 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical SAM3: A Foundation Model for Universal Prompt-Driven Medical Image Segmentation
Jan 15, 2026Promptable segmentation foundation models such as SAM3 have demonstrated strong generalization capabilities through interactive and concept-based prompting. However, their direct applicability to medical image segmentation remains limited by severe domain shifts, the absence of privileged spatial prompts, and the need to reason over complex anatomical and volumetric structures. Here we present Medical SAM3, a foundation model for universal prompt-driven medical image segmentation, obtained by fully fine-tuning SAM3 on large-scale, heterogeneous 2D and 3D medical imaging datasets with paired segmentation masks and text prompts. Through a systematic analysis of vanilla SAM3, we observe that its performance degrades substantially on medical data, with its apparent competitiveness largely relying on strong geometric priors such as ground-truth-derived bounding boxes. These findings motivate full model adaptation beyond prompt engineering alone. By fine-tuning SAM3's model parameters on 33 datasets spanning 10 medical imaging modalities, Medical SAM3 acquires robust domain-specific representations while preserving prompt-driven flexibility. Extensive experiments across organs, imaging modalities, and dimensionalities demonstrate consistent and significant performance gains, particularly in challenging scenarios characterized by semantic ambiguity, complex morphology, and long-range 3D context. Our results establish Medical SAM3 as a universal, text-guided segmentation foundation model for medical imaging and highlight the importance of holistic model adaptation for achieving robust prompt-driven segmentation under severe domain shift. Code and model will be made available at https://github.com/AIM-Research-Lab/Medical-SAM3.
Cell-free Fluid Antenna Multiple Access Networks
Apr 29, 2025Fluid antenna enables position reconfigurability that gives transceiver access to a high-resolution spatial signal and the ability to avoid interference through the ups and downs of fading channels. Previous studies investigated this fluid antenna multiple access (FAMA) approach in a single-cell setup only. In this paper, we consider a cell-free network architecture in which users are associated with the nearest base stations (BSs) and all users share the same physical channel. Each BS has multiple fixed antennas that employ maximum ratio transmission (MRT) to beam to its associated users while each user relies on its fluid antenna system (FAS) on one radio frequency (RF) chain to overcome the inter-user interference. Our aim is to analyze the outage probability performance of such cell-free FAMA network when both large- and small-scale fading effects are considered. To do so, we derive the distribution of the received \textcolor{black}{magnitude} for a typical user and then the interference distribution under both fast and slow port switching techniques. The outage probability is finally obtained in integral form in each case. Numerical results demonstrate that in an interference-limited situation, although fast port switching is typically understood as the superior method for FAMA, slow port switching emerges as a more effective solution when there is a large antenna array at the BS. Moreover, it is revealed that FAS at each user can serve to greatly reduce the burden of BS in terms of both antenna costs and CSI estimation overhead, thereby enhancing the scalability of cell-free networks.
Medical Slice Transformer: Improved Diagnosis and Explainability on 3D Medical Images with DINOv2
Nov 24, 2024



MRI and CT are essential clinical cross-sectional imaging techniques for diagnosing complex conditions. However, large 3D datasets with annotations for deep learning are scarce. While methods like DINOv2 are encouraging for 2D image analysis, these methods have not been applied to 3D medical images. Furthermore, deep learning models often lack explainability due to their "black-box" nature. This study aims to extend 2D self-supervised models, specifically DINOv2, to 3D medical imaging while evaluating their potential for explainable outcomes. We introduce the Medical Slice Transformer (MST) framework to adapt 2D self-supervised models for 3D medical image analysis. MST combines a Transformer architecture with a 2D feature extractor, i.e., DINOv2. We evaluate its diagnostic performance against a 3D convolutional neural network (3D ResNet) across three clinical datasets: breast MRI (651 patients), chest CT (722 patients), and knee MRI (1199 patients). Both methods were tested for diagnosing breast cancer, predicting lung nodule dignity, and detecting meniscus tears. Diagnostic performance was assessed by calculating the Area Under the Receiver Operating Characteristic Curve (AUC). Explainability was evaluated through a radiologist's qualitative comparison of saliency maps based on slice and lesion correctness. P-values were calculated using Delong's test. MST achieved higher AUC values compared to ResNet across all three datasets: breast (0.94$\pm$0.01 vs. 0.91$\pm$0.02, P=0.02), chest (0.95$\pm$0.01 vs. 0.92$\pm$0.02, P=0.13), and knee (0.85$\pm$0.04 vs. 0.69$\pm$0.05, P=0.001). Saliency maps were consistently more precise and anatomically correct for MST than for ResNet. Self-supervised 2D models like DINOv2 can be effectively adapted for 3D medical imaging using MST, offering enhanced diagnostic accuracy and explainability compared to convolutional neural networks.
