 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe role of self-supervised pretraining in differentially private medical image analysis
Jan 27, 2026Differential privacy (DP) provides formal protection for sensitive data but typically incurs substantial losses in diagnostic performance. Model initialization has emerged as a critical factor in mitigating this degradation, yet the role of modern self-supervised learning under full-model DP remains poorly understood. Here, we present a large-scale evaluation of initialization strategies for differentially private medical image analysis, using chest radiograph classification as a representative benchmark with more than 800,000 images. Using state-of-the-art ConvNeXt models trained with DP-SGD across realistic privacy regimes, we compare non-domain-specific supervised ImageNet initialization, non-domain-specific self-supervised DINOv3 initialization, and domain-specific supervised pretraining on MIMIC-CXR, the largest publicly available chest radiograph dataset. Evaluations are conducted across five external datasets spanning diverse institutions and acquisition settings. We show that DINOv3 initialization consistently improves diagnostic utility relative to ImageNet initialization under DP, but remains inferior to domain-specific supervised pretraining, which achieves performance closest to non-private baselines. We further demonstrate that initialization choice strongly influences demographic fairness, cross-dataset generalization, and robustness to data scale and model capacity under privacy constraints. The results establish initialization strategy as a central determinant of utility, fairness, and generalization in differentially private medical imaging.
Agentic large language models improve retrieval-based radiology question answering
Aug 01, 2025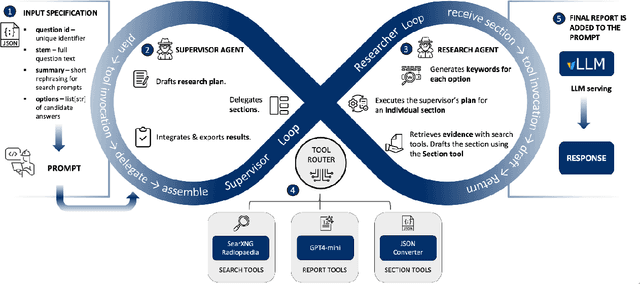
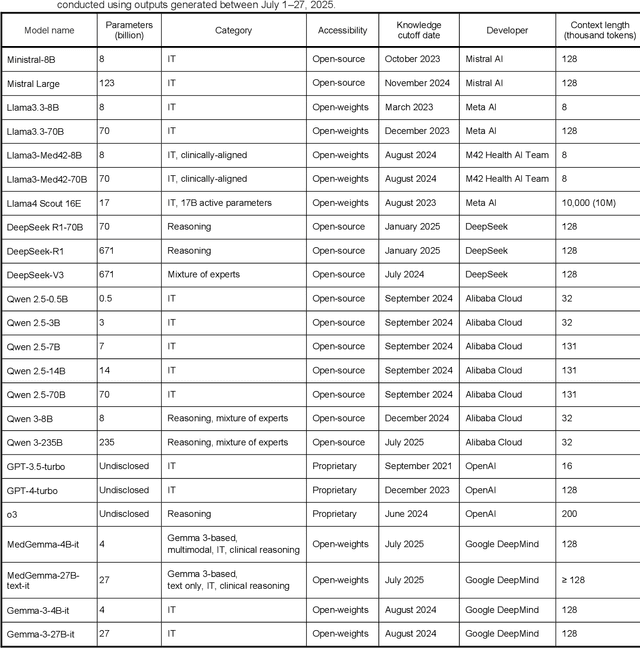
