 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-language models for chest radiography do not always need the image
Jun 16, 2026Medical vision-language models report strong chest radiograph accuracy, and this is increasingly read as evidence that they use the image. That inference is unsafe: a model exploiting finding-name priors scores like one that reads the scan, and no standard benchmark separates them. We introduce a causal audit that intervenes on the image, occluding the relevant region, occluding an irrelevant one, and swapping in another patient's same-label scan, and combines three behavioral metrics to test whether a correct answer depends on the image. Across nine systems, a text-only model with no image access reaches within 5.7 accuracy points of the best multimodal one, and a 119-billion-parameter multimodal model is statistically indistinguishable from a 7-billion text-only baseline. The audit splits the cohort into three models that ignore the image, one that is unstable, and five that use it selectively, for a subset of findings; the categories hold across a second dataset, resolution, and prompt phrasing. Against board-certified radiologists, a text-only model is statistically indistinguishable from a radiologist's accuracy while grounding at zero, whereas the image-using models ground at radiologist-comparable rates. Reported confidence flags ungrounded answers only when a model uses the image. Grounding audits, not accuracy, should gate clinical deployment.
Cross-modal linkage risk in clinical vision-language models
Jun 01, 2026Vision-language models (VLMs) trained on paired chest radiographs and radiology reports learn a shared embedding space that can preserve instance-level image-report correspondence. This poses a privacy risk in settings where radiographs and reports are deliberately kept separate after acquisition, such as image-only data sharing or access-controlled reports, because a de-identified image may be re-linked to its original narrative report through cosine similarity alone. We formalized this as image-to-report retrieval and used public paired cohorts, in which the true pairing is known by design, as ground-truth benchmarks to audit the risk rather than as the privacy scenario. Evaluating VLMs of increasing clinical specialization on 406,241 paired examples from 126,804 patients across MIMIC-CXR (43,793 held-out pairs) and external CheXpert Plus (29,296 pairs), we found that re-linkage rose systematically with specialization: the strongest VLM retrieved the correct report at 15 times chance at a candidate pool of N = 100, 50 times chance at N = 10,000, and well above chance at full-database scale. The signal persisted under pathology-matched hard negatives that removed disease-label shortcuts, indicating correspondence beyond broad diagnostic categories. To reduce it without retraining, we froze both encoders and applied differentially private optimization only to the projection heads defining the alignment layer (epsilon = 0.34, delta = 6x10-6). This reduced Recall@1 by 61.8% at N = 10,000 on MIMIC-CXR and transferred to CheXpert Plus without retraining, while image-side utility was largely preserved: macro AUROC for linear-probe classification across 14 labels shifted only from 79.63% to 79.43%. Targeted DP finetuning of the shared alignment layer can substantially reduce cross-modal re-linkage without materially degrading the image representations that make these models clinically useful.
Safety and accuracy follow different scaling laws in clinical large language models
May 05, 2026Clinical LLMs are often scaled by increasing model size, context length, retrieval complexity, or inference-time compute, with the implicit expectation that higher accuracy implies safer behavior. This assumption is incomplete in medicine, where a few confident, high-risk, or evidence-contradicting errors can matter more than average benchmark performance. We introduce SaFE-Scale, a framework for measuring how clinical LLM safety changes across model scale, evidence quality, retrieval strategy, context exposure, and inference-time compute. To instantiate this framework, we introduce RadSaFE-200, a Radiology Safety-Focused Evaluation benchmark of 200 multiple-choice questions with clinician-defined clean evidence, conflict evidence, and option-level labels for high-risk error, unsafe answer, and evidence contradiction. We evaluated 34 locally deployed LLMs across six deployment conditions: closed-book prompting (zero-shot), clean evidence, conflict evidence, standard RAG, agentic RAG, and max-context prompting. Clean evidence produced the strongest improvement, increasing mean accuracy from 73.5% to 94.1%, while reducing high-risk error from 12.0% to 2.6%, contradiction from 12.7% to 2.3%, and dangerous overconfidence from 8.0% to 1.6%. Standard RAG and agentic RAG did not reproduce this safety profile: agentic RAG improved accuracy over standard RAG and reduced contradiction, but high-risk error and dangerous overconfidence remained elevated. Max-context prompting increased latency without closing the safety gap, and additional inference-time compute produced only limited gains. Worst-case analysis showed that clinically consequential errors concentrated in a small subset of questions. Clinical LLM safety is therefore not a passive consequence of scaling, but a deployment property shaped by evidence quality, retrieval design, context construction, and collective failure behavior.