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data
Aug 25, 2024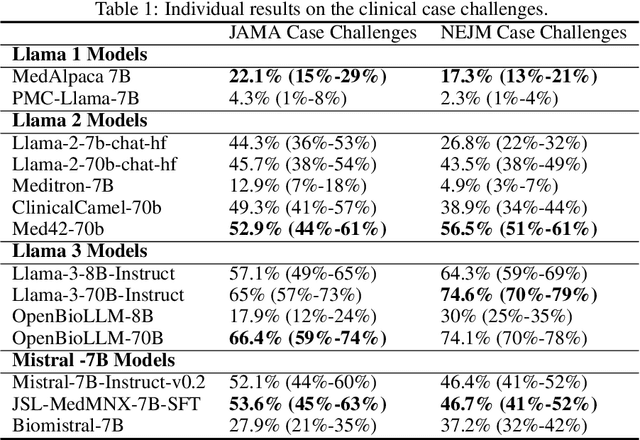
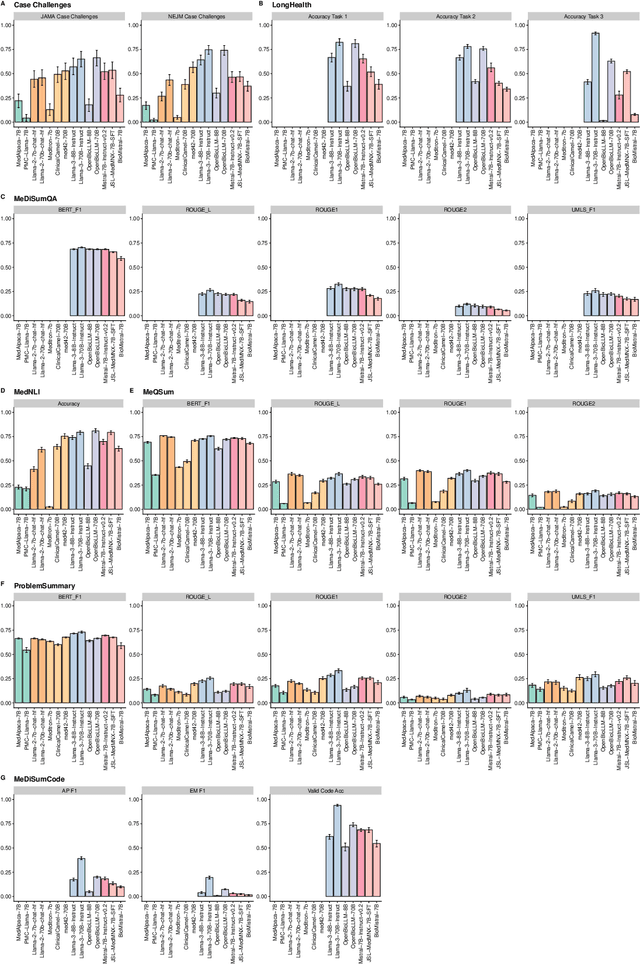
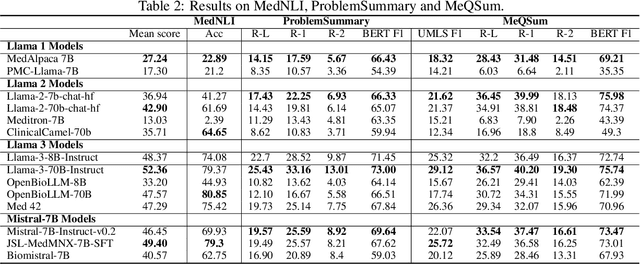
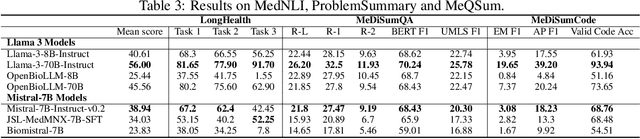
Large language models (LLMs) have shown potential in biomedical applications, leading to efforts to fine-tune them on domain-specific data. However, the effectiveness of this approach remains unclear. This study evaluates the performance of biomedically fine-tuned LLMs against their general-purpose counterparts on a variety of clinical tasks. We evaluated their performance on clinical case challenges from the New England Journal of Medicine (NEJM) and the Journal of the American Medical Association (JAMA) and on several clinical tasks (e.g., information extraction, document summarization, and clinical coding). Using benchmarks specifically chosen to be likely outside the fine-tuning datasets of biomedical models, we found that biomedical LLMs mostly perform inferior to their general-purpose counterparts, especially on tasks not focused on medical knowledge. While larger models showed similar performance on case tasks (e.g., OpenBioLLM-70B: 66.4% vs. Llama-3-70B-Instruct: 65% on JAMA cases), smaller biomedical models showed more pronounced underperformance (e.g., OpenBioLLM-8B: 30% vs. Llama-3-8B-Instruct: 64.3% on NEJM cases). Similar trends were observed across the CLUE (Clinical Language Understanding Evaluation) benchmark tasks, with general-purpose models often performing better on text generation, question answering, and coding tasks. Our results suggest that fine-tuning LLMs to biomedical data may not provide the expected benefits and may potentially lead to reduced performance, challenging prevailing assumptions about domain-specific adaptation of LLMs and highlighting the need for more rigorous evaluation frameworks in healthcare AI. Alternative approaches, such as retrieval-augmented generation, may be more effective in enhancing the biomedical capabilities of LLMs without compromising their general knowledge.
On Instabilities of Unsupervised Denoising Diffusion Models in Magnetic Resonance Imaging Reconstruction
