 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing PatchCore for Few/many-shot Anomaly Detection
Jul 20, 2023Few-shot anomaly detection (AD) is an emerging sub-field of general AD, and tries to distinguish between normal and anomalous data using only few selected samples. While newly proposed few-shot AD methods do compare against pre-existing algorithms developed for the full-shot domain as baselines, they do not dedicatedly optimize them for the few-shot setting. It thus remains unclear if the performance of such pre-existing algorithms can be further improved. We address said question in this work. Specifically, we present a study on the AD/anomaly segmentation (AS) performance of PatchCore, the current state-of-the-art full-shot AD/AS algorithm, in both the few-shot and the many-shot settings. We hypothesize that further performance improvements can be realized by (I) optimizing its various hyperparameters, and by (II) transferring techniques known to improve few-shot supervised learning to the AD domain. Exhaustive experiments on the public VisA and MVTec AD datasets reveal that (I) significant performance improvements can be realized by optimizing hyperparameters such as the underlying feature extractor, and that (II) image-level augmentations can, but are not guaranteed, to improve performance. Based on these findings, we achieve a new state of the art in few-shot AD on VisA, further demonstrating the merit of adapting pre-existing AD/AS methods to the few-shot setting. Last, we identify the investigation of feature extractors with a strong inductive bias as a potential future research direction for (few-shot) AD/AS.
Transfer Learning Gaussian Anomaly Detection by Fine-Tuning Representations
Aug 09, 2021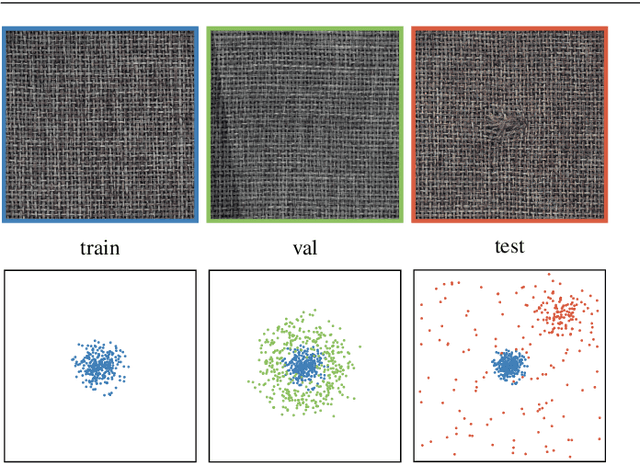
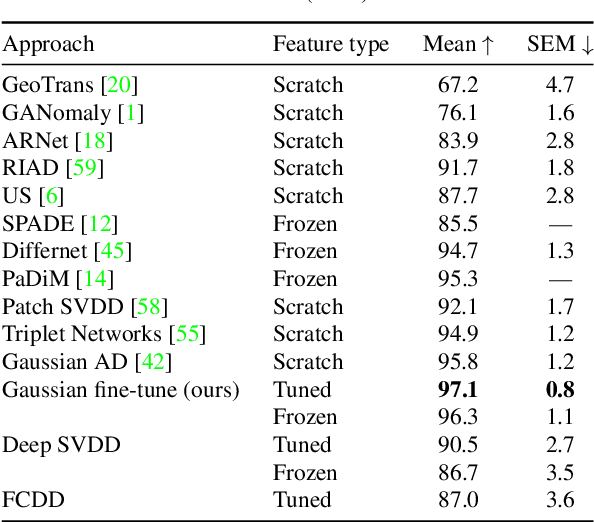


Current state-of-the-art Anomaly Detection (AD) methods exploit the powerful representations yielded by large-scale ImageNet training. However, catastrophic forgetting prevents the successful fine-tuning of pre-trained representations on new datasets in the semi/unsupervised setting, and representations are therefore commonly fixed. In our work, we propose a new method to fine-tune learned representations for AD in a transfer learning setting. Based on the linkage between generative and discriminative modeling, we induce a multivariate Gaussian distribution for the normal class, and use the Mahalanobis distance of normal images to the distribution as training objective. We additionally propose to use augmentations commonly employed for vicinal risk minimization in a validation scheme to detect onset of catastrophic forgetting. Extensive evaluations on the public MVTec AD dataset reveal that a new state of the art is achieved by our method in the AD task while simultaneously achieving AS performance comparable to prior state of the art. Further, ablation studies demonstrate the importance of the induced Gaussian distribution as well as the robustness of the proposed fine-tuning scheme with respect to the choice of augmentations.