Case-Grounded Evidence Verification: A Framework for Constructing Evidence-Sensitive Supervision
Apr 10, 2026Evidence-grounded reasoning requires more than attaching retrieved text to a prediction: a model should make decisions that depend on whether the provided evidence supports the target claim. In practice, this often fails because supervision is weak, evidence is only loosely tied to the claim, and evaluation does not test evidence dependence directly. We introduce case-grounded evidence verification, a general framework in which a model receives a local case context, external evidence, and a structured claim, and must decide whether the evidence supports the claim for that case. Our key contribution is a supervision construction procedure that generates explicit support examples together with semantically controlled non-support examples, including counterfactual wrong-state and topic-related negatives, without manual evidence annotation. We instantiate the framework in radiology and train a standard verifier on the resulting support task. The learned verifier substantially outperforms both case-only and evidence-only baselines, remains strong under correct evidence, and collapses when evidence is removed or swapped, indicating genuine evidence dependence. This behavior transfers across unseen evidence articles and an external case distribution, though performance degrades under evidence-source shift and remains sensitive to backbone choice. Overall, the results suggest that a major bottleneck in evidence grounding is not only model capacity, but the lack of supervision that encodes the causal role of evidence.
Differential privacy representation geometry for medical image analysis
Mar 01, 2026Differential privacy (DP)'s effect in medical imaging is typically evaluated only through end-to-end performance, leaving the mechanism of privacy-induced utility loss unclear. We introduce Differential Privacy Representation Geometry for Medical Imaging (DP-RGMI), a framework that interprets DP as a structured transformation of representation space and decomposes performance degradation into encoder geometry and task-head utilization. Geometry is quantified by representation displacement from initialization and spectral effective dimension, while utilization is measured as the gap between linear-probe and end-to-end utility. Across over 594,000 images from four chest X-ray datasets and multiple pretrained initializations, we show that DP is consistently associated with a utilization gap even when linear separability is largely preserved. At the same time, displacement and spectral dimension exhibit non-monotonic, initialization- and dataset-dependent reshaping, indicating that DP alters representation anisotropy rather than uniformly collapsing features. Correlation analysis reveals that the association between end-to-end performance and utilization is robust across datasets but can vary by initialization, while geometric quantities capture additional prior- and dataset-conditioned variation. These findings position DP-RGMI as a reproducible framework for diagnosing privacy-induced failure modes and informing privacy model selection.
SteuerLLM: Local specialized large language model for German tax law analysis
Feb 11, 2026Large language models (LLMs) demonstrate strong general reasoning and language understanding, yet their performance degrades in domains governed by strict formal rules, precise terminology, and legally binding structure. Tax law exemplifies these challenges, as correct answers require exact statutory citation, structured legal argumentation, and numerical accuracy under rigid grading schemes. We algorithmically generate SteuerEx, the first open benchmark derived from authentic German university tax law examinations. SteuerEx comprises 115 expert-validated examination questions spanning six core tax law domains and multiple academic levels, and employs a statement-level, partial-credit evaluation framework that closely mirrors real examination practice. We further present SteuerLLM, a domain-adapted LLM for German tax law trained on a large-scale synthetic dataset generated from authentic examination material using a controlled retrieval-augmented pipeline. SteuerLLM (28B parameters) consistently outperforms general-purpose instruction-tuned models of comparable size and, in several cases, substantially larger systems, demonstrating that domain-specific data and architectural adaptation are more decisive than parameter scale for performance on realistic legal reasoning tasks. All benchmark data, training datasets, model weights, and evaluation code are released openly to support reproducible research in domain-specific legal artificial intelligence. A web-based demo of SteuerLLM is available at https://steuerllm.i5.ai.fau.de.