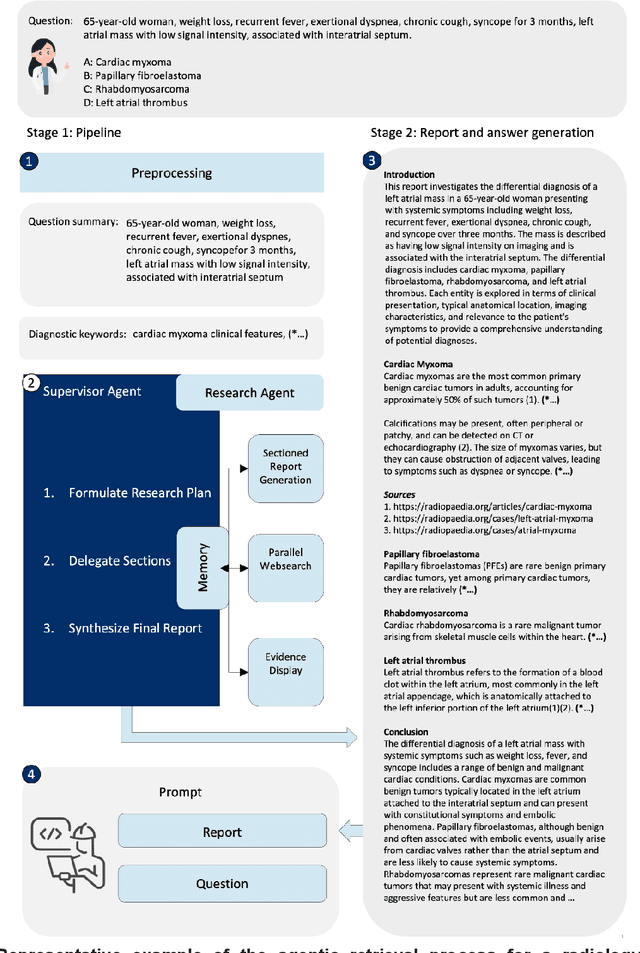
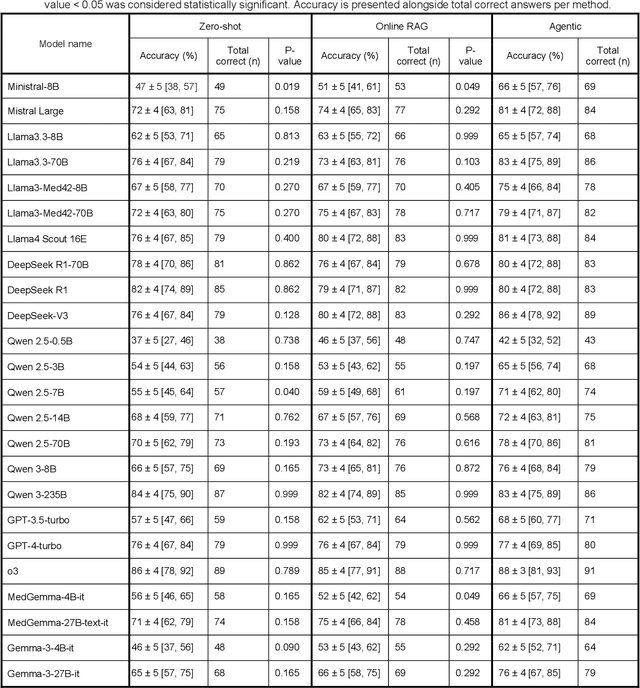
Clinical decision-making in radiology increasingly benefits from artificial intelligence (AI), particularly through large language models (LLMs). However, traditional retrieval-augmented generation (RAG) systems for radiology question answering (QA) typically rely on single-step retrieval, limiting their ability to handle complex clinical reasoning tasks. Here we propose an agentic RAG framework enabling LLMs to autonomously decompose radiology questions, iteratively retrieve targeted clinical evidence from Radiopaedia, and dynamically synthesize evidence-based responses. We evaluated 24 LLMs spanning diverse architectures, parameter scales (0.5B to >670B), and training paradigms (general-purpose, reasoning-optimized, clinically fine-tuned), using 104 expert-curated radiology questions from previously established RSNA-RadioQA and ExtendedQA datasets. Agentic retrieval significantly improved mean diagnostic accuracy over zero-shot prompting (73% vs. 64%; P<0.001) and conventional online RAG (73% vs. 68%; P<0.001). The greatest gains occurred in mid-sized models (e.g., Mistral Large improved from 72% to 81%) and small-scale models (e.g., Qwen 2.5-7B improved from 55% to 71%), while very large models (>200B parameters) demonstrated minimal changes (<2% improvement). Additionally, agentic retrieval reduced hallucinations (mean 9.4%) and retrieved clinically relevant context in 46% of cases, substantially aiding factual grounding. Even clinically fine-tuned models exhibited meaningful improvements (e.g., MedGemma-27B improved from 71% to 81%), indicating complementary roles of retrieval and fine-tuning. These results highlight the potential of agentic frameworks to enhance factuality and diagnostic accuracy in radiology QA, particularly among mid-sized LLMs, warranting future studies to validate their clinical utility.
