 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHub.ai: A Simple, Standardized, and Reproducible Platform for AI Models in Medical Imaging
Jan 15, 2026Artificial intelligence (AI) has the potential to transform medical imaging by automating image analysis and accelerating clinical research. However, research and clinical use are limited by the wide variety of AI implementations and architectures, inconsistent documentation, and reproducibility issues. Here, we introduce MHub.ai, an open-source, container-based platform that standardizes access to AI models with minimal configuration, promoting accessibility and reproducibility in medical imaging. MHub.ai packages models from peer-reviewed publications into standardized containers that support direct processing of DICOM and other formats, provide a unified application interface, and embed structured metadata. Each model is accompanied by publicly available reference data that can be used to confirm model operation. MHub.ai includes an initial set of state-of-the-art segmentation, prediction, and feature extraction models for different modalities. The modular framework enables adaptation of any model and supports community contributions. We demonstrate the utility of the platform in a clinical use case through comparative evaluation of lung segmentation models. To further strengthen transparency and reproducibility, we publicly release the generated segmentations and evaluation metrics and provide interactive dashboards that allow readers to inspect individual cases and reproduce or extend our analysis. By simplifying model use, MHub.ai enables side-by-side benchmarking with identical execution commands and standardized outputs, and lowers the barrier to clinical translation.
No Data? No Problem: Robust Vision-Tabular Learning with Missing Values
Dec 22, 2025



Large-scale medical biobanks provide imaging data complemented by extensive tabular information, such as demographics or clinical measurements. However, this abundance of tabular attributes does not reflect real-world datasets, where only a subset of attributes may be available. This discrepancy calls for methods that can leverage all the tabular data during training while remaining robust to missing values at inference. To address this challenge, we propose RoVTL (Robust Vision-Tabular Learning), a framework designed to handle any level of tabular data availability, from 0% to 100%. RoVTL comprises two key stages: contrastive pretraining, where we introduce tabular attribute missingness as data augmentation to promote robustness, and downstream task tuning using a gated cross-attention module for multimodal fusion. During fine-tuning, we employ a novel Tabular More vs. Fewer loss that ranks performance based on the amount of available tabular data. Combined with disentangled gradient learning, this enables consistent performance across all tabular data completeness scenarios. We evaluate RoVTL on cardiac MRI scans from the UK Biobank, demonstrating superior robustness to missing tabular data compared to prior methods. Furthermore, RoVTL successfully generalizes to an external cardiac MRI dataset for multimodal disease classification, and extends to the natural images domain, achieving robust performance on a car advertisements dataset. The code is available at https://github.com/marteczkah/RoVTL.
Agentic large language models improve retrieval-based radiology question answering
Aug 01, 2025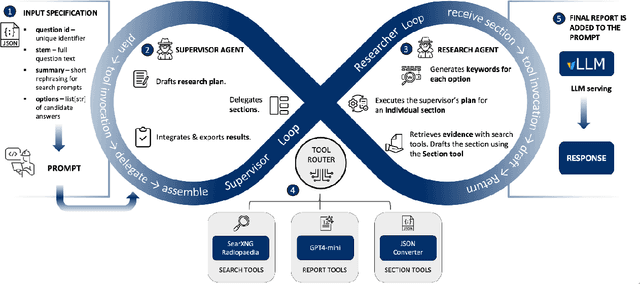