Jun 23, 2024Denoising diffusion models offer a promising approach to accelerating magnetic resonance imaging (MRI) and producing diagnostic-level images in an unsupervised manner. However, our study demonstrates that even tiny worst-case potential perturbations transferred from a surrogate model can cause these models to generate fake tissue structures that may mislead clinicians. The transferability of such worst-case perturbations indicates that the robustness of image reconstruction may be compromised due to MR system imperfections or other sources of noise. Moreover, at larger perturbation strengths, diffusion models exhibit Gaussian noise-like artifacts that are distinct from those observed in supervised models and are more challenging to detect. Our results highlight the vulnerability of current state-of-the-art diffusion-based reconstruction models to possible worst-case perturbations and underscore the need for further research to improve their robustness and reliability in clinical settings.
Compute-Efficient Medical Image Classification with Softmax-Free Transformers and Sequence Normalization
Jun 03, 2024The Transformer model has been pivotal in advancing fields such as natural language processing, speech recognition, and computer vision. However, a critical limitation of this model is its quadratic computational and memory complexity relative to the sequence length, which constrains its application to longer sequences. This is especially crucial in medical imaging where high-resolution images can reach gigapixel scale. Efforts to address this issue have predominantely focused on complex techniques, such as decomposing the softmax operation integral to the Transformer's architecture. This paper addresses this quadratic computational complexity of Transformer models and introduces a remarkably simple and effective method that circumvents this issue by eliminating the softmax function from the attention mechanism and adopting a sequence normalization technique for the key, query, and value tokens. Coupled with a reordering of matrix multiplications this approach reduces the memory- and compute complexity to a linear scale. We evaluate this approach across various medical imaging datasets comprising fundoscopic, dermascopic, radiologic and histologic imaging data. Our findings highlight that these models exhibit a comparable performance to traditional transformer models, while efficiently handling longer sequences.
