 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Foundation Models are Susceptible to Targeted Misinformation Attacks
Sep 29, 2023



Large language models (LLMs) have broad medical knowledge and can reason about medical information across many domains, holding promising potential for diverse medical applications in the near future. In this study, we demonstrate a concerning vulnerability of LLMs in medicine. Through targeted manipulation of just 1.1% of the model's weights, we can deliberately inject an incorrect biomedical fact. The erroneous information is then propagated in the model's output, whilst its performance on other biomedical tasks remains intact. We validate our findings in a set of 1,038 incorrect biomedical facts. This peculiar susceptibility raises serious security and trustworthiness concerns for the application of LLMs in healthcare settings. It accentuates the need for robust protective measures, thorough verification mechanisms, and stringent management of access to these models, ensuring their reliable and safe use in medical practice.
Medical Diagnosis with Large Scale Multimodal Transformers: Leveraging Diverse Data for More Accurate Diagnosis
Dec 20, 2022



Multimodal deep learning has been used to predict clinical endpoints and diagnoses from clinical routine data. However, these models suffer from scaling issues: they have to learn pairwise interactions between each piece of information in each data type, thereby escalating model complexity beyond manageable scales. This has so far precluded a widespread use of multimodal deep learning. Here, we present a new technical approach of "learnable synergies", in which the model only selects relevant interactions between data modalities and keeps an "internal memory" of relevant data. Our approach is easily scalable and naturally adapts to multimodal data inputs from clinical routine. We demonstrate this approach on three large multimodal datasets from radiology and ophthalmology and show that it outperforms state-of-the-art models in clinically relevant diagnosis tasks. Our new approach is transferable and will allow the application of multimodal deep learning to a broad set of clinically relevant problems.
Diffusion Probabilistic Models beat GANs on Medical Images
Dec 14, 2022The success of Deep Learning applications critically depends on the quality and scale of the underlying training data. Generative adversarial networks (GANs) can generate arbitrary large datasets, but diversity and fidelity are limited, which has recently been addressed by denoising diffusion probabilistic models (DDPMs) whose superiority has been demonstrated on natural images. In this study, we propose Medfusion, a conditional latent DDPM for medical images. We compare our DDPM-based model against GAN-based models, which constitute the current state-of-the-art in the medical domain. Medfusion was trained and compared with (i) StyleGan-3 on n=101,442 images from the AIROGS challenge dataset to generate fundoscopies with and without glaucoma, (ii) ProGAN on n=191,027 from the CheXpert dataset to generate radiographs with and without cardiomegaly and (iii) wGAN on n=19,557 images from the CRCMS dataset to generate histopathological images with and without microsatellite stability. In the AIROGS, CRMCS, and CheXpert datasets, Medfusion achieved lower (=better) FID than the GANs (11.63 versus 20.43, 30.03 versus 49.26, and 17.28 versus 84.31). Also, fidelity (precision) and diversity (recall) were higher (=better) for Medfusion in all three datasets. Our study shows that DDPM are a superior alternative to GANs for image synthesis in the medical domain.
Medical Diffusion -- Denoising Diffusion Probabilistic Models for 3D Medical Image Generation
Nov 07, 2022Recent advances in computer vision have shown promising results in image generation. Diffusion probabilistic models in particular have generated realistic images from textual input, as demonstrated by DALL-E 2, Imagen and Stable Diffusion. However, their use in medicine, where image data typically comprises three-dimensional volumes, has not been systematically evaluated. Synthetic images may play a crucial role in privacy preserving artificial intelligence and can also be used to augment small datasets. Here we show that diffusion probabilistic models can synthesize high quality medical imaging data, which we show for Magnetic Resonance Images (MRI) and Computed Tomography (CT) images. We provide quantitative measurements of their performance through a reader study with two medical experts who rated the quality of the synthesized images in three categories: Realistic image appearance, anatomical correctness and consistency between slices. Furthermore, we demonstrate that synthetic images can be used in a self-supervised pre-training and improve the performance of breast segmentation models when data is scarce (dice score 0.91 vs. 0.95 without vs. with synthetic data).
