21, 2021
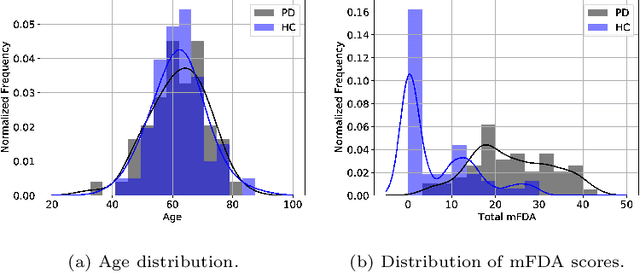
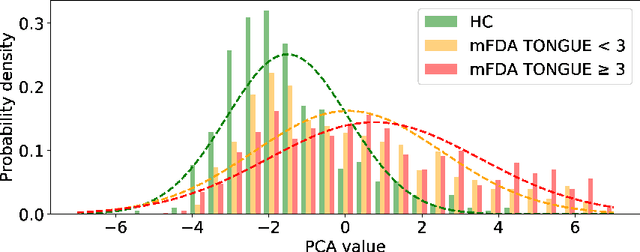
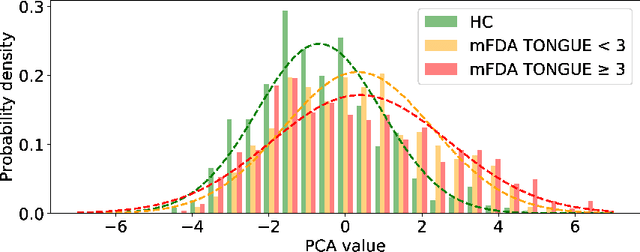
As one of the most prevalent neurodegenerative disorders, Parkinson's disease (PD) has a significant impact on the fine motor skills of patients. The complex interplay of different articulators during speech production and realization of required muscle tension become increasingly difficult, thus leading to a dysarthric speech. Characteristic patterns such as vowel instability, slurred pronunciation and slow speech can often be observed in the affected individuals and were analyzed in previous studies to determine the presence and progression of PD. In this work, we used a phonetic recognizer trained exclusively on healthy speech data to investigate how PD affected the phonetic footprint of patients. We rediscovered numerous patterns that had been described in previous contributions although our system had never seen any pathological speech previously. Furthermore, we could show that intermediate activations from the neural network could serve as feature vectors encoding information related to the disease state of individuals. We were also able to directly correlate the expert-rated intelligibility of a speaker with the mean confidence of phonetic predictions. Our results support the assumption that pathological data is not necessarily required to train systems that are capable of analyzing PD speech.
* https://www.sciencedirect.com/science/article/abs/pii/S0885230821001169