 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Implications of Automatic Anonymization in Pathological Speech
May 01, 2025Automatic anonymization techniques are essential for ethical sharing of pathological speech data, yet their perceptual consequences remain understudied. This study presents the first comprehensive human-centered analysis of anonymized pathological speech, using a structured perceptual protocol involving ten native and non-native German listeners with diverse linguistic, clinical, and technical backgrounds. Listeners evaluated anonymized-original utterance pairs from 180 speakers spanning Cleft Lip and Palate, Dysarthria, Dysglossia, Dysphonia, and age-matched healthy controls. Speech was anonymized using state-of-the-art automatic methods (equal error rates in the range of 30-40%). Listeners completed Turing-style discrimination and quality rating tasks under zero-shot (single-exposure) and few-shot (repeated-exposure) conditions. Discrimination accuracy was high overall (91% zero-shot; 93% few-shot), but varied by disorder (repeated-measures ANOVA: p=0.007), ranging from 96% (Dysarthria) to 86% (Dysphonia). Anonymization consistently reduced perceived quality (from 83% to 59%, p<0.001), with pathology-specific degradation patterns (one-way ANOVA: p=0.005). Native listeners rated original speech slightly higher than non-native listeners (Delta=4%, p=0.199), but this difference nearly disappeared after anonymization (Delta=1%, p=0.724). No significant gender-based bias was observed. Critically, human perceptual outcomes did not correlate with automatic privacy or clinical utility metrics. These results underscore the need for listener-informed, disorder- and context-specific anonymization strategies that preserve privacy while maintaining interpretability, communicative functions, and diagnostic utility, especially for vulnerable populations such as children.
Differential privacy for protecting patient data in speech disorder detection using deep learning
Sep 27, 2024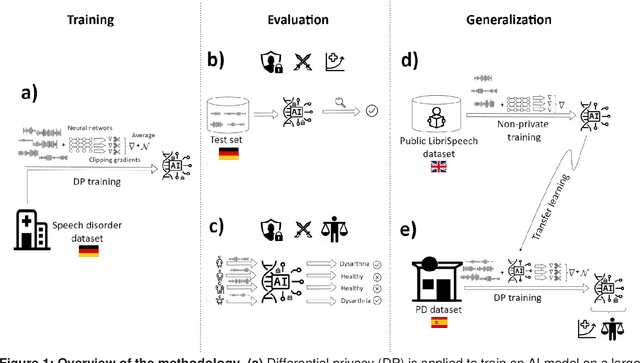
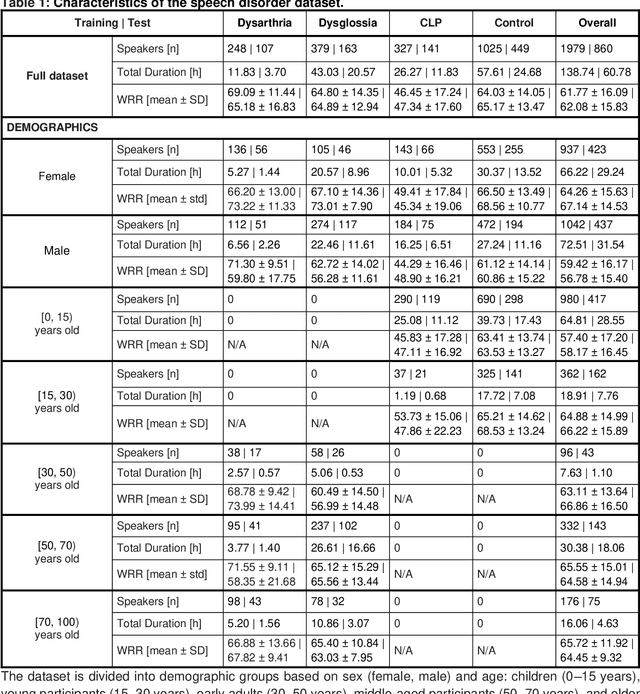
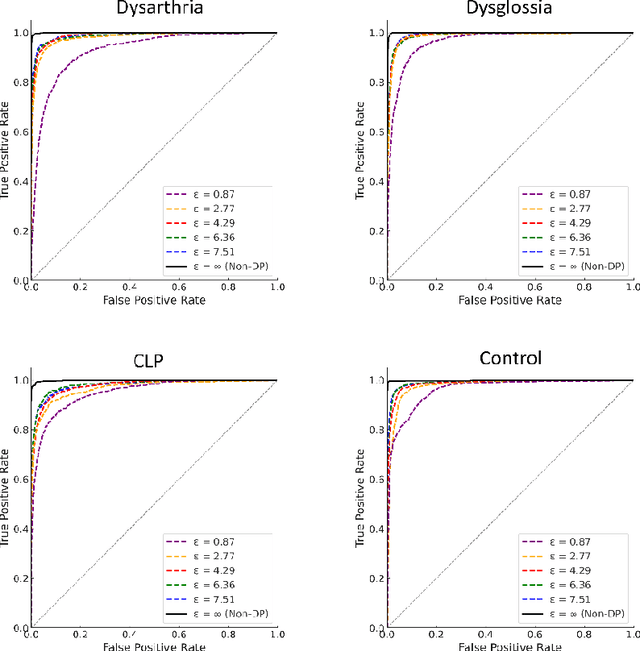
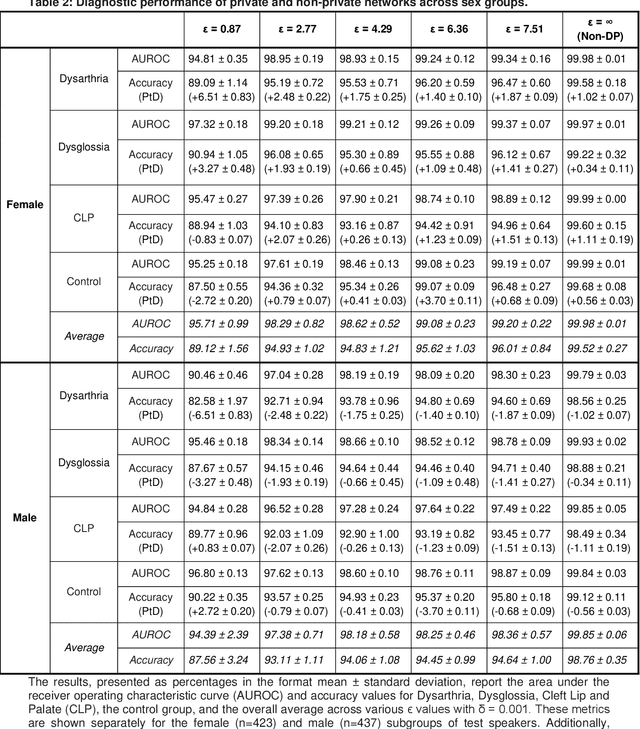
Speech pathology has impacts on communication abilities and quality of life. While deep learning-based models have shown potential in diagnosing these disorders, the use of sensitive data raises critical privacy concerns. Although differential privacy (DP) has been explored in the medical imaging domain, its application in pathological speech analysis remains largely unexplored despite the equally critical privacy concerns. This study is the first to investigate DP's impact on pathological speech data, focusing on the trade-offs between privacy, diagnostic accuracy, and fairness. Using a large, real-world dataset of 200 hours of recordings from 2,839 German-speaking participants, we observed a maximum accuracy reduction of 3.85% when training with DP with a privacy budget, denoted by {\epsilon}, of 7.51. To generalize our findings, we validated our approach on a smaller dataset of Spanish-speaking Parkinson's disease patients, demonstrating that careful pretraining on large-scale task-specific datasets can maintain or even improve model