Perceptual Implications of Automatic Anonymization in Pathological Speech
May 01, 2025Automatic anonymization techniques are essential for ethical sharing of pathological speech data, yet their perceptual consequences remain understudied. This study presents the first comprehensive human-centered analysis of anonymized pathological speech, using a structured perceptual protocol involving ten native and non-native German listeners with diverse linguistic, clinical, and technical backgrounds. Listeners evaluated anonymized-original utterance pairs from 180 speakers spanning Cleft Lip and Palate, Dysarthria, Dysglossia, Dysphonia, and age-matched healthy controls. Speech was anonymized using state-of-the-art automatic methods (equal error rates in the range of 30-40%). Listeners completed Turing-style discrimination and quality rating tasks under zero-shot (single-exposure) and few-shot (repeated-exposure) conditions. Discrimination accuracy was high overall (91% zero-shot; 93% few-shot), but varied by disorder (repeated-measures ANOVA: p=0.007), ranging from 96% (Dysarthria) to 86% (Dysphonia). Anonymization consistently reduced perceived quality (from 83% to 59%, p<0.001), with pathology-specific degradation patterns (one-way ANOVA: p=0.005). Native listeners rated original speech slightly higher than non-native listeners (Delta=4%, p=0.199), but this difference nearly disappeared after anonymization (Delta=1%, p=0.724). No significant gender-based bias was observed. Critically, human perceptual outcomes did not correlate with automatic privacy or clinical utility metrics. These results underscore the need for listener-informed, disorder- and context-specific anonymization strategies that preserve privacy while maintaining interpretability, communicative functions, and diagnostic utility, especially for vulnerable populations such as children.
