 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Privacy: The Utility of Stand-Alone Synthetic CT and MRI for Tumor and Bone Segmentation
Jun 13, 2025AI requires extensive datasets, while medical data is subject to high data protection. Anonymization is essential, but poses a challenge for some regions, such as the head, as identifying structures overlap with regions of clinical interest. Synthetic data offers a potential solution, but studies often lack rigorous evaluation of realism and utility. Therefore, we investigate to what extent synthetic data can replace real data in segmentation tasks. We employed head and neck cancer CT scans and brain glioma MRI scans from two large datasets. Synthetic data were generated using generative adversarial networks and diffusion models. We evaluated the quality of the synthetic data using MAE, MS-SSIM, Radiomics and a Visual Turing Test (VTT) performed by 5 radiologists and their usefulness in segmentation tasks using DSC. Radiomics indicates high fidelity of synthetic MRIs, but fall short in producing highly realistic CT tissue, with correlation coefficient of 0.8784 and 0.5461 for MRI and CT tumors, respectively. DSC results indicate limited utility of synthetic data: tumor segmentation achieved DSC=0.064 on CT and 0.834 on MRI, while bone segmentation a mean DSC=0.841. Relation between DSC and correlation is observed, but is limited by the complexity of the task. VTT results show synthetic CTs' utility, but with limited educational applications. Synthetic data can be used independently for the segmentation task, although limited by the complexity of the structures to segment. Advancing generative models to better tolerate heterogeneous inputs and learn subtle details is essential for enhancing their realism and expanding their application potential.
Medical Slice Transformer: Improved Diagnosis and Explainability on 3D Medical Images with DINOv2
Nov 24, 2024



MRI and CT are essential clinical cross-sectional imaging techniques for diagnosing complex conditions. However, large 3D datasets with annotations for deep learning are scarce. While methods like DINOv2 are encouraging for 2D image analysis, these methods have not been applied to 3D medical images. Furthermore, deep learning models often lack explainability due to their "black-box" nature. This study aims to extend 2D self-supervised models, specifically DINOv2, to 3D medical imaging while evaluating their potential for explainable outcomes. We introduce the Medical Slice Transformer (MST) framework to adapt 2D self-supervised models for 3D medical image analysis. MST combines a Transformer architecture with a 2D feature extractor, i.e., DINOv2. We evaluate its diagnostic performance against a 3D convolutional neural network (3D ResNet) across three clinical datasets: breast MRI (651 patients), chest CT (722 patients), and knee MRI (1199 patients). Both methods were tested for diagnosing breast cancer, predicting lung nodule dignity, and detecting meniscus tears. Diagnostic performance was assessed by calculating the Area Under the Receiver Operating Characteristic Curve (AUC). Explainability was evaluated through a radiologist's qualitative comparison of saliency maps based on slice and lesion correctness. P-values were calculated using Delong's test. MST achieved higher AUC values compared to ResNet across all three datasets: breast (0.94$\pm$0.01 vs. 0.91$\pm$0.02, P=0.02), chest (0.95$\pm$0.01 vs. 0.92$\pm$0.02, P=0.13), and knee (0.85$\pm$0.04 vs. 0.69$\pm$0.05, P=0.001). Saliency maps were consistently more precise and anatomically correct for MST than for ResNet. Self-supervised 2D models like DINOv2 can be effectively adapted for 3D medical imaging using MST, offering enhanced diagnostic accuracy and explainability compared to convolutional neural networks.
RadioRAG: Factual Large Language Models for Enhanced Diagnostics in Radiology Using Dynamic Retrieval Augmented Generation
Jul 22, 2024



Large language models (LLMs) have advanced the field of artificial intelligence (AI) in medicine. However LLMs often generate outdated or inaccurate information based on static training datasets. Retrieval augmented generation (RAG) mitigates this by integrating outside data sources. While previous RAG systems used pre-assembled, fixed databases with limited flexibility, we have developed Radiology RAG (RadioRAG) as an end-to-end framework that retrieves data from authoritative radiologic online sources in real-time. RadioRAG is evaluated using a dedicated radiologic question-and-answer dataset (RadioQA). We evaluate the diagnostic accuracy of various LLMs when answering radiology-specific questions with and without access to additional online information via RAG. Using 80 questions from RSNA Case Collection across radiologic subspecialties and 24 additional expert-curated questions, for which the correct gold-standard answers were available, LLMs (GPT-3.5-turbo, GPT-4, Mistral-7B, Mixtral-8x7B, and Llama3 [8B and 70B]) were prompted with and without RadioRAG. RadioRAG retrieved context-specific information from www.radiopaedia.org in real-time and incorporated them into its reply. RadioRAG consistently improved diagnostic accuracy across all LLMs, with relative improvements ranging from 2% to 54%. It matched or exceeded question answering without RAG across radiologic subspecialties, particularly in breast imaging and emergency radiology. However, degree of improvement varied among models; GPT-3.5-turbo and Mixtral-8x7B-instruct-v0.1 saw notable gains, while Mistral-7B-instruct-v0.2 showed no improvement, highlighting variability in its effectiveness. LLMs benefit when provided access to domain-specific data beyond their training data. For radiology, RadioRAG establishes a robust framework that substantially improves diagnostic accuracy and factuality in radiological question answering.
Reconstruction of Patient-Specific Confounders in AI-based Radiologic Image Interpretation using Generative Pretraining
Sep 29, 2023

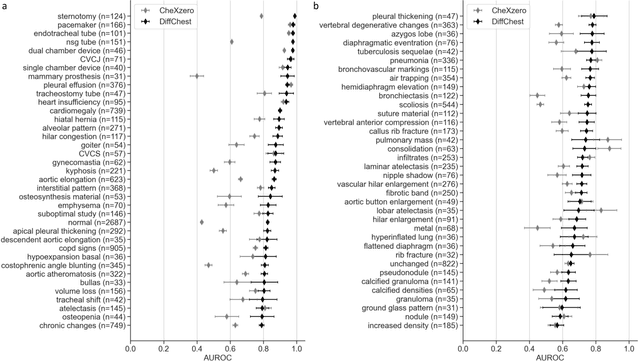

Detecting misleading patterns in automated diagnostic assistance systems, such as those powered by Artificial Intelligence, is critical to ensuring their reliability, particularly in healthcare. Current techniques for evaluating deep learning models cannot visualize confounding factors at a diagnostic level. Here, we propose a self-conditioned diffusion model termed DiffChest and train it on a dataset of 515,704 chest radiographs from 194,956 patients from multiple healthcare centers in the United States and Europe. DiffChest explains classifications on a patient-specific level and visualizes the confounding factors that may mislead the model. We found high inter-reader agreement when evaluating DiffChest's capability to identify treatment-related confounders, with Fleiss' Kappa values of 0.8 or higher across most imaging findings. Confounders were accurately captured with 11.1% to 100% prevalence rates. Furthermore, our pretraining process optimized the model to capture the most relevant information from the input radiographs. DiffChest achieved excellent diagnostic accuracy when diagnosing 11 chest conditions, such as pleural effusion and cardiac insufficiency, and at least sufficient diagnostic accuracy for the remaining conditions. Our findings highlight the potential of pretraining based on diffusion models in medical image classification, specifically in providing insights into confounding factors and model robustness.