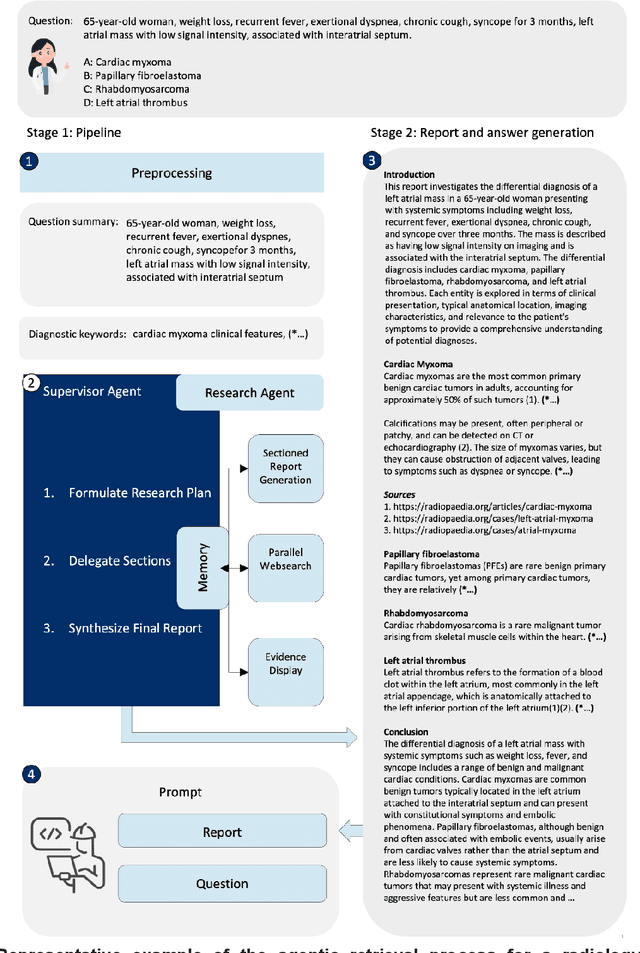
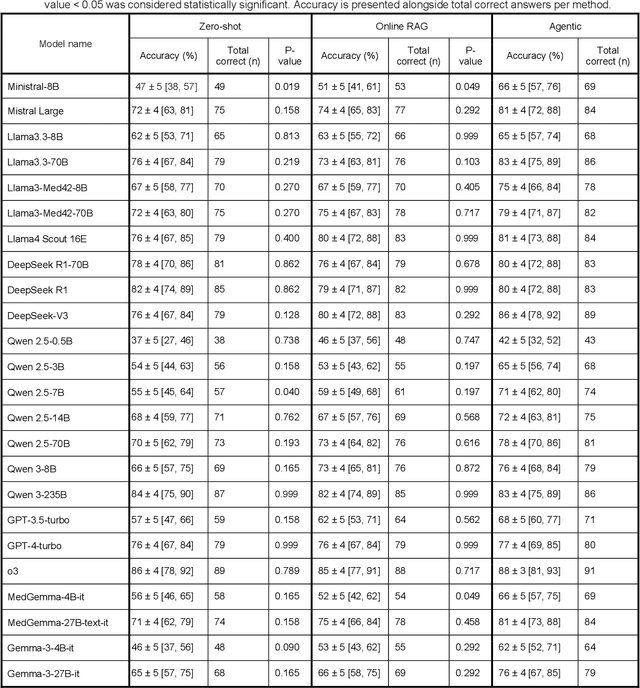
Clinical decision-making in radiology increasingly benefits from artificial intelligence (AI), particularly through large language models (LLMs). However, traditional retrieval-augmented generation (RAG) systems for radiology question answering (QA) typically rely on single-step retrieval, limiting their ability to handle complex clinical reasoning tasks. Here we propose an agentic RAG framework enabling LLMs to autonomously decompose radiology questions, iteratively retrieve targeted clinical evidence from Radiopaedia, and dynamically synthesize evidence-based responses. We evaluated 24 LLMs spanning diverse architectures, parameter scales (0.5B to >670B), and training paradigms (general-purpose, reasoning-optimized, clinically fine-tuned), using 104 expert-curated radiology questions from previously established RSNA-RadioQA and ExtendedQA datasets. Agentic retrieval significantly improved mean diagnostic accuracy over zero-shot prompting (73% vs. 64%; P<0.001) and conventional online RAG (73% vs. 68%; P<0.001). The greatest gains occurred in mid-sized models (e.g., Mistral Large improved from 72% to 81%) and small-scale models (e.g., Qwen 2.5-7B improved from 55% to 71%), while very large models (>200B parameters) demonstrated minimal changes (<2% improvement). Additionally, agentic retrieval reduced hallucinations (mean 9.4%) and retrieved clinically relevant context in 46% of cases, substantially aiding factual grounding. Even clinically fine-tuned models exhibited meaningful improvements (e.g., MedGemma-27B improved from 71% to 81%), indicating complementary roles of retrieval and fine-tuning. These results highlight the potential of agentic frameworks to enhance factuality and diagnostic accuracy in radiology QA, particularly among mid-sized LLMs, warranting future studies to validate their clinical utility.
TGV: Tabular Data-Guided Learning of Visual Cardiac Representations
Mar 19, 2025Contrastive learning methods in computer vision typically rely on different views of the same image to form pairs. However, in medical imaging, we often seek to compare entire patients with different phenotypes rather than just multiple augmentations of one scan. We propose harnessing clinically relevant tabular data to identify distinct patient phenotypes and form more meaningful pairs in a contrastive learning framework. Our method uses tabular attributes to guide the training of visual representations, without requiring a joint embedding space. We demonstrate its strength using short-axis cardiac MR images and clinical attributes from the UK Biobank, where tabular data helps to more effectively distinguish between patient subgroups. Evaluation on downstream tasks, including fine-tuning and zero-shot prediction of cardiovascular artery diseases and cardiac phenotypes, shows that incorporating tabular data yields stronger visual representations than conventional methods that rely solely on image augmentations or combined image-tabular embeddings. Furthermore, we demonstrate that image encoders trained with tabular guidance are capable of embedding demographic information in their representations, allowing them to use insights from tabular data for unimodal predictions, making them well-suited to real-world medical settings where extensive clinical annotations may not be routinely available at inference time. The code will be available on GitHub.