Boosting multi-demographic federated learning for chest x-ray analysis using general-purpose self-supervised representations
Apr 11, 2025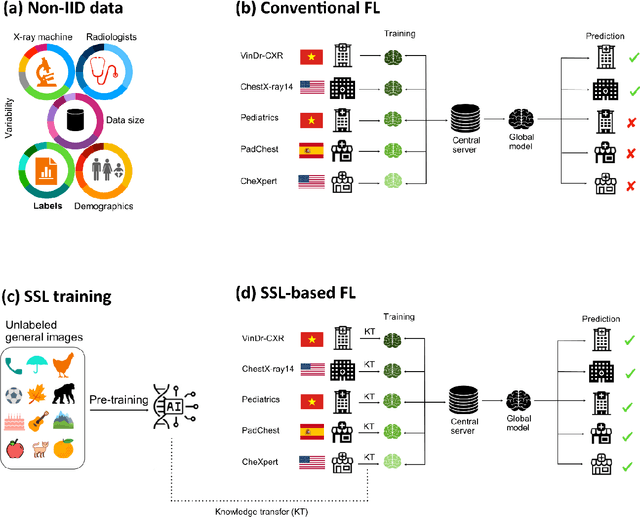
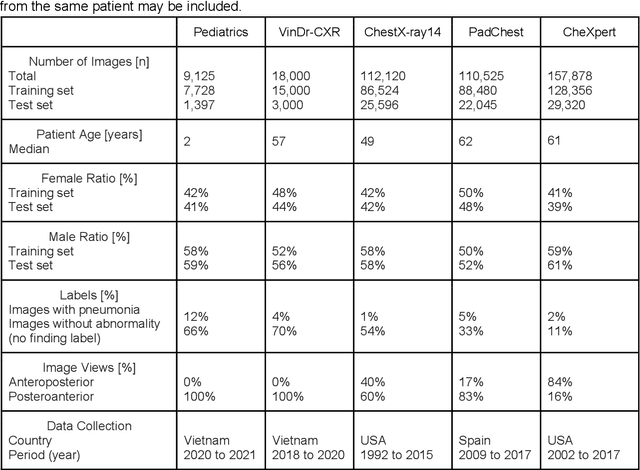
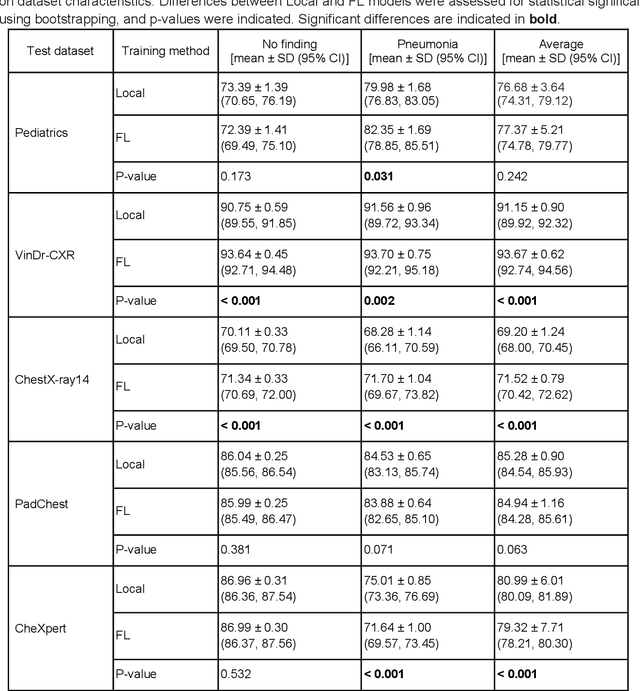
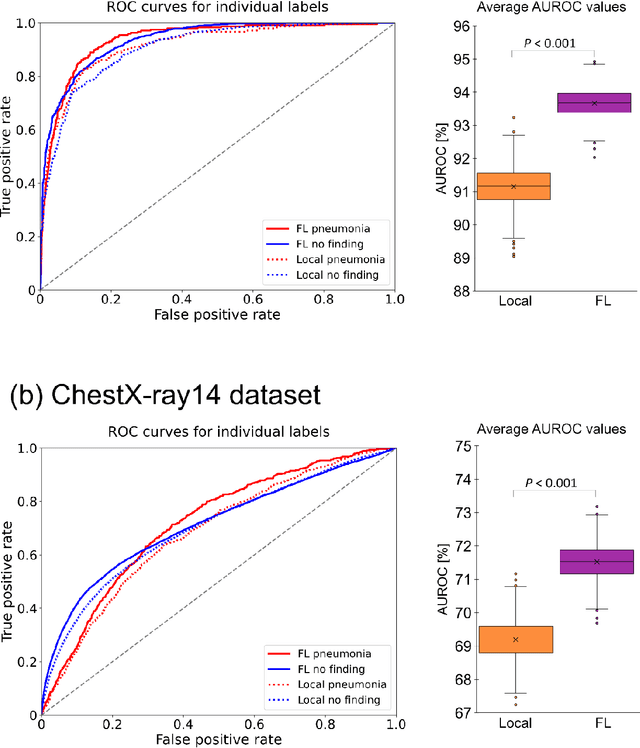
Reliable artificial intelligence (AI) models for medical image analysis often depend on large and diverse labeled datasets. Federated learning (FL) offers a decentralized and privacy-preserving approach to training but struggles in highly non-independent and identically distributed (non-IID) settings, where institutions with more representative data may experience degraded performance. Moreover, existing large-scale FL studies have been limited to adult datasets, neglecting the unique challenges posed by pediatric data, which introduces additional non-IID variability. To address these limitations, we analyzed n=398,523 adult chest radiographs from diverse institutions across multiple countries and n=9,125 pediatric images, leveraging transfer learning from general-purpose self-supervised image representations to classify pneumonia and cases with no abnormality. Using state-of-the-art vision transformers, we found that FL improved performance only for smaller adult datasets (P<0.001) but degraded performance for larger datasets (P<0.064) and pediatric cases (P=0.242). However, equipping FL with self-supervised weights significantly enhanced outcomes across pediatric cases (P=0.031) and most adult datasets (P<0.008), except the largest dataset (P=0.052). These findings underscore the potential of easily deployable general-purpose self-supervised image representations to address non-IID challenges in clinical FL applications and highlight their promise for enhancing patient outcomes and advancing pediatric healthcare, where data scarcity and variability remain persistent obstacles.
