 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Phonological Feature Recognition with Self-Supervised Speech Models
May 25, 2026Phonological features provide a language-general and linguistically grounded representation of speech. We present PhonoQ-2.0, a multilingual frame-level phonological feature recognizer built on self-supervised speech models. The system directly predicts a structured 22-dimensional feature vector per frame encoding manner, vowel quality, place, and voicing, instead of deriving features from phoneme outputs. To ensure phonologically coherent predictions, we introduce a manner-conditioned gating mechanism that activates valid feature groups. Evaluated across multiple languages and corpora, PhonoQ-2.0 achieves an average macro-F1 of 91.3% in-domain and 88.9% out-of-domain. Compared to a strong CTC phoneme baseline, it delivers consistent gains of +8.8 F1 in-domain and +8.6 out-of-domain on average. In unseen-language evaluation, PhonoQ-2.0 improves macro-F1 from 66.9% to 73.6% (+6.7 on average), with gains of up to +10.8 points.
Speech-Guided Multimodal Learning for Vocal Tract Segmentation in Real-Time MRI
May 18, 2026Segmenting vocal tract articulators in real-time MRI (rtMRI) is a challenging dynamic image segmentation problem characterized by low contrast, rapid motion, and limited spatial resolution. However, while rtMRI acquisitions may provide synchronized acoustic signals, existing methods discard this information, and the few multimodal approaches that incorporate audio cannot be deployed when audio is unavailable. We propose a three-stage framework that leverages acoustic and phonological supervision during training while requiring only the rtMRI image at inference: phonological representations are converted into spatial bounding-box priors for articulator localization, visual and acoustic encoders are aligned via dual-level cross-modal contrastive pretraining, and the learned representations are fused through a cross-attention decoder, effectively transferring multimodal knowledge into a single-modality inference pipeline. Evaluated on 75-Speaker~Annot-16 and USC-TIMIT datasets, our method outperforms existing unimodal and multimodal methods, demonstrating that multimodal supervision provides transferable benefits for precise and clinically deployable vocal tract segmentation.
Bias and Fairness in Self-Supervised Acoustic Representations for Cognitive Impairment Detection
Mar 03, 2026Speech-based detection of cognitive impairment (CI) offers a promising non-invasive approach for early diagnosis, yet performance disparities across demographic and clinical subgroups remain underexplored, raising concerns around fairness and generalizability. This study presents a systematic bias analysis of acoustic-based CI and depression classification using the DementiaBank Pitt Corpus. We compare traditional acoustic features (MFCCs, eGeMAPS) with contextualized speech embeddings from Wav2Vec 2.0 (W2V2), and evaluate classification performance across gender, age, and depression-status subgroups. For CI detection, higher-layer W2V2 embeddings outperform baseline features (UAR up to 80.6\%), but exhibit performance disparities; specifically, females and younger participants demonstrate lower discriminative power (\(AUC\): 0.769 and 0.746, respectively) and substantial specificity disparities (\(Δ_{spec}\) up to 18\% and 15\%, respectively), leading to a higher risk of misclassifications than their counterparts. These disparities reflect representational biases, defined as systematic differences in model performance across demographic or clinical subgroups. Depression detection within CI subjects yields lower overall performance, with mild improvements from low and mid-level W2V2 layers. Cross-task generalization between CI and depression classification is limited, indicating that each task depends on distinct representations. These findings emphasize the need for fairness-aware model evaluation and subgroup-specific analysis in clinical speech applications, particularly in light of demographic and clinical heterogeneity in real-world applications.
Audio-Vision Contrastive Learning for Phonological Class Recognition
Jul 23, 2025Accurate classification of articulatory-phonological features plays a vital role in understanding human speech production and developing robust speech technologies, particularly in clinical contexts where targeted phonemic analysis and therapy can improve disease diagnosis accuracy and personalized rehabilitation. In this work, we propose a multimodal deep learning framework that combines real-time magnetic resonance imaging (rtMRI) and speech signals to classify three key articulatory dimensions: manner of articulation, place of articulation, and voicing. We perform classification on 15 phonological classes derived from the aforementioned articulatory dimensions and evaluate the system with four audio/vision configurations: unimodal rtMRI, unimodal audio signals, multimodal middle fusion, and contrastive learning-based audio-vision fusion. Experimental results on the USC-TIMIT dataset show that our contrastive learning-based approach achieves state-of-the-art performance, with an average F1-score of 0.81, representing an absolute increase of 0.23 over the unimodal baseline. The results confirm the effectiveness of contrastive representation learning for multimodal articulatory analysis. Our code and processed dataset will be made publicly available at https://github.com/DaE-plz/AC_Contrastive_Phonology to support future research.
