 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential privacy representation geometry for medical image analysis
Mar 01, 2026Differential privacy (DP)'s effect in medical imaging is typically evaluated only through end-to-end performance, leaving the mechanism of privacy-induced utility loss unclear. We introduce Differential Privacy Representation Geometry for Medical Imaging (DP-RGMI), a framework that interprets DP as a structured transformation of representation space and decomposes performance degradation into encoder geometry and task-head utilization. Geometry is quantified by representation displacement from initialization and spectral effective dimension, while utilization is measured as the gap between linear-probe and end-to-end utility. Across over 594,000 images from four chest X-ray datasets and multiple pretrained initializations, we show that DP is consistently associated with a utilization gap even when linear separability is largely preserved. At the same time, displacement and spectral dimension exhibit non-monotonic, initialization- and dataset-dependent reshaping, indicating that DP alters representation anisotropy rather than uniformly collapsing features. Correlation analysis reveals that the association between end-to-end performance and utilization is robust across datasets but can vary by initialization, while geometric quantities capture additional prior- and dataset-conditioned variation. These findings position DP-RGMI as a reproducible framework for diagnosing privacy-induced failure modes and informing privacy model selection.
Can Agents Distinguish Visually Hard-to-Separate Diseases in a Zero-Shot Setting? A Pilot Study
Feb 26, 2026The rapid progress of multimodal large language models (MLLMs) has led to increasing interest in agent-based systems. While most prior work in medical imaging concentrates on automating routine clinical workflows, we study an underexplored yet clinically significant setting: distinguishing visually hard-to-separate diseases in a zero-shot setting. We benchmark representative agents on two imaging-only proxy diagnostic tasks, (1) melanoma vs. atypical nevus and (2) pulmonary edema vs. pneumonia, where visual features are highly confounded despite substantial differences in clinical management. We introduce a multi-agent framework based on contrastive adjudication. Experimental results show improved diagnostic performance (an 11-percentage-point gain in accuracy on dermoscopy data) and reduced unsupported claims on qualitative samples, although overall performance remains insufficient for clinical deployment. We acknowledge the inherent uncertainty in human annotations and the absence of clinical context, which further limit the translation to real-world settings. Within this controlled setting, this pilot study provides preliminary insights into zero-shot agent performance in visually confounded scenarios.
The role of self-supervised pretraining in differentially private medical image analysis
Jan 27, 2026Differential privacy (DP) provides formal protection for sensitive data but typically incurs substantial losses in diagnostic performance. Model initialization has emerged as a critical factor in mitigating this degradation, yet the role of modern self-supervised learning under full-model DP remains poorly understood. Here, we present a large-scale evaluation of initialization strategies for differentially private medical image analysis, using chest radiograph classification as a representative benchmark with more than 800,000 images. Using state-of-the-art ConvNeXt models trained with DP-SGD across realistic privacy regimes, we compare non-domain-specific supervised ImageNet initialization, non-domain-specific self-supervised DINOv3 initialization, and domain-specific supervised pretraining on MIMIC-CXR, the largest publicly available chest radiograph dataset. Evaluations are conducted across five external datasets spanning diverse institutions and acquisition settings. We show that DINOv3 initialization consistently improves diagnostic utility relative to ImageNet initialization under DP, but remains inferior to domain-specific supervised pretraining, which achieves performance closest to non-private baselines. We further demonstrate that initialization choice strongly influences demographic fairness, cross-dataset generalization, and robustness to data scale and model capacity under privacy constraints. The results establish initialization strategy as a central determinant of utility, fairness, and generalization in differentially private medical imaging.
