 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Implications of Automatic Anonymization in Pathological Speech
May 01, 2025Automatic anonymization techniques are essential for ethical sharing of pathological speech data, yet their perceptual consequences remain understudied. This study presents the first comprehensive human-centered analysis of anonymized pathological speech, using a structured perceptual protocol involving ten native and non-native German listeners with diverse linguistic, clinical, and technical backgrounds. Listeners evaluated anonymized-original utterance pairs from 180 speakers spanning Cleft Lip and Palate, Dysarthria, Dysglossia, Dysphonia, and age-matched healthy controls. Speech was anonymized using state-of-the-art automatic methods (equal error rates in the range of 30-40%). Listeners completed Turing-style discrimination and quality rating tasks under zero-shot (single-exposure) and few-shot (repeated-exposure) conditions. Discrimination accuracy was high overall (91% zero-shot; 93% few-shot), but varied by disorder (repeated-measures ANOVA: p=0.007), ranging from 96% (Dysarthria) to 86% (Dysphonia). Anonymization consistently reduced perceived quality (from 83% to 59%, p<0.001), with pathology-specific degradation patterns (one-way ANOVA: p=0.005). Native listeners rated original speech slightly higher than non-native listeners (Delta=4%, p=0.199), but this difference nearly disappeared after anonymization (Delta=1%, p=0.724). No significant gender-based bias was observed. Critically, human perceptual outcomes did not correlate with automatic privacy or clinical utility metrics. These results underscore the need for listener-informed, disorder- and context-specific anonymization strategies that preserve privacy while maintaining interpretability, communicative functions, and diagnostic utility, especially for vulnerable populations such as children.
Speaker- and Text-Independent Estimation of Articulatory Movements and Phoneme Alignments from Speech
Jul 03, 2024This paper introduces a novel combination of two tasks, previously treated separately: acoustic-to-articulatory speech inversion (AAI) and phoneme-to-articulatory (PTA) motion estimation. We refer to this joint task as acoustic phoneme-to-articulatory speech inversion (APTAI) and explore two different approaches, both working speaker- and text-independently during inference. We use a multi-task learning setup, with the end-to-end goal of taking raw speech as input and estimating the corresponding articulatory movements, phoneme sequence, and phoneme alignment. While both proposed approaches share these same requirements, they differ in their way of achieving phoneme-related predictions: one is based on frame classification, the other on a two-staged training procedure and forced alignment. We reach competitive performance of 0.73 mean correlation for the AAI task and achieve up to approximately 87% frame overlap compared to a state-of-the-art text-dependent phoneme force aligner.
The Impact of Speech Anonymization on Pathology and Its Limits
Apr 11, 2024Integration of speech into healthcare has intensified privacy concerns due to its potential as a non-invasive biomarker containing individual biometric information. In response, speaker anonymization aims to conceal personally identifiable information while retaining crucial linguistic content. However, the application of anonymization techniques to pathological speech, a critical area where privacy is especially vital, has not been extensively examined. This study investigates anonymization's impact on pathological speech across over 2,700 speakers from multiple German institutions, focusing on privacy, pathological utility, and demographic fairness. We explore both training-based and signal processing-based anonymization methods, and document substantial privacy improvements across disorders-evidenced by equal error rate increases up to 1933%, with minimal overall impact on utility. Specific disorders such as Dysarthria, Dysphonia, and Cleft Lip and Palate experienced minimal utility changes, while Dysglossia showed slight improvements. Our findings underscore that the impact of anonymization varies substantially across different disorders. This necessitates disorder-specific anonymization strategies to optimally balance privacy with diagnostic utility. Additionally, our fairness analysis revealed consistent anonymization effects across most of the demographics. This study demonstrates the effectiveness of anonymization in pathological speech for enhancing privacy, while also highlighting the importance of customized approaches to account for inversion attacks.