The role of self-supervised pretraining in differentially private medical image analysis
Jan 27, 2026Differential privacy (DP) provides formal protection for sensitive data but typically incurs substantial losses in diagnostic performance. Model initialization has emerged as a critical factor in mitigating this degradation, yet the role of modern self-supervised learning under full-model DP remains poorly understood. Here, we present a large-scale evaluation of initialization strategies for differentially private medical image analysis, using chest radiograph classification as a representative benchmark with more than 800,000 images. Using state-of-the-art ConvNeXt models trained with DP-SGD across realistic privacy regimes, we compare non-domain-specific supervised ImageNet initialization, non-domain-specific self-supervised DINOv3 initialization, and domain-specific supervised pretraining on MIMIC-CXR, the largest publicly available chest radiograph dataset. Evaluations are conducted across five external datasets spanning diverse institutions and acquisition settings. We show that DINOv3 initialization consistently improves diagnostic utility relative to ImageNet initialization under DP, but remains inferior to domain-specific supervised pretraining, which achieves performance closest to non-private baselines. We further demonstrate that initialization choice strongly influences demographic fairness, cross-dataset generalization, and robustness to data scale and model capacity under privacy constraints. The results establish initialization strategy as a central determinant of utility, fairness, and generalization in differentially private medical imaging.
Resolution scaling governs DINOv3 transfer performance in chest radiograph classification
Oct 08, 2025Self-supervised learning (SSL) has advanced visual representation learning, but its value in chest radiography, a high-volume imaging modality with fine-grained findings, remains unclear. Meta's DINOv3 extends earlier SSL models through Gram-anchored self-distillation. Whether these design choices improve transfer learning for chest radiography has not been systematically tested. We benchmarked DINOv3 against DINOv2 and ImageNet initialization across seven datasets (n>814,000). Two representative backbones were evaluated: ViT-B/16 and ConvNeXt-B. Images were analyzed at 224x224, 512x512, and 1024x1024 pixels. We additionally assessed frozen features from a 7B model. The primary outcome was mean AUROC across labels. At 224x224, DINOv3 and DINOv2 achieved comparable performance on adult datasets. Increasing resolution to 512x512 yielded consistent improvements for DINOv3 over both DINOv2 and ImageNet. In contrast, results in pediatric cohort showed no differences across initializations. Across all settings, ConvNeXt-B outperformed ViT-B/16. Models using frozen DINOv3-7B features underperformed relative to fully finetuned 86-89M-parameter backbones, highlighting the importance of domain adaptation. Scaling to 1024x1024 did not further improve accuracy. Resolution-related gains were most evident for boundary-dependent and small focal abnormalities. In chest radiography, higher input resolution is critical for leveraging the benefits of modern self-supervised models. 512x512 pixels represent a practical upper limit where DINOv3-initialized ConvNeXt-B networks provide the strongest performance, while larger inputs offer minimal return on cost. Clinically, these findings support use of finetuned, mid-sized backbones at 512x512 for chest radiograph interpretation, with the greatest gains expected in detecting subtle or boundary-centered lesions relevant to emergency and critical care settings.