Resolution scaling governs DINOv3 transfer performance in chest radiograph classification
Oct 08, 2025Self-supervised learning (SSL) has advanced visual representation learning, but its value in chest radiography, a high-volume imaging modality with fine-grained findings, remains unclear. Meta's DINOv3 extends earlier SSL models through Gram-anchored self-distillation. Whether these design choices improve transfer learning for chest radiography has not been systematically tested. We benchmarked DINOv3 against DINOv2 and ImageNet initialization across seven datasets (n>814,000). Two representative backbones were evaluated: ViT-B/16 and ConvNeXt-B. Images were analyzed at 224x224, 512x512, and 1024x1024 pixels. We additionally assessed frozen features from a 7B model. The primary outcome was mean AUROC across labels. At 224x224, DINOv3 and DINOv2 achieved comparable performance on adult datasets. Increasing resolution to 512x512 yielded consistent improvements for DINOv3 over both DINOv2 and ImageNet. In contrast, results in pediatric cohort showed no differences across initializations. Across all settings, ConvNeXt-B outperformed ViT-B/16. Models using frozen DINOv3-7B features underperformed relative to fully finetuned 86-89M-parameter backbones, highlighting the importance of domain adaptation. Scaling to 1024x1024 did not further improve accuracy. Resolution-related gains were most evident for boundary-dependent and small focal abnormalities. In chest radiography, higher input resolution is critical for leveraging the benefits of modern self-supervised models. 512x512 pixels represent a practical upper limit where DINOv3-initialized ConvNeXt-B networks provide the strongest performance, while larger inputs offer minimal return on cost. Clinically, these findings support use of finetuned, mid-sized backbones at 512x512 for chest radiograph interpretation, with the greatest gains expected in detecting subtle or boundary-centered lesions relevant to emergency and critical care settings.
MedicalPatchNet: A Patch-Based Self-Explainable AI Architecture for Chest X-ray Classification
Sep 09, 2025Deep neural networks excel in radiological image classification but frequently suffer from poor interpretability, limiting clinical acceptance. We present MedicalPatchNet, an inherently self-explainable architecture for chest X-ray classification that transparently attributes decisions to distinct image regions. MedicalPatchNet splits images into non-overlapping patches, independently classifies each patch, and aggregates predictions, enabling intuitive visualization of each patch's diagnostic contribution without post-hoc techniques. Trained on the CheXpert dataset (223,414 images), MedicalPatchNet matches the classification performance (AUROC 0.907 vs. 0.908) of EfficientNet-B0, while substantially improving interpretability: MedicalPatchNet demonstrates substantially improved interpretability with higher pathology localization accuracy (mean hit-rate 0.485 vs. 0.376 with Grad-CAM) on the CheXlocalize dataset. By providing explicit, reliable explanations accessible even to non-AI experts, MedicalPatchNet mitigates risks associated with shortcut learning, thus improving clinical trust. Our model is publicly available with reproducible training and inference scripts and contributes to safer, explainable AI-assisted diagnostics across medical imaging domains. We make the code publicly available: https://github.com/TruhnLab/MedicalPatchNet
Medical Slice Transformer: Improved Diagnosis and Explainability on 3D Medical Images with DINOv2
Nov 24, 2024



MRI and CT are essential clinical cross-sectional imaging techniques for diagnosing complex conditions. However, large 3D datasets with annotations for deep learning are scarce. While methods like DINOv2 are encouraging for 2D image analysis, these methods have not been applied to 3D medical images. Furthermore, deep learning models often lack explainability due to their "black-box" nature. This study aims to extend 2D self-supervised models, specifically DINOv2, to 3D medical imaging while evaluating their potential for explainable outcomes. We introduce the Medical Slice Transformer (MST) framework to adapt 2D self-supervised models for 3D medical image analysis. MST combines a Transformer architecture with a 2D feature extractor, i.e., DINOv2. We evaluate its diagnostic performance against a 3D convolutional neural network (3D ResNet) across three clinical datasets: breast MRI (651 patients), chest CT (722 patients), and knee MRI (1199 patients). Both methods were tested for diagnosing breast cancer, predicting lung nodule dignity, and detecting meniscus tears. Diagnostic performance was assessed by calculating the Area Under the Receiver Operating Characteristic Curve (AUC). Explainability was evaluated through a radiologist's qualitative comparison of saliency maps based on slice and lesion correctness. P-values were calculated using Delong's test. MST achieved higher AUC values compared to ResNet across all three datasets: breast (0.94$\pm$0.01 vs. 0.91$\pm$0.02, P=0.02), chest (0.95$\pm$0.01 vs. 0.92$\pm$0.02, P=0.13), and knee (0.85$\pm$0.04 vs. 0.69$\pm$0.05, P=0.001). Saliency maps were consistently more precise and anatomically correct for MST than for ResNet. Self-supervised 2D models like DINOv2 can be effectively adapted for 3D medical imaging using MST, offering enhanced diagnostic accuracy and explainability compared to convolutional neural networks.