Differential privacy for protecting patient data in speech disorder detection using deep learning
Sep 27, 2024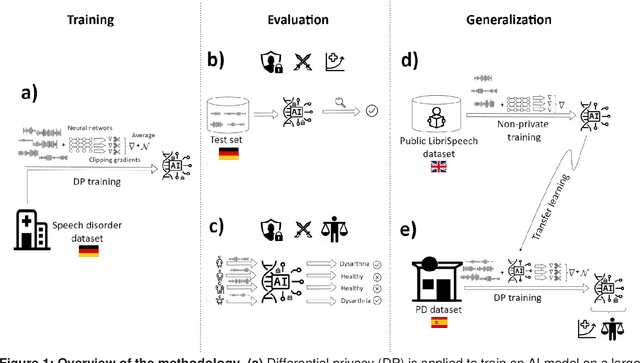
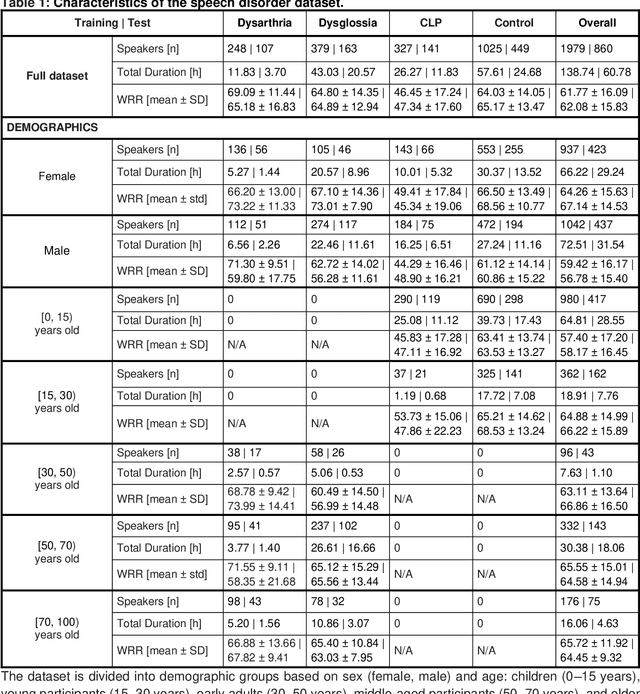
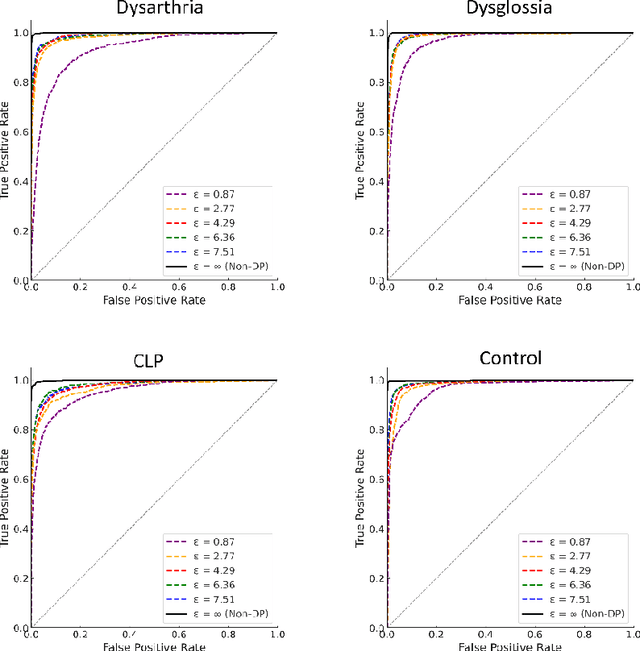
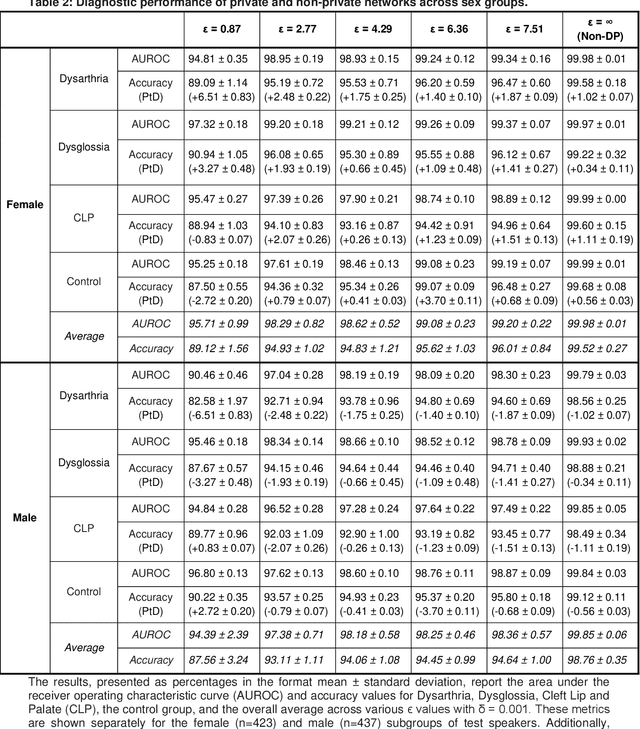
Speech pathology has impacts on communication abilities and quality of life. While deep learning-based models have shown potential in diagnosing these disorders, the use of sensitive data raises critical privacy concerns. Although differential privacy (DP) has been explored in the medical imaging domain, its application in pathological speech analysis remains largely unexplored despite the equally critical privacy concerns. This study is the first to investigate DP's impact on pathological speech data, focusing on the trade-offs between privacy, diagnostic accuracy, and fairness. Using a large, real-world dataset of 200 hours of recordings from 2,839 German-speaking participants, we observed a maximum accuracy reduction of 3.85% when training with DP with a privacy budget, denoted by {\epsilon}, of 7.51. To generalize our findings, we validated our approach on a smaller dataset of Spanish-speaking Parkinson's disease patients, demonstrating that careful pretraining on large-scale task-specific datasets can maintain or even improve model accuracy under DP constraints. We also conducted a comprehensive fairness analysis, revealing that reasonable privacy levels (2<{\epsilon}<10) do not introduce significant gender bias, though age-related disparities may require further attention. Our results suggest that DP can effectively balance privacy and utility in speech disorder detection, but also highlight the unique challenges in the speech domain, particularly regarding the privacy-fairness trade-off. This provides a foundation for future work to refine DP methodologies and address fairness across diverse patient groups in real-world deployments.