Agentic large language models improve retrieval-based radiology question answering
Aug 01, 2025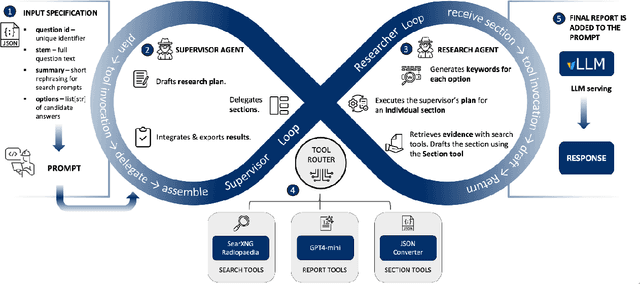
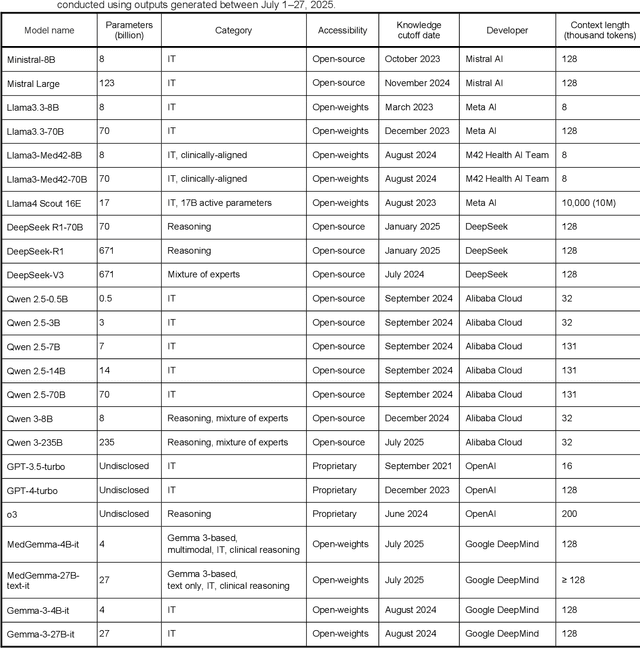
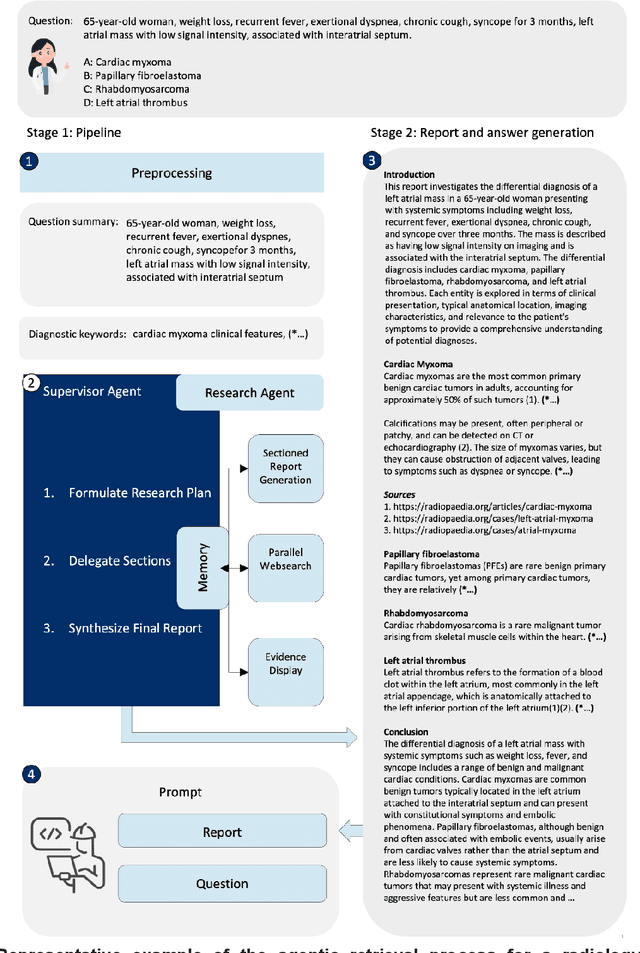
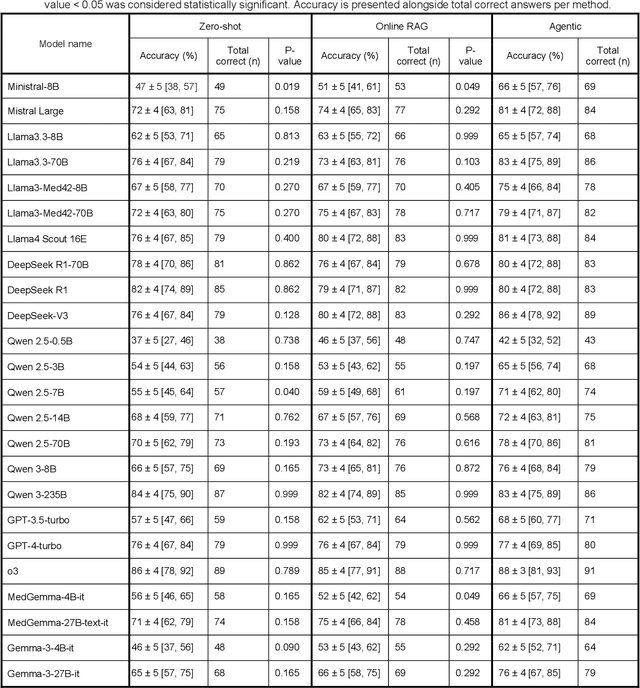
Clinical decision-making in radiology increasingly benefits from artificial intelligence (AI), particularly through large language models (LLMs). However, traditional retrieval-augmented generation (RAG) systems for radiology question answering (QA) typically rely on single-step retrieval, limiting their ability to handle complex clinical reasoning tasks. Here we propose an agentic RAG framework enabling LLMs to autonomously decompose radiology questions, iteratively retrieve targeted clinical evidence from Radiopaedia, and dynamically synthesize evidence-based responses. We evaluated 24 LLMs spanning diverse architectures, parameter scales (0.5B to >670B), and training paradigms (general-purpose, reasoning-optimized, clinically fine-tuned), using 104 expert-curated radiology questions from previously established RSNA-RadioQA and ExtendedQA datasets. Agentic retrieval significantly improved mean diagnostic accuracy over zero-shot prompting (73% vs. 64%; P<0.001) and conventional online RAG (73% vs. 68%; P<0.001). The greatest gains occurred in mid-sized models (e.g., Mistral Large improved from 72% to 81%) and small-scale models (e.g., Qwen 2.5-7B improved from 55% to 71%), while very large models (>200B parameters) demonstrated minimal changes (<2% improvement). Additionally, agentic retrieval reduced hallucinations (mean 9.4%) and retrieved clinically relevant context in 46% of cases, substantially aiding factual grounding. Even clinically fine-tuned models exhibited meaningful improvements (e.g., MedGemma-27B improved from 71% to 81%), indicating complementary roles of retrieval and fine-tuning. These results highlight the potential of agentic frameworks to enhance factuality and diagnostic accuracy in radiology QA, particularly among mid-sized LLMs, warranting future studies to validate their clinical utility.