RadioRAG: Factual Large Language Models for Enhanced Diagnostics in Radiology Using Dynamic Retrieval Augmented Generation
Jul 22, 2024



Large language models (LLMs) have advanced the field of artificial intelligence (AI) in medicine. However LLMs often generate outdated or inaccurate information based on static training datasets. Retrieval augmented generation (RAG) mitigates this by integrating outside data sources. While previous RAG systems used pre-assembled, fixed databases with limited flexibility, we have developed Radiology RAG (RadioRAG) as an end-to-end framework that retrieves data from authoritative radiologic online sources in real-time. RadioRAG is evaluated using a dedicated radiologic question-and-answer dataset (RadioQA). We evaluate the diagnostic accuracy of various LLMs when answering radiology-specific questions with and without access to additional online information via RAG. Using 80 questions from RSNA Case Collection across radiologic subspecialties and 24 additional expert-curated questions, for which the correct gold-standard answers were available, LLMs (GPT-3.5-turbo, GPT-4, Mistral-7B, Mixtral-8x7B, and Llama3 [8B and 70B]) were prompted with and without RadioRAG. RadioRAG retrieved context-specific information from www.radiopaedia.org in real-time and incorporated them into its reply. RadioRAG consistently improved diagnostic accuracy across all LLMs, with relative improvements ranging from 2% to 54%. It matched or exceeded question answering without RAG across radiologic subspecialties, particularly in breast imaging and emergency radiology. However, degree of improvement varied among models; GPT-3.5-turbo and Mixtral-8x7B-instruct-v0.1 saw notable gains, while Mistral-7B-instruct-v0.2 showed no improvement, highlighting variability in its effectiveness. LLMs benefit when provided access to domain-specific data beyond their training data. For radiology, RadioRAG establishes a robust framework that substantially improves diagnostic accuracy and factuality in radiological question answering.
On Instabilities of Unsupervised Denoising Diffusion Models in Magnetic Resonance Imaging Reconstruction
Jun 23, 2024Denoising diffusion models offer a promising approach to accelerating magnetic resonance imaging (MRI) and producing diagnostic-level images in an unsupervised manner. However, our study demonstrates that even tiny worst-case potential perturbations transferred from a surrogate model can cause these models to generate fake tissue structures that may mislead clinicians. The transferability of such worst-case perturbations indicates that the robustness of image reconstruction may be compromised due to MR system imperfections or other sources of noise. Moreover, at larger perturbation strengths, diffusion models exhibit Gaussian noise-like artifacts that are distinct from those observed in supervised models and are more challenging to detect. Our results highlight the vulnerability of current state-of-the-art diffusion-based reconstruction models to possible worst-case perturbations and underscore the need for further research to improve their robustness and reliability in clinical settings.