RadioRAG: Factual Large Language Models for Enhanced Diagnostics in Radiology Using Dynamic Retrieval Augmented Generation
Jul 22, 2024



Large language models (LLMs) have advanced the field of artificial intelligence (AI) in medicine. However LLMs often generate outdated or inaccurate information based on static training datasets. Retrieval augmented generation (RAG) mitigates this by integrating outside data sources. While previous RAG systems used pre-assembled, fixed databases with limited flexibility, we have developed Radiology RAG (RadioRAG) as an end-to-end framework that retrieves data from authoritative radiologic online sources in real-time. RadioRAG is evaluated using a dedicated radiologic question-and-answer dataset (RadioQA). We evaluate the diagnostic accuracy of various LLMs when answering radiology-specific questions with and without access to additional online information via RAG. Using 80 questions from RSNA Case Collection across radiologic subspecialties and 24 additional expert-curated questions, for which the correct gold-standard answers were available, LLMs (GPT-3.5-turbo, GPT-4, Mistral-7B, Mixtral-8x7B, and Llama3 [8B and 70B]) were prompted with and without RadioRAG. RadioRAG retrieved context-specific information from www.radiopaedia.org in real-time and incorporated them into its reply. RadioRAG consistently improved diagnostic accuracy across all LLMs, with relative improvements ranging from 2% to 54%. It matched or exceeded question answering without RAG across radiologic subspecialties, particularly in breast imaging and emergency radiology. However, degree of improvement varied among models; GPT-3.5-turbo and Mixtral-8x7B-instruct-v0.1 saw notable gains, while Mistral-7B-instruct-v0.2 showed no improvement, highlighting variability in its effectiveness. LLMs benefit when provided access to domain-specific data beyond their training data. For radiology, RadioRAG establishes a robust framework that substantially improves diagnostic accuracy and factuality in radiological question answering.