Towards Inclusive ASR: Investigating Voice Conversion for Dysarthric Speech Recognition in Low-Resource Languages
May 20, 2025Automatic speech recognition (ASR) for dysarthric speech remains challenging due to data scarcity, particularly in non-English languages. To address this, we fine-tune a voice conversion model on English dysarthric speech (UASpeech) to encode both speaker characteristics and prosodic distortions, then apply it to convert healthy non-English speech (FLEURS) into non-English dysarthric-like speech. The generated data is then used to fine-tune a multilingual ASR model, Massively Multilingual Speech (MMS), for improved dysarthric speech recognition. Evaluation on PC-GITA (Spanish), EasyCall (Italian), and SSNCE (Tamil) demonstrates that VC with both speaker and prosody conversion significantly outperforms the off-the-shelf MMS performance and conventional augmentation techniques such as speed and tempo perturbation. Objective and subjective analyses of the generated data further confirm that the generated speech simulates dysarthric characteristics.
A Speech-to-Video Synthesis Approach Using Spatio-Temporal Diffusion for Vocal Tract MRI
Mar 15, 2025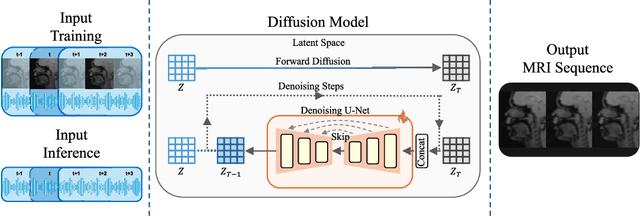
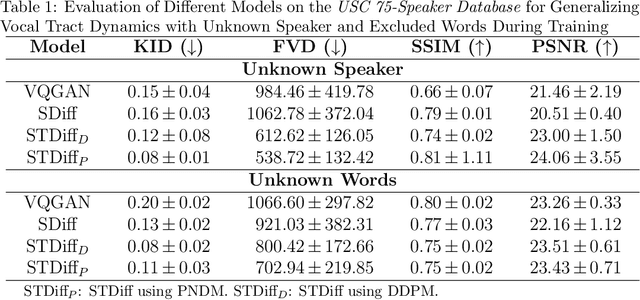
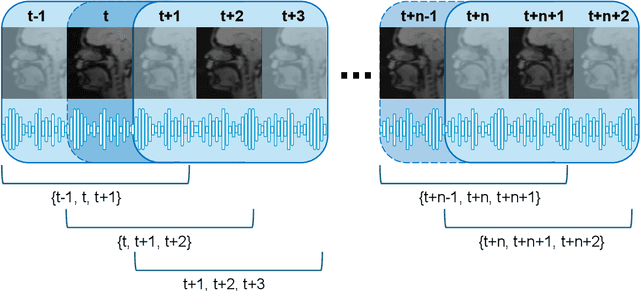

Understanding the relationship between vocal tract motion during speech and the resulting acoustic signal is crucial for aided clinical assessment and developing personalized treatment and rehabilitation strategies. Toward this goal, we introduce an audio-to-video generation framework for creating Real Time/cine-Magnetic Resonance Imaging (RT-/cine-MRI) visuals of the vocal tract from speech signals. Our framework first preprocesses RT-/cine-MRI sequences and speech samples to achieve temporal alignment, ensuring synchronization between visual and audio data. We then employ a modified stable diffusion model, integrating structural and temporal blocks, to effectively capture movement characteristics and temporal dynamics in the synchronized data. This process enables the generation of MRI sequences from new speech inputs, improving the conversion of audio into visual data. We evaluated our framework on healthy controls and tongue cancer patients by analyzing and comparing the vocal tract movements in synthesized videos. Our framework demonstrated adaptability to new speech inputs and effective generalization. In addition, positive human evaluations confirmed its effectiveness, with realistic and accurate visualizations, suggesting its potential for outpatient therapy and personalized simulation of vocal tract visualizations.
Speaker- and Text-Independent Estimation of Articulatory Movements and Phoneme Alignments from Speech
Jul 03, 2024This paper introduces a novel combination of two tasks, previously treated separately: acoustic-to-articulatory speech inversion (AAI) and phoneme-to-articulatory (PTA) motion estimation. We refer to this joint task as acoustic phoneme-to-articulatory speech inversion (APTAI) and explore two different approaches, both working speaker- and text-independently during inference. We use a multi-task learning setup, with the end-to-end goal of taking raw speech as input and estimating the corresponding articulatory movements, phoneme sequence, and phoneme alignment. While both proposed approaches share these same requirements, they differ in their way of achieving phoneme-related predictions: one is based on frame classification, the other on a two-staged training procedure and forced alignment. We reach competitive performance of 0.73 mean correlation for the AAI task and achieve up to approximately 87% frame overlap compared to a state-of-the-art text-dependent phoneme force aligner.