Federated learning for secure development of AI models for Parkinson's disease detection using speech from different languages
May 18, 2023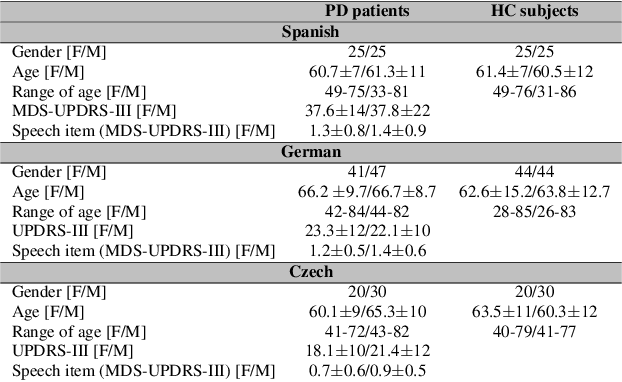
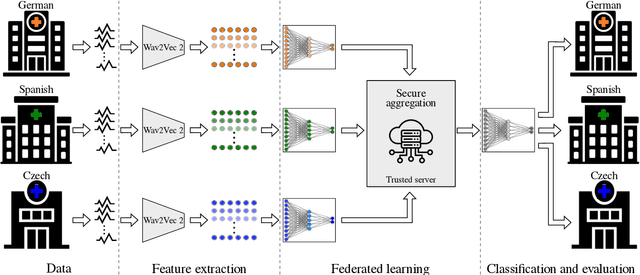
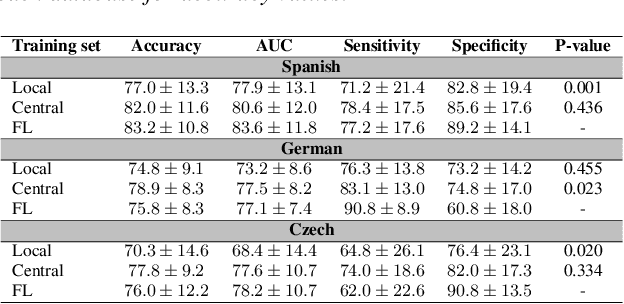
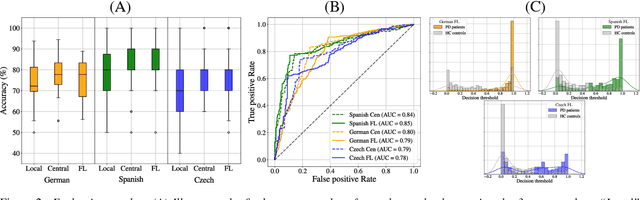
Parkinson's disease (PD) is a neurological disorder impacting a person's speech. Among automatic PD assessment methods, deep learning models have gained particular interest. Recently, the community has explored cross-pathology and cross-language models which can improve diagnostic accuracy even further. However, strict patient data privacy regulations largely prevent institutions from sharing patient speech data with each other. In this paper, we employ federated learning (FL) for PD detection using speech signals from 3 real-world language corpora of German, Spanish, and Czech, each from a separate institution. Our results indicate that the FL model outperforms all the local models in terms of diagnostic accuracy, while not performing very differently from the model based on centrally combined training sets, with the advantage of not requiring any data sharing among collaborators. This will simplify inter-institutional collaborations, resulting in enhancement of patient outcomes.