Vision Foundation Models for Computed Tomography
Jan 15, 2025Foundation models (FMs) have shown transformative potential in radiology by performing diverse, complex tasks across imaging modalities. Here, we developed CT-FM, a large-scale 3D image-based pre-trained model designed explicitly for various radiological tasks. CT-FM was pre-trained using 148,000 computed tomography (CT) scans from the Imaging Data Commons through label-agnostic contrastive learning. We evaluated CT-FM across four categories of tasks, namely, whole-body and tumor segmentation, head CT triage, medical image retrieval, and semantic understanding, showing superior performance against state-of-the-art models. Beyond quantitative success, CT-FM demonstrated the ability to cluster regions anatomically and identify similar anatomical and structural concepts across scans. Furthermore, it remained robust across test-retest settings and indicated reasonable salient regions attached to its embeddings. This study demonstrates the value of large-scale medical imaging foundation models and by open-sourcing the model weights, code, and data, aims to support more adaptable, reliable, and interpretable AI solutions in radiology.
RadioRAG: Factual Large Language Models for Enhanced Diagnostics in Radiology Using Dynamic Retrieval Augmented Generation
Jul 22, 2024



Large language models (LLMs) have advanced the field of artificial intelligence (AI) in medicine. However LLMs often generate outdated or inaccurate information based on static training datasets. Retrieval augmented generation (RAG) mitigates this by integrating outside data sources. While previous RAG systems used pre-assembled, fixed databases with limited flexibility, we have developed Radiology RAG (RadioRAG) as an end-to-end framework that retrieves data from authoritative radiologic online sources in real-time. RadioRAG is evaluated using a dedicated radiologic question-and-answer dataset (RadioQA). We evaluate the diagnostic accuracy of various LLMs when answering radiology-specific questions with and without access to additional online information via RAG. Using 80 questions from RSNA Case Collection across radiologic subspecialties and 24 additional expert-curated questions, for which the correct gold-standard answers were available, LLMs (GPT-3.5-turbo, GPT-4, Mistral-7B, Mixtral-8x7B, and Llama3 [8B and 70B]) were prompted with and without RadioRAG. RadioRAG retrieved context-specific information from www.radiopaedia.org in real-time and incorporated them into its reply. RadioRAG consistently improved diagnostic accuracy across all LLMs, with relative improvements ranging from 2% to 54%. It matched or exceeded question answering without RAG across radiologic subspecialties, particularly in breast imaging and emergency radiology. However, degree of improvement varied among models; GPT-3.5-turbo and Mixtral-8x7B-instruct-v0.1 saw notable gains, while Mistral-7B-instruct-v0.2 showed no improvement, highlighting variability in its effectiveness. LLMs benefit when provided access to domain-specific data beyond their training data. For radiology, RadioRAG establishes a robust framework that substantially improves diagnostic accuracy and factuality in radiological question answering.
LongHealth: A Question Answering Benchmark with Long Clinical Documents
Jan 25, 2024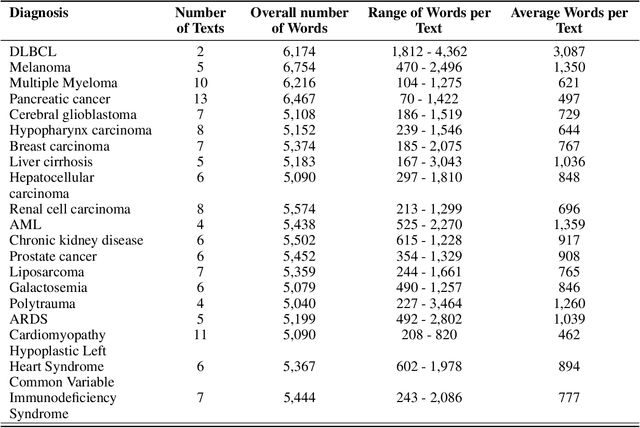
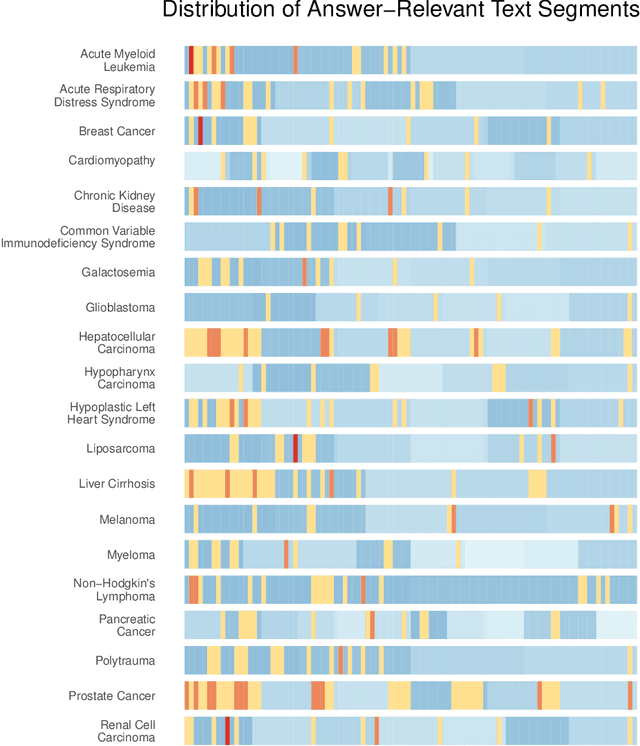

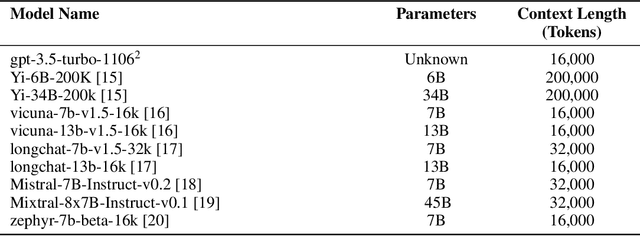