Perceptual Implications of Automatic Anonymization in Pathological Speech
May 01, 2025Automatic anonymization techniques are essential for ethical sharing of pathological speech data, yet their perceptual consequences remain understudied. This study presents the first comprehensive human-centered analysis of anonymized pathological speech, using a structured perceptual protocol involving ten native and non-native German listeners with diverse linguistic, clinical, and technical backgrounds. Listeners evaluated anonymized-original utterance pairs from 180 speakers spanning Cleft Lip and Palate, Dysarthria, Dysglossia, Dysphonia, and age-matched healthy controls. Speech was anonymized using state-of-the-art automatic methods (equal error rates in the range of 30-40%). Listeners completed Turing-style discrimination and quality rating tasks under zero-shot (single-exposure) and few-shot (repeated-exposure) conditions. Discrimination accuracy was high overall (91% zero-shot; 93% few-shot), but varied by disorder (repeated-measures ANOVA: p=0.007), ranging from 96% (Dysarthria) to 86% (Dysphonia). Anonymization consistently reduced perceived quality (from 83% to 59%, p<0.001), with pathology-specific degradation patterns (one-way ANOVA: p=0.005). Native listeners rated original speech slightly higher than non-native listeners (Delta=4%, p=0.199), but this difference nearly disappeared after anonymization (Delta=1%, p=0.724). No significant gender-based bias was observed. Critically, human perceptual outcomes did not correlate with automatic privacy or clinical utility metrics. These results underscore the need for listener-informed, disorder- and context-specific anonymization strategies that preserve privacy while maintaining interpretability, communicative functions, and diagnostic utility, especially for vulnerable populations such as children.