LongHealth: A Question Answering Benchmark with Long Clinical Documents
Jan 25, 2024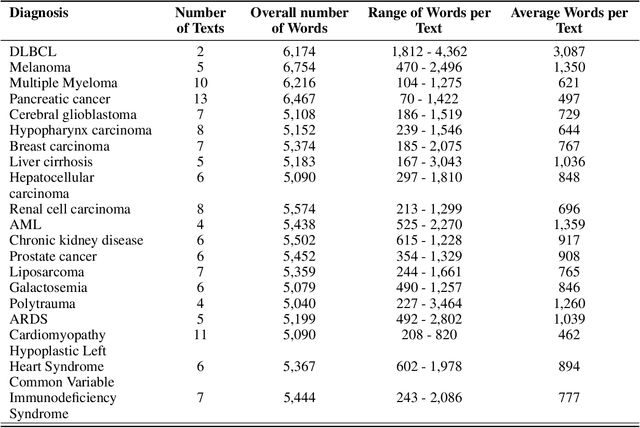
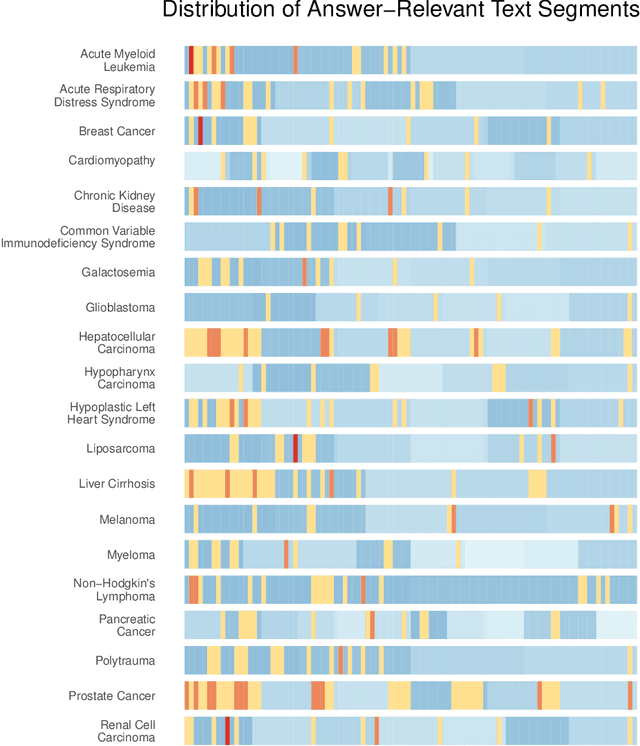

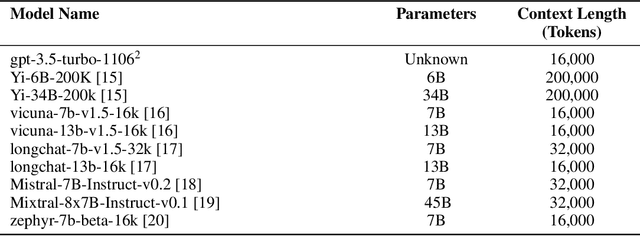
Background: Recent advancements in large language models (LLMs) offer potential benefits in healthcare, particularly in processing extensive patient records. However, existing benchmarks do not fully assess LLMs' capability in handling real-world, lengthy clinical data. Methods: We present the LongHealth benchmark, comprising 20 detailed fictional patient cases across various diseases, with each case containing 5,090 to 6,754 words. The benchmark challenges LLMs with 400 multiple-choice questions in three categories: information extraction, negation, and sorting, challenging LLMs to extract and interpret information from large clinical documents. Results: We evaluated nine open-source LLMs with a minimum of 16,000 tokens and also included OpenAI's proprietary and cost-efficient GPT-3.5 Turbo for comparison. The highest accuracy was observed for Mixtral-8x7B-Instruct-v0.1, particularly in tasks focused on information retrieval from single and multiple patient documents. However, all models struggled significantly in tasks requiring the identification of missing information, highlighting a critical area for improvement in clinical data interpretation. Conclusion: While LLMs show considerable potential for processing long clinical documents, their current accuracy levels are insufficient for reliable clinical use, especially in scenarios requiring the identification of missing information. The LongHealth benchmark provides a more realistic assessment of LLMs in a healthcare setting and highlights the need for further model refinement for safe and effective clinical application. We make the benchmark and evaluation code publicly available.