Compute-Efficient Medical Image Classification with Softmax-Free Transformers and Sequence Normalization
Jun 03, 2024The Transformer model has been pivotal in advancing fields such as natural language processing, speech recognition, and computer vision. However, a critical limitation of this model is its quadratic computational and memory complexity relative to the sequence length, which constrains its application to longer sequences. This is especially crucial in medical imaging where high-resolution images can reach gigapixel scale. Efforts to address this issue have predominantely focused on complex techniques, such as decomposing the softmax operation integral to the Transformer's architecture. This paper addresses this quadratic computational complexity of Transformer models and introduces a remarkably simple and effective method that circumvents this issue by eliminating the softmax function from the attention mechanism and adopting a sequence normalization technique for the key, query, and value tokens. Coupled with a reordering of matrix multiplications this approach reduces the memory- and compute complexity to a linear scale. We evaluate this approach across various medical imaging datasets comprising fundoscopic, dermascopic, radiologic and histologic imaging data. Our findings highlight that these models exhibit a comparable performance to traditional transformer models, while efficiently handling longer sequences.
An Ordinal Regression Framework for a Deep Learning Based Severity Assessment for Chest Radiographs
Feb 08, 2024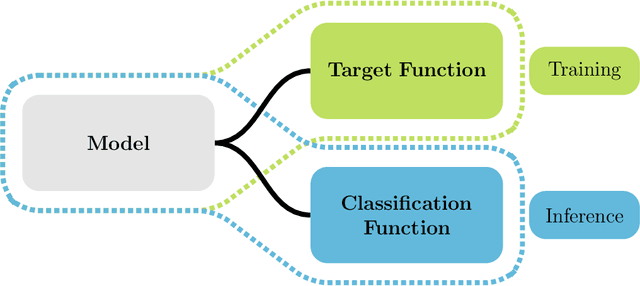
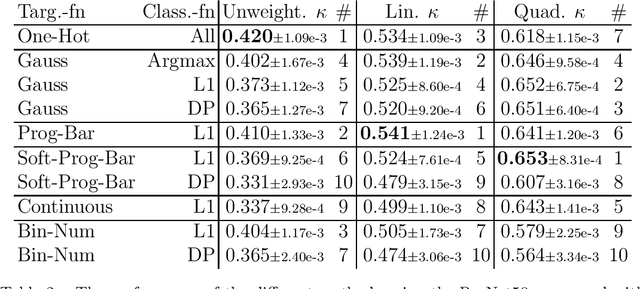
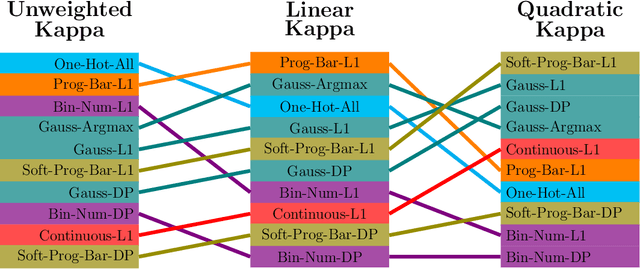
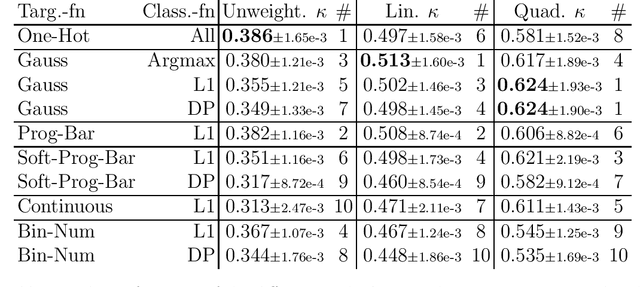
This study investigates the application of ordinal regression methods for categorizing disease severity in chest radiographs. We propose a framework that divides the ordinal regression problem into three parts: a model, a target function, and a classification function. Different encoding methods, including one-hot, Gaussian, progress-bar, and our soft-progress-bar, are applied using ResNet50 and ViT-B-16 deep learning models. We show that the choice of encoding has a strong impact on performance and that the best encoding depends on the chosen weighting of Cohen's kappa and also on the model architecture used. We make our code publicly available on GitHub.