The Medical Segmentation Decathlon
Jun 10, 2021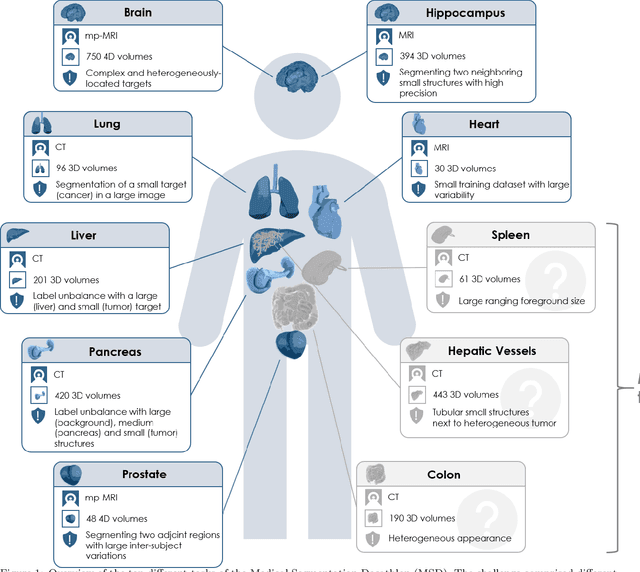
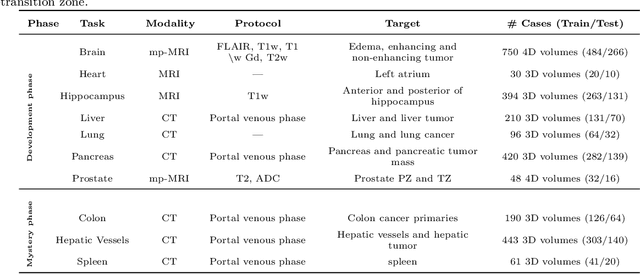
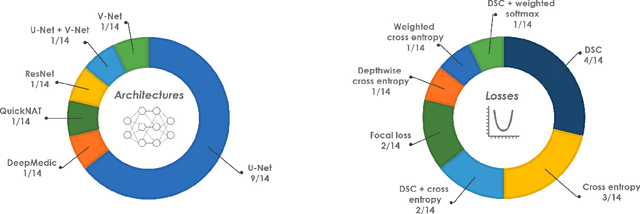
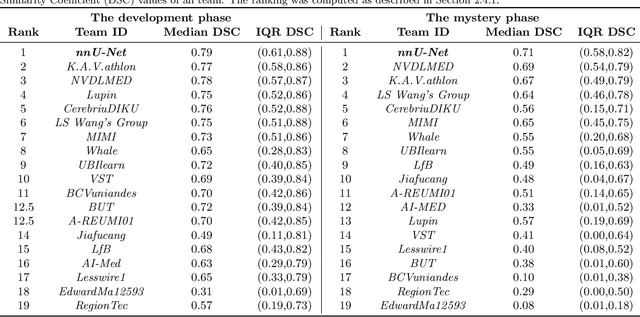
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection
May 28, 2020
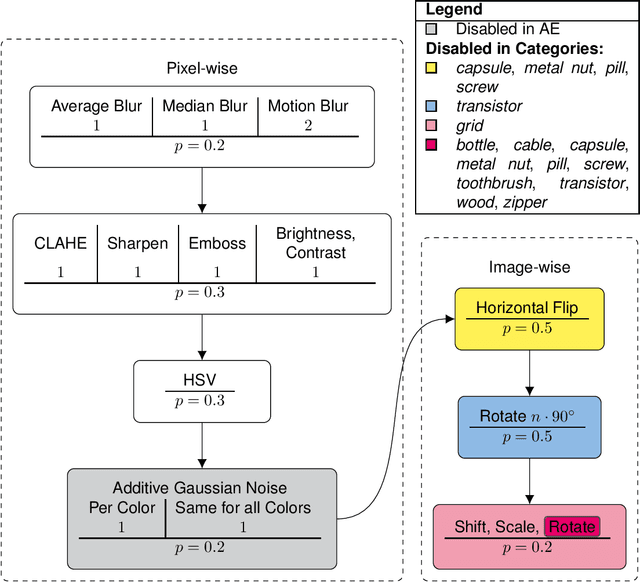
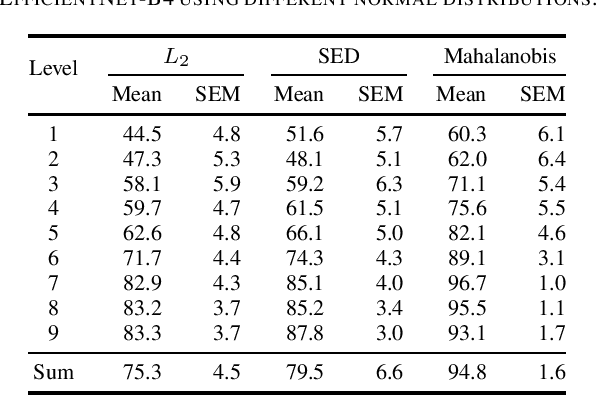
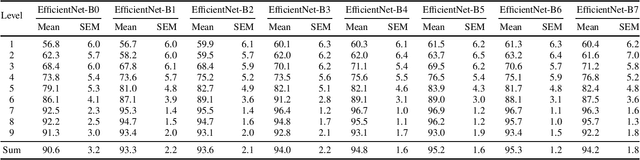
Anomaly Detection (AD) in images is a fundamental computer vision problem and refers to identifying images and/or image substructures that deviate significantly from the norm. Popular AD algorithms commonly try to learn a model of normality from scratch using task specific datasets, but are limited to semi-supervised approaches employing mostly normal data due to the inaccessibility of anomalies on a large scale combined with the ambiguous nature of anomaly appearance. We follow an alternative approach and demonstrate that deep feature representations learned by discriminative models on large natural image datasets are well suited to describe normality and detect even subtle anomalies. Our model of normality is established by fitting a multivariate Gaussian to deep feature representations of classification networks trained on ImageNet using normal data only in a transfer learning setting. By subsequently applying the Mahalanobis distance as the anomaly score we outperform the current state of the art on the public MVTec AD dataset, achieving an Area Under the Receiver Operating Characteristic curve of $95.8 \pm 1.2$ (mean $\pm$ SEM) over all 15 classes. We further investigate why the learned representations are discriminative to the AD task using Principal Component Analysis. We find that the principal components containing little variance in normal data are the ones crucial for discriminating between normal and anomalous instances. This gives a possible explanation to the often sub-par performance of AD approaches trained from scratch using normal data only. By selectively fitting a multivariate Gaussian to these most relevant components only we are able to further reduce model complexity while retaining AD performance. We also investigate setting the working point by selecting acceptable False Positive Rate thresholds based on the multivariate Gaussian assumption.