Self-Supervised Speech Representations Preserve Speech Characteristics while Anonymizing Voices
Apr 04, 2022
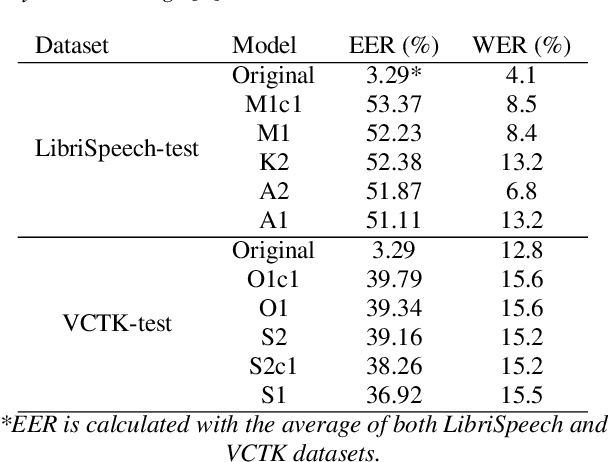

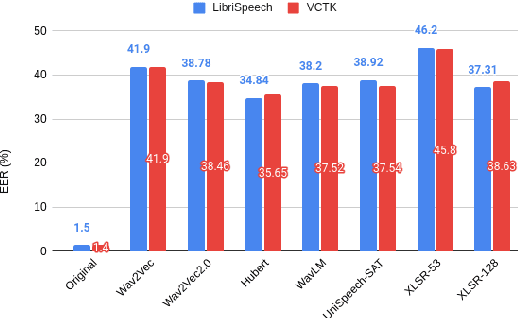
Collecting speech data is an important step in training speech recognition systems and other speech-based machine learning models. However, the issue of privacy protection is an increasing concern that must be addressed. The current study investigates the use of voice conversion as a method for anonymizing voices. In particular, we train several voice conversion models using self-supervised speech representations including Wav2Vec2.0, Hubert and UniSpeech. Converted voices retain a low word error rate within 1% of the original voice. Equal error rate increases from 1.52% to 46.24% on the LibriSpeech test set and from 3.75% to 45.84% on speakers from the VCTK corpus which signifies degraded performance on speaker verification. Lastly, we conduct experiments on dysarthric speech data to show that speech features relevant to articulation, prosody, phonation and phonology can be extracted from anonymized voices for discriminating between healthy and pathological speech.
Cross-lingual Self-Supervised Speech Representations for Improved Dysarthric Speech Recognition
Apr 04, 2022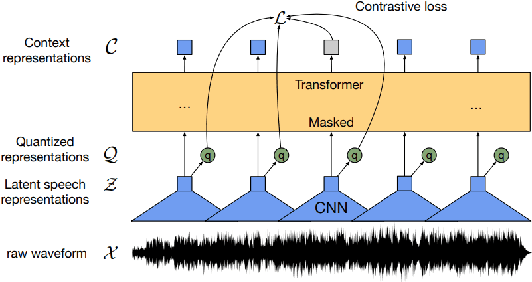

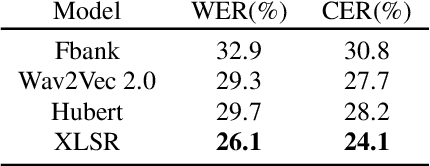
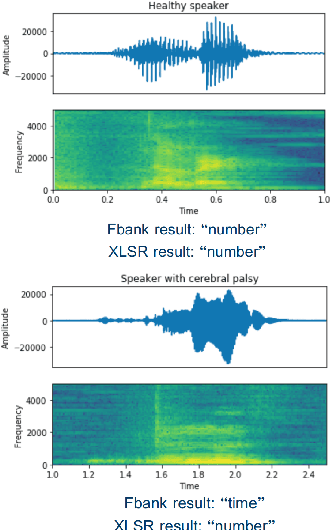
State-of-the-art automatic speech recognition (ASR) systems perform well on healthy speech. However, the performance on impaired speech still remains an issue. The current study explores the usefulness of using Wav2Vec self-supervised speech representations as features for training an ASR system for dysarthric speech. Dysarthric speech recognition is particularly difficult as several aspects of speech such as articulation, prosody and phonation can be impaired. Specifically, we train an acoustic model with features extracted from Wav2Vec, Hubert, and the cross-lingual XLSR model. Results suggest that speech representations pretrained on large unlabelled data can improve word error rate (WER) performance. In particular, features from the multilingual model led to lower WERs than filterbanks (Fbank) or models trained on a single language. Improvements were observed in English speakers with cerebral palsy caused dysarthria (UASpeech corpus), Spanish speakers with Parkinsonian dysarthria (PC-GITA corpus) and Italian speakers with paralysis-based dysarthria (EasyCall corpus). Compared to using Fbank features, XLSR-based features reduced WERs by 6.8%, 22.0%, and 7.0% for the UASpeech, PC-GITA, and EasyCall corpus, respectively.