Empowering Clinicians and Democratizing Data Science: Large Language Models Automate Machine Learning for Clinical Studies
Aug 29, 2023A knowledge gap persists between Machine Learning (ML) developers (e.g., data scientists) and practitioners (e.g., clinicians), hampering the full utilization of ML for clinical data analysis. We investigated the potential of the chatGPT Advanced Data Analysis (ADA), an extension of GPT-4, to bridge this gap and perform ML analyses efficiently. Real-world clinical datasets and study details from large trials across various medical specialties were presented to chatGPT ADA without specific guidance. ChatGPT ADA autonomously developed state-of-the-art ML models based on the original study's training data to predict clinical outcomes such as cancer development, cancer progression, disease complications, or biomarkers such as pathogenic gene sequences. Strikingly, these ML models matched or outperformed their published counterparts. We conclude that chatGPT ADA offers a promising avenue to democratize ML in medicine, making advanced analytics accessible to non-ML experts and promoting broader applications in medical research and practice.
Preserving privacy in domain transfer of medical AI models comes at no performance costs: The integral role of differential privacy
Jun 10, 2023



Developing robust and effective artificial intelligence (AI) models in medicine requires access to large amounts of patient data. The use of AI models solely trained on large multi-institutional datasets can help with this, yet the imperative to ensure data privacy remains, particularly as membership inference risks breaching patient confidentiality. As a proposed remedy, we advocate for the integration of differential privacy (DP). We specifically investigate the performance of models trained with DP as compared to models trained without DP on data from institutions that the model had not seen during its training (i.e., external validation) - the situation that is reflective of the clinical use of AI models. By leveraging more than 590,000 chest radiographs from five institutions, we evaluated the efficacy of DP-enhanced domain transfer (DP-DT) in diagnosing cardiomegaly, pleural effusion, pneumonia, atelectasis, and in identifying healthy subjects. We juxtaposed DP-DT with non-DP-DT and examined diagnostic accuracy and demographic fairness using the area under the receiver operating characteristic curve (AUC) as the main metric, as well as accuracy, sensitivity, and specificity. Our results show that DP-DT, even with exceptionally high privacy levels (epsilon around 1), performs comparably to non-DP-DT (P>0.119 across all domains). Furthermore, DP-DT led to marginal AUC differences - less than 1% - for nearly all subgroups, relative to non-DP-DT. Despite consistent evidence suggesting that DP models induce significant performance degradation for on-domain applications, we show that off-domain performance is almost not affected. Therefore, we ardently advocate for the adoption of DP in training diagnostic medical AI models, given its minimal impact on performance.
How Will Your Tweet Be Received? Predicting the Sentiment Polarity of Tweet Replies
Apr 21, 2021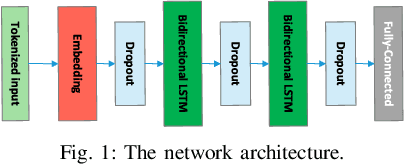

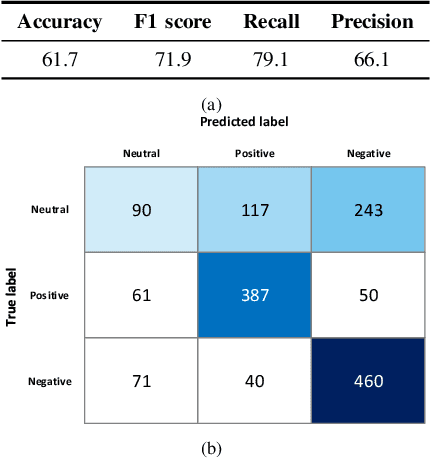
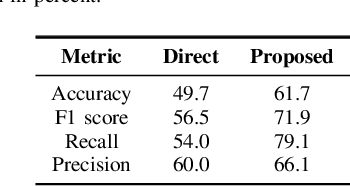
Twitter sentiment analysis, which often focuses on predicting the polarity of tweets, has attracted increasing attention over the last years, in particular with the rise of deep learning (DL). In this paper, we propose a new task: predicting the predominant sentiment among (first-order) replies to a given tweet. Therefore, we created RETWEET, a large dataset of tweets and replies manually annotated with sentiment labels. As a strong baseline, we propose a two-stage DL-based method: first, we create automatically labeled training data by applying a standard sentiment classifier to tweet replies and aggregating its predictions for each original tweet; our rationale is that individual errors made by the classifier are likely to cancel out in the aggregation step. Second, we use the automatically labeled data for supervised training of a neural network to predict reply sentiment from the original tweets. The resulting classifier is evaluated on the new RETWEET dataset, showing promising results, especially considering that it has been trained without any manually labeled data. Both the dataset and the baseline implementation are publicly available.