From Text to Image: Exploring GPT-4Vision's Potential in Advanced Radiological Analysis across Subspecialties
Nov 24, 2023

The study evaluates and compares GPT-4 and GPT-4Vision for radiological tasks, suggesting GPT-4Vision may recognize radiological features from images, thereby enhancing its diagnostic potential over text-based descriptions.
Medical Foundation Models are Susceptible to Targeted Misinformation Attacks
Sep 29, 2023



Large language models (LLMs) have broad medical knowledge and can reason about medical information across many domains, holding promising potential for diverse medical applications in the near future. In this study, we demonstrate a concerning vulnerability of LLMs in medicine. Through targeted manipulation of just 1.1% of the model's weights, we can deliberately inject an incorrect biomedical fact. The erroneous information is then propagated in the model's output, whilst its performance on other biomedical tasks remains intact. We validate our findings in a set of 1,038 incorrect biomedical facts. This peculiar susceptibility raises serious security and trustworthiness concerns for the application of LLMs in healthcare settings. It accentuates the need for robust protective measures, thorough verification mechanisms, and stringent management of access to these models, ensuring their reliable and safe use in medical practice.
Reconstruction of Patient-Specific Confounders in AI-based Radiologic Image Interpretation using Generative Pretraining
Sep 29, 2023

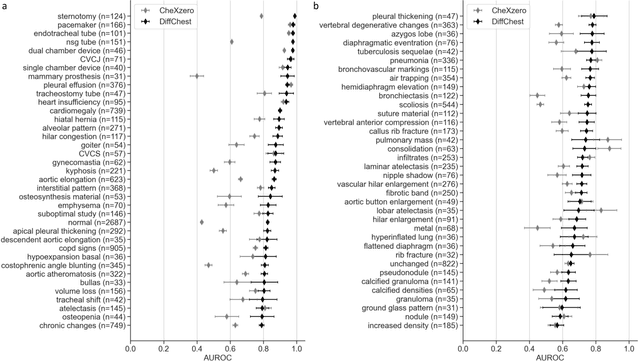

Detecting misleading patterns in automated diagnostic assistance systems, such as those powered by Artificial Intelligence, is critical to ensuring their reliability, particularly in healthcare. Current techniques for evaluating deep learning models cannot visualize confounding factors at a diagnostic level. Here, we propose a self-conditioned diffusion model termed DiffChest and train it on a dataset of 515,704 chest radiographs from 194,956 patients from multiple healthcare centers in the United States and Europe. DiffChest explains classifications on a patient-specific level and visualizes the confounding factors that may mislead the model. We found high inter-reader agreement when evaluating DiffChest's capability to identify treatment-related confounders, with Fleiss' Kappa values of 0.8 or higher across most imaging findings. Confounders were accurately captured with 11.1% to 100% prevalence rates. Furthermore, our pretraining process optimized the model to capture the most relevant information from the input radiographs. DiffChest achieved excellent diagnostic accuracy when diagnosing 11 chest conditions, such as pleural effusion and cardiac insufficiency, and at least sufficient diagnostic accuracy for the remaining conditions. Our findings highlight the potential of pretraining based on diffusion models in medical image classification, specifically in providing insights into confounding factors and model robustness.