Predicting Osteoarthritis Progression in Radiographs via Unsupervised Representation Learning
Nov 22, 2021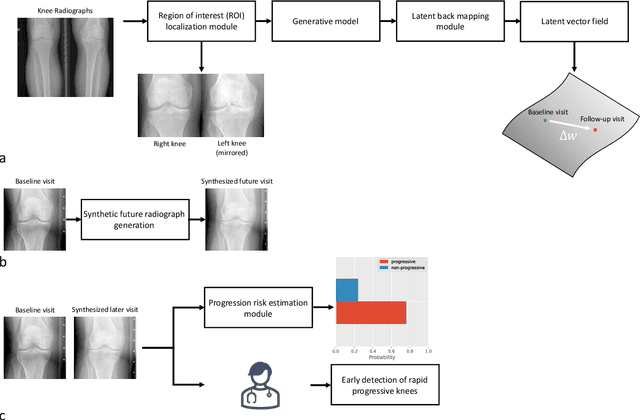
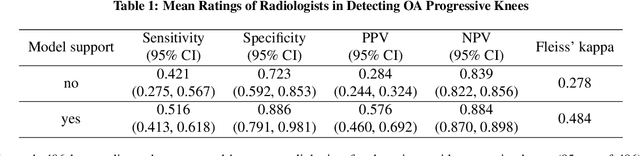
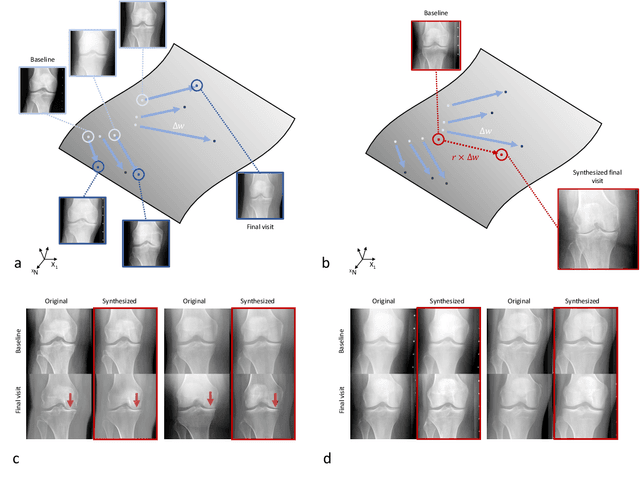
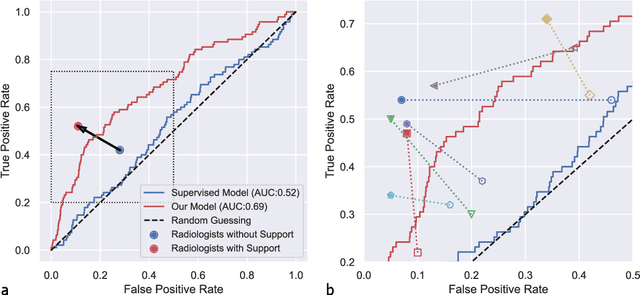
Osteoarthritis (OA) is the most common joint disorder affecting substantial proportions of the global population, primarily the elderly. Despite its individual and socioeconomic burden, the onset and progression of OA can still not be reliably predicted. Aiming to fill this diagnostic gap, we introduce an unsupervised learning scheme based on generative models to predict the future development of OA based on knee joint radiographs. Using longitudinal data from osteoarthritis studies, we explore the latent temporal trajectory to predict a patient's future radiographs up to the eight-year follow-up visit. Our model predicts the risk of progression towards OA and surpasses its supervised counterpart whose input was provided by seven experienced radiologists. With the support of the model, sensitivity, specificity, positive predictive value, and negative predictive value increased significantly from 42.1% to 51.6%, from 72.3% to 88.6%, from 28.4% to 57.6%, and from 83.9% to 88.4%, respectively, while without such support, radiologists performed only slightly better than random guessing. Our predictive model improves predictions on OA onset and progression, despite requiring no human annotation in the training phase.