* Published in 2021 IEEE 15th International Conference on Semantic Computing (ICSC)
Machine Learning-Based Generalized Model for Finite Element Analysis of Roll Deflection During the Austenitic Stainless Steel 316L Strip Rolling
Feb 04, 2021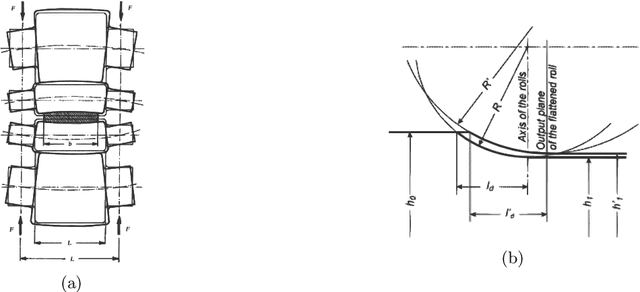

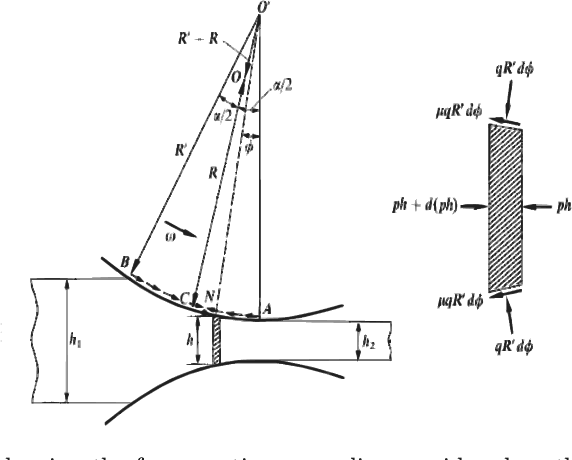

During the strip rolling process, a considerable amount of the forces of the material pressure cause elastic deformation on the work-roll, i.e., the deflection process. The uncontrollable amount of the work-roll deflection leads to the high deviations in the permissible thickness of the plate along its width. In the context of the Austenitic Stainless Steels (ASS), due to the instability of the Austenite phase in a cold temperature, cold deformation leads to the production of Strain-Induced Martensite (SIM), which improves the mechanical properties. It leads to the hardening of the ASS 316L during the cold deformation, which causes the Strain-Stress curve of the ASS 316L to behave non-linearly, which distinguishes it from other categories of steels. To account for this phenomenon, we propose to utilize a Machine Learning (ML) method to predict more accurately the flow stress of the ASS 316L during the cold rolling. Furthermore, we conduct various mechanical tensile tests in order to obtain the required dataset, Stress316L, for training the neural network. Moreover, instead of using a constant value of flow stress during the multi-pass rolling process, we use a Finite Difference (FD) formulation of the equilibrium equation in order to account for the dynamic behavior of the flow stress, which leads to the estimation of the mean pressure, which the strip enforces to the rolls during deformation. Finally, using the Finite Element Analysis (FEA), the deflection of the work-roll tools will be calculated. As a result, we end up with a generalized model for the calculation of the roll deflection, specific to the ASS 316L. To the best of our knowledge, this is the first model for ASS 316L which considers dynamic flow stress and SIM of the rolled plate, using FEM and an ML approach, which could contribute to the better design of the tolls.