AutoML Segmentation for 3D Medical Image Data: Contribution to the MSD Challenge 2018
May 20, 2020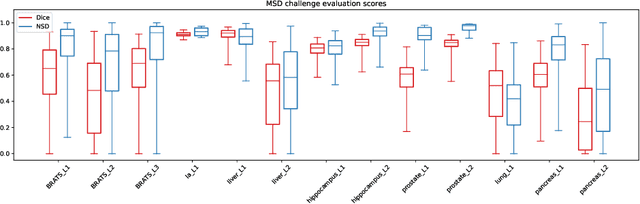
Fueled by recent advances in machine learning, there has been tremendous progress in the field of semantic segmentation for the medical image computing community. However, developed algorithms are often optimized and validated by hand based on one task only. In combination with small datasets, interpreting the generalizability of the results is often difficult. The Medical Segmentation Decathlon challenge addresses this problem, and aims to facilitate development of generalizable 3D semantic segmentation algorithms that require no manual parametrization. Such an algorithm was developed and is presented in this paper. It consists of a 3D convolutional neural network with encoder-decoder architecture employing residual-connections, skip-connections and multi-level generation of predictions. It works on anisotropic voxel-geometries and has anisotropic depth, i.e., the number of downsampling steps is a task-specific parameter. These depths are automatically inferred for each task prior to training. By combining this flexible architecture with on-the-fly data augmentation and little-to-no pre-- or postprocessing, promising results could be achieved. The code developed for this challenge will be available online after the final deadline at: https://github.com/ORippler/MSD_2018
Image-based Survival Analysis for Lung Cancer Patients using CNNs
Oct 08, 2018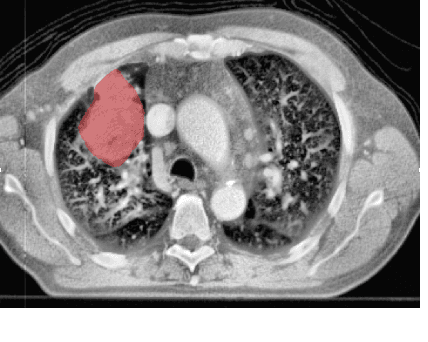
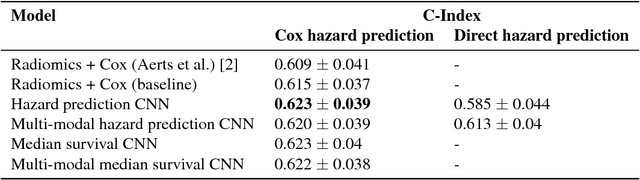
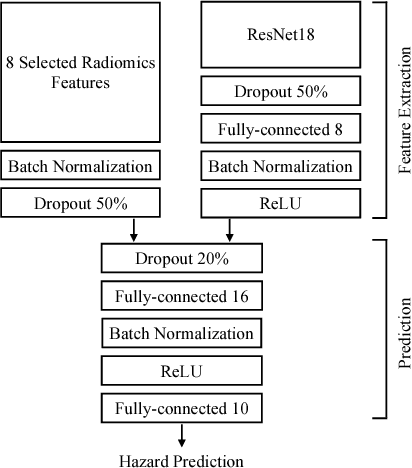
Traditional survival models such as the Cox proportional hazards model are typically based on scalar or categorical clinical features. With the advent of increasingly large image datasets, it has become feasible to incorporate quantitative image features into survival prediction. So far, this kind of analysis is mostly based on radiomics features, i.e. a fixed set of features that is mathematically defined a priori. To capture highly abstract information, it is desirable to learn the feature extraction using convolutional neural networks. However, for tomographic medical images, model training is difficult because on the one hand, only few samples of 3D image data fit into one batch at once and on the other hand, survival loss functions are essentially ordering measures that require large batch sizes. In this work, we show that by simplifying survival analysis to median survival classification, convolutional neural networks can be trained with small batch sizes and learn features that predict survival equally well as end-to-end hazard prediction networks. Our approach outperforms the previous state of the art in a publicly available lung cancer dataset.