Advancing diagnostic performance and clinical usability of neural networks via adversarial training and dual batch normalization
Nov 25, 2020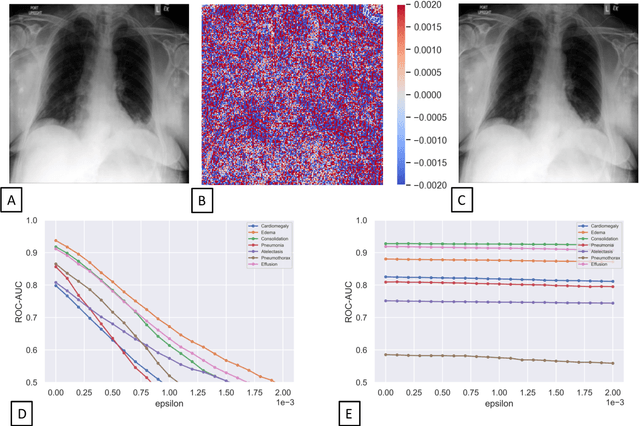


Unmasking the decision-making process of machine learning models is essential for implementing diagnostic support systems in clinical practice. Here, we demonstrate that adversarially trained models can significantly enhance the usability of pathology detection as compared to their standard counterparts. We let six experienced radiologists rate the interpretability of saliency maps in datasets of X-rays, computed tomography, and magnetic resonance imaging scans. Significant improvements were found for our adversarial models, which could be further improved by the application of dual batch normalization. Contrary to previous research on adversarially trained models, we found that the accuracy of such models was equal to standard models when sufficiently large datasets and dual batch norm training were used. To ensure transferability, we additionally validated our results on an external test set of 22,433 X-rays. These findings elucidate that different paths for adversarial and real images are needed during training to achieve state of the art results with superior clinical interpretability.
Radiomic Feature Stability Analysis based on Probabilistic Segmentations
Oct 13, 2019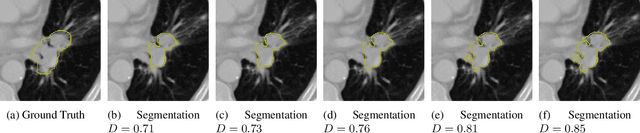
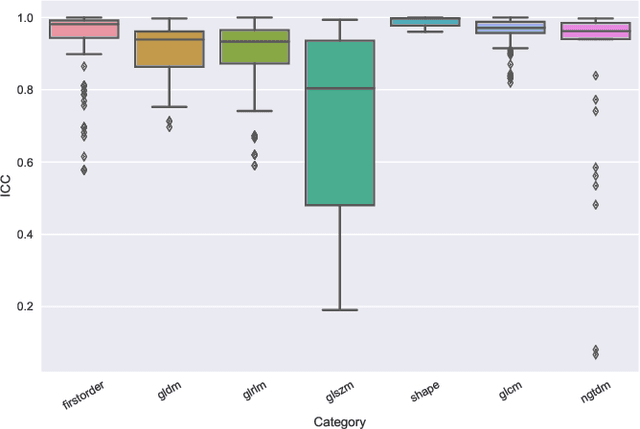
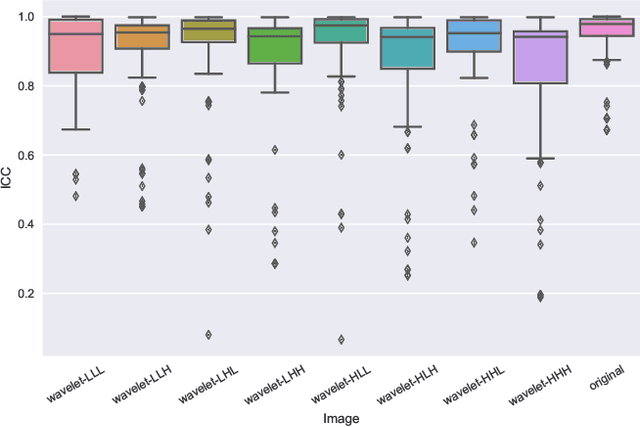
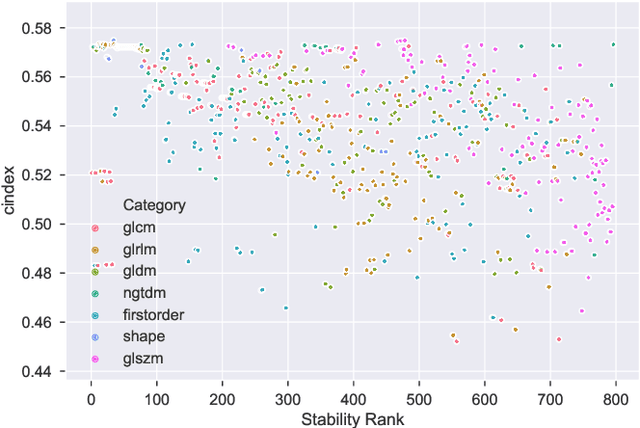
Identifying image features that are robust with respect to segmentation variability and domain shift is a tough challenge in radiomics. So far, this problem has mainly been tackled in test-retest analyses. In this work we analyze radiomics feature stability based on probabilistic