accuracy under DP constraints. We also conducted a comprehensive fairness analysis, revealing that reasonable privacy levels (2<{\epsilon}<10) do not introduce significant gender bias, though age-related disparities may require further attention. Our results suggest that DP can effectively balance privacy and utility in speech disorder detection, but also highlight the unique challenges in the speech domain, particularly regarding the privacy-fairness trade-off. This provides a foundation for future work to refine DP methodologies and address fairness across diverse patient groups in real-world deployments.
SNOBERT: A Benchmark for clinical notes entity linking in the SNOMED CT clinical terminology
May 25, 2024The extraction and analysis of insights from medical data, primarily stored in free-text formats by healthcare workers, presents significant challenges due to its unstructured nature. Medical coding, a crucial process in healthcare, remains minimally automated due to the complexity of medical ontologies and restricted access to medical texts for training Natural Language Processing models. In this paper, we proposed a method, "SNOBERT," of linking text spans in clinical notes to specific concepts in the SNOMED CT using BERT-based models. The method consists of two stages: candidate selection and candidate matching. The models were trained on one of the largest publicly available dataset of labeled clinical notes. SNOBERT outperforms other classical methods based on deep learning, as confirmed by the results of a challenge in which it was applied.
The Impact of Speech Anonymization on Pathology and Its Limits
Apr 11, 2024Integration of speech into healthcare has intensified privacy concerns due to its potential as a non-invasive biomarker containing individual biometric information. In response, speaker anonymization aims to conceal personally identifiable information while retaining crucial linguistic content. However, the application of anonymization techniques to pathological speech, a critical area where privacy is especially vital, has not been extensively examined. This study investigates anonymization's impact on pathological speech across over 2,700 speakers from multiple German institutions, focusing on privacy, pathological utility, and demographic fairness. We explore both training-based and signal processing-based anonymization methods, and document substantial privacy improvements across disorders-evidenced by equal error rate increases up to 1933%, with minimal overall impact on utility. Specific disorders such as Dysarthria, Dysphonia, and Cleft Lip and Palate experienced minimal utility changes, while Dysglossia showed slight improvements. Our findings underscore that the impact of anonymization varies substantially across different disorders. This necessitates disorder-specific anonymization strategies to optimally balance privacy with diagnostic utility. Additionally, our fairness analysis revealed consistent anonymization effects across most of the demographics. This study demonstrates the effectiveness of anonymization in pathological speech for enhancing privacy, while also highlighting the importance of customized approaches to account for inversion attacks.