Disentangled Latent Speech Representation for Automatic Pathological Intelligibility Assessment
Apr 08, 2022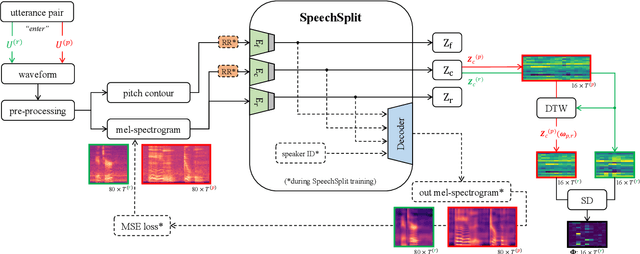
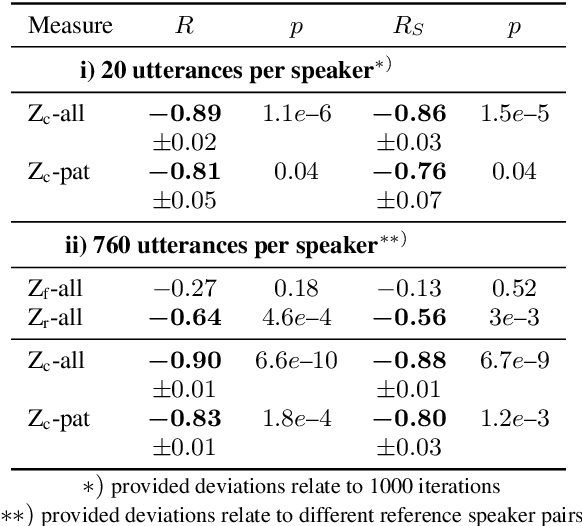
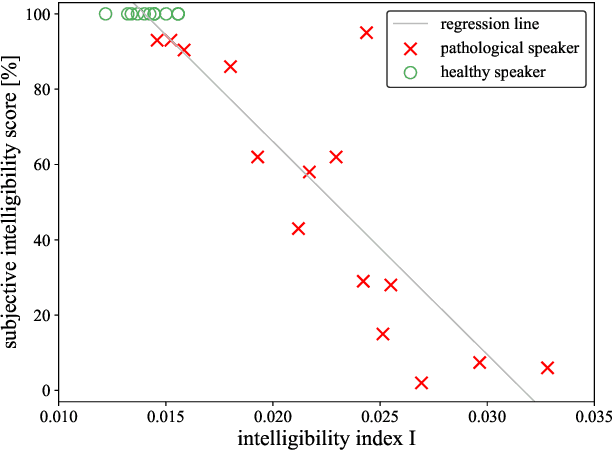
Speech intelligibility assessment plays an important role in the therapy of patients suffering from pathological speech disorders. Automatic and objective measures are desirable to assist therapists in their traditionally subjective and labor-intensive assessments. In this work, we investigate a novel approach for obtaining such a measure using the divergence in disentangled latent speech representations of a parallel utterance pair, obtained from a healthy reference and a pathological speaker. Experiments on an English database of Cerebral Palsy patients, using all available utterances per speaker, show high and significant correlation values (R = -0.9) with subjective intelligibility measures, while having only minimal deviation (+-0.01) across four different reference speaker pairs. We also demonstrate the robustness of the proposed method (R = -0.89 deviating +-0.02 over 1000 iterations) by considering a significantly smaller amount of utterances per speaker. Our results are among the first to show that disentangled speech representations can be used for automatic pathological speech intelligibility assessment, resulting in a reference speaker pair invariant method, applicable in scenarios with only few utterances available.
Semantic Processing of Out-Of-Vocabulary Words in a Spoken Dialogue System
Sep 17, 1997

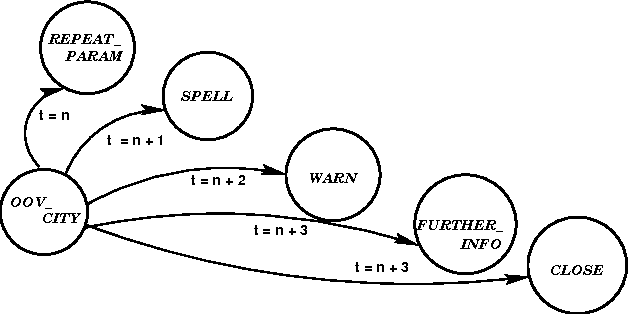
One of the most important causes of failure in spoken dialogue systems is usually neglected: the problem of words that are not covered by the system's vocabulary (out-of-vocabulary or OOV words). In this paper a methodology is described for the detection, classification and processing of OOV words in an automatic train timetable information system. The various extensions that had to be effected on the different modules of the system are reported, resulting in the design of appropriate dialogue strategies, as are encouraging evaluation results on the new versions of the word recogniser and the linguistic processor.
* 4 pages, 2 eps figures, requires LaTeX2e, uses eurospeech.sty and epsfig
Integrating Syntactic and Prosodic Information for the Efficient Detection of Empty Categories
Jul 02, 1996


We describe a number of experiments that demonstrate the usefulness of prosodic information for a processing module which parses spoken utterances with a feature-based grammar employing empty categories. We show that by requiring certain prosodic properties from those positions in the input where the presence of an empty category has to be hypothesized, a derivation can be accomplished more efficiently. The approach has been implemented in the machine translation project VERBMOBIL and results in a significant reduction of the work-load for the parser.