automated segmentation hypotheses. Based on a public lung cancer dataset, we generate an arbitrary number of plausible segmentations using a Probabilistic U-Net. From these segmentations, we extract a high number of plausible feature vectors for each lung tumor and analyze feature variance with respect to the segmentations. Our results suggest that there are groups of radiomic features that are more (e.g. statistics features) and less (e.g. gray-level size zone matrix features) robust against segmentation variability. Finally, we demonstrate that segmentation variance impacts the performance of a prognostic lung cancer survival model and propose a new and potentially more robust radiomics feature selection workflow.
Multi Scale Curriculum CNN for Context-Aware Breast MRI Malignancy Classification
Jun 17, 2019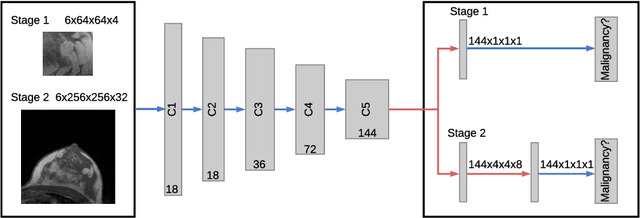
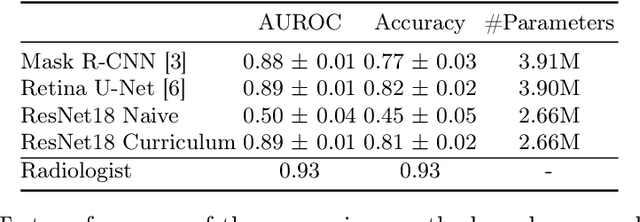
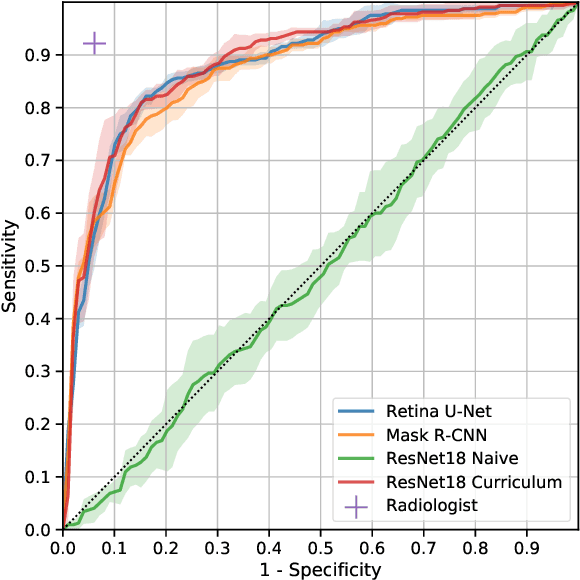
Classification of malignancy for breast cancer and other cancer types is usually tackled as an object detection problem: Individual lesions are first localized and then classified with respect to malignancy. However, the drawback of this approach is that abstract features incorporating several lesions and areas that are not labelled as a lesion but contain global medically relevant information are thus disregarded: especially for dynamic contrast-enhanced breast MRI, criteria such as background parenchymal enhancement and location within the breast are important for diagnosis and cannot be captured by object detection approaches properly. In this work, we propose a 3D CNN and a multi scale curriculum learning strategy to classify malignancy globally based on an MRI of the whole breast. Thus, the global context of the whole breast rather than individual lesions