Common Phone: A Multilingual Dataset for Robust Acoustic Modelling
Jan 31, 2022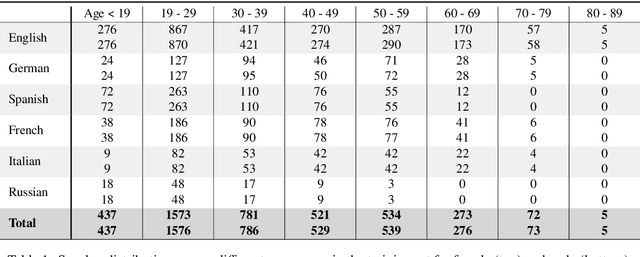
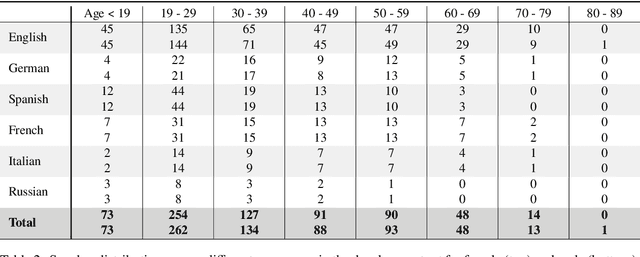
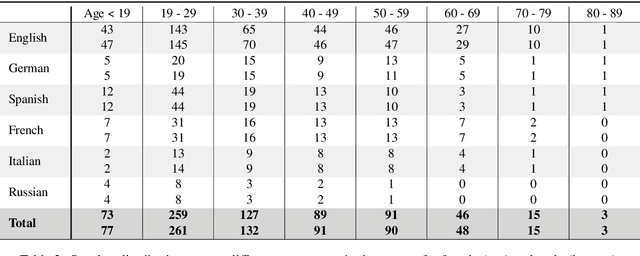
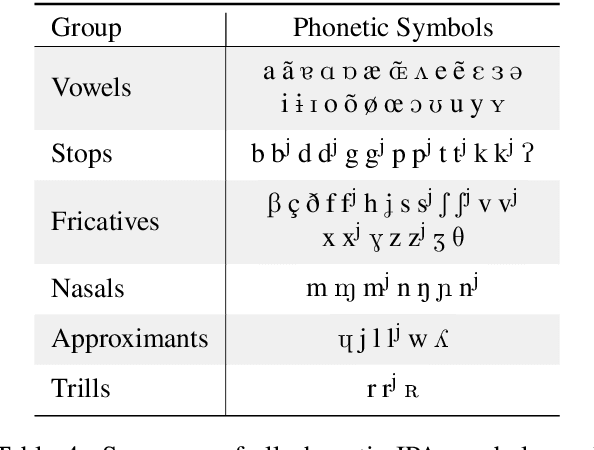
Current state of the art acoustic models can easily comprise more than 100 million parameters. This growing complexity demands larger training datasets to maintain a decent generalization of the final decision function. An ideal dataset is not necessarily large in size, but large with respect to the amount of unique speakers, utilized hardware and varying recording conditions. This enables a machine learning model to explore as much of the domain-specific input space as possible during parameter estimation. This work introduces Common Phone, a gender-balanced, multilingual corpus recorded from more than 11.000 contributors via Mozilla's Common Voice project. It comprises around 116 hours of speech enriched with automatically generated phonetic segmentation. A Wav2Vec 2.0 acoustic model was trained with the Common Phone to perform phonetic symbol recognition and validate the quality of the generated phonetic annotation. The architecture achieved a PER of 18.1 % on the entire test set, computed with all 101 unique phonetic symbols, showing slight differences between the individual languages. We conclude that Common Phone provides sufficient variability and reliable phonetic annotation to help bridging the gap between research and application of acoustic models.