Background: Recent advancements in large language models (LLMs) offer potential benefits in healthcare, particularly in processing extensive patient records. However, existing benchmarks do not fully assess LLMs' capability in handling real-world, lengthy clinical data. Methods: We present the LongHealth benchmark, comprising 20 detailed fictional patient cases across various diseases, with each case containing 5,090 to 6,754 words. The benchmark challenges LLMs with 400 multiple-choice questions in three categories: information extraction, negation, and sorting, challenging LLMs to extract and interpret information from large clinical documents. Results: We evaluated nine open-source LLMs with a minimum of 16,000 tokens and also included OpenAI's proprietary and cost-efficient GPT-3.5 Turbo for comparison. The highest accuracy was observed for Mixtral-8x7B-Instruct-v0.1, particularly in tasks focused on information retrieval from single and multiple patient documents. However, all models struggled significantly in tasks requiring the identification of missing information, highlighting a critical area for improvement in clinical data interpretation. Conclusion: While LLMs show considerable potential for processing long clinical documents, their current accuracy levels are insufficient for reliable clinical use, especially in scenarios requiring the identification of missing information. The LongHealth benchmark provides a more realistic assessment of LLMs in a healthcare setting and highlights the need for further model refinement for safe and effective clinical application. We make the benchmark and evaluation code publicly available.
Generalist embedding models are better at short-context clinical semantic search than specialized embedding models
Jan 06, 2024The increasing use of tools and solutions based on Large Language Models (LLMs) for various tasks in the medical domain has become a prominent trend. Their use in this highly critical and sensitive domain has thus raised important questions about their robustness, especially in response to variations in input, and the reliability of the generated outputs. This study addresses these questions by constructing a textual dataset based on the ICD-10-CM code descriptions, widely used in US hospitals and containing many clinical terms, and their easily reproducible rephrasing. We then benchmarked existing embedding models, either generalist or specialized in the clinical domain, in a semantic search task where the goal was to correctly match the rephrased text to the original description. Our results showed that generalist models performed better than clinical models, suggesting that existing clinical specialized models are more sensitive to small changes in input that confuse them. The highlighted problem of specialized models may be due to the fact that they have not been trained on sufficient data, and in particular on datasets that are not diverse enough to have a reliable global language understanding, which is still necessary for accurate handling of medical documents.
From Text to Image: Exploring GPT-4Vision's Potential in Advanced Radiological Analysis across Subspecialties
Nov 24, 2023

The study evaluates and compares GPT-4 and GPT-4Vision for radiological tasks, suggesting GPT-4Vision may recognize radiological features from images, thereby enhancing its diagnostic potential over text-based descriptions.
Medical Diagnosis with Large Scale Multimodal Transformers: Leveraging Diverse Data for More Accurate Diagnosis
Dec 20, 2022Multimodal deep learning has been used to predict clinical endpoints and diagnoses from clinical routine data. However, these models suffer from scaling issues: they have to learn pairwise interactions between each piece of information in each data type, thereby escalating model complexity beyond manageable scales. This has so far precluded a widespread use of multimodal deep learning. Here, we present a new technical approach of "learnable synergies", in which the model only selects relevant interactions between data modalities and keeps an "internal memory" of relevant data. Our approach is easily scalable and naturally adapts to multimodal data inputs from clinical routine. We demonstrate this approach on three large multimodal datasets from radiology and ophthalmology and show that it outperforms state-of-the-art models in clinically relevant diagnosis tasks. Our new approach is transferable and will allow the application of multimodal deep learning to a broad set of clinically relevant problems.