is taken into account. Our proposed approach does not rely on lesion segmentations, which renders the annotation of training data much more effective than in current object detection approaches. Achieving an AUROC of 0.89, we compare the performance of our approach to Mask R-CNN and Retina U-Net as well as a radiologist. Our performance is on par with approaches that, in contrast to our method, rely on pixelwise segmentations of lesions.
Image-based Survival Analysis for Lung Cancer Patients using CNNs
Oct 08, 2018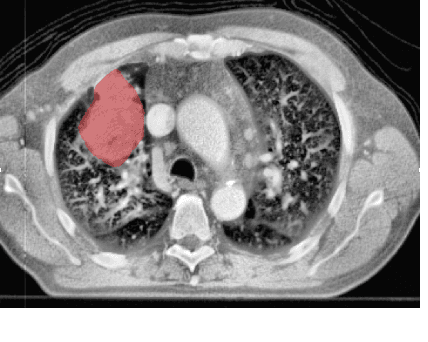
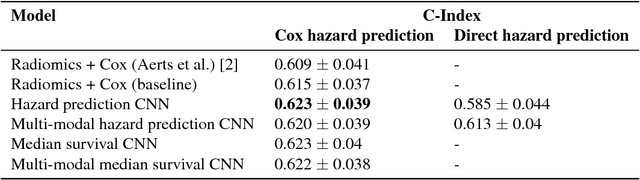
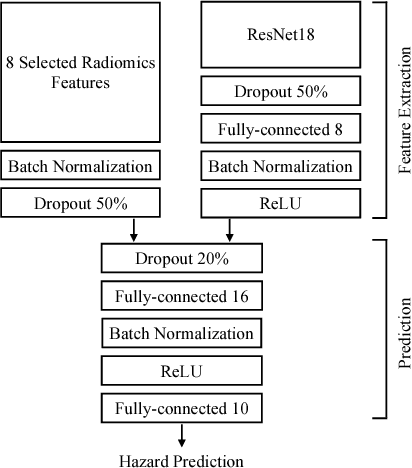
Traditional survival models such as the Cox proportional hazards model are typically based on scalar or categorical clinical features. With the advent of increasingly large image datasets, it has become feasible to incorporate quantitative image features into survival prediction. So far, this kind of analysis is mostly based on radiomics features, i.e. a fixed set of features that is mathematically defined a priori. To capture highly abstract information, it is desirable to learn the feature extraction using convolutional neural networks. However, for tomographic medical images, model training is difficult because on the one hand, only few samples of 3D image data fit into one batch at once and on the other hand, survival loss functions are essentially ordering measures that require large batch sizes. In this work, we show that by simplifying survival analysis to median survival classification, convolutional neural networks can be trained with small batch sizes and learn features that predict survival equally well as end-to-end hazard prediction networks. Our approach outperforms the previous state of the art in a publicly available lung cancer dataset.