 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS40K: a 3D Point Cloud Dataset of Rural Terrain and Electrical Transmission System
May 22, 2024



Research on supervised learning algorithms in 3D scene understanding has risen in prominence and witness great increases in performance across several datasets. The leading force of this research is the problem of autonomous driving followed by indoor scene segmentation. However, openly available 3D data on these tasks mainly focuses on urban scenarios. In this paper, we propose TS40K, a 3D point cloud dataset that encompasses more than 40,000 Km on electrical transmission systems situated in European rural terrain. This is not only a novel problem for the research community that can aid in the high-risk mission of power-grid inspection, but it also offers 3D point clouds with distinct characteristics from those in self-driving and indoor 3D data, such as high point-density and no occlusion. In our dataset, each 3D point is labeled with 1 out of 22 annotated classes. We evaluate the performance of state-of-the-art methods on our dataset concerning 3D semantic segmentation and 3D object detection. Finally, we provide a comprehensive analysis of the results along with key challenges such as using labels that were not originally intended for learning tasks.
Optimizing PatchCore for Few/many-shot Anomaly Detection
Jul 20, 2023Few-shot anomaly detection (AD) is an emerging sub-field of general AD, and tries to distinguish between normal and anomalous data using only few selected samples. While newly proposed few-shot AD methods do compare against pre-existing algorithms developed for the full-shot domain as baselines, they do not dedicatedly optimize them for the few-shot setting. It thus remains unclear if the performance of such pre-existing algorithms can be further improved. We address said question in this work. Specifically, we present a study on the AD/anomaly segmentation (AS) performance of PatchCore, the current state-of-the-art full-shot AD/AS algorithm, in both the few-shot and the many-shot settings. We hypothesize that further performance improvements can be realized by (I) optimizing its various hyperparameters, and by (II) transferring techniques known to improve few-shot supervised learning to the AD domain. Exhaustive experiments on the public VisA and MVTec AD datasets reveal that (I) significant performance improvements can be realized by optimizing hyperparameters such as the underlying feature extractor, and that (II) image-level augmentations can, but are not guaranteed, to improve performance. Based on these findings, we achieve a new state of the art in few-shot AD on VisA, further demonstrating the merit of adapting pre-existing AD/AS methods to the few-shot setting. Last, we identify the investigation of feature extractors with a strong inductive bias as a potential future research direction for (few-shot) AD/AS.
Evaluating Post-hoc Interpretability with Intrinsic Interpretability
May 04, 2023Despite Convolutional Neural Networks having reached human-level performance in some medical tasks, their clinical use has been hindered by their lack of interpretability. Two major interpretability strategies have been proposed to tackle this problem: post-hoc methods and intrinsic methods. Although there are several post-hoc methods to interpret DL models, there is significant variation between the explanations provided by each method, and it a difficult to validate them due to the lack of ground-truth. To address this challenge, we adapted the intrinsical interpretable ProtoPNet for the context of histopathology imaging and compared the attribution maps produced by it and the saliency maps made by post-hoc methods. To evaluate the similarity between saliency map methods and attribution maps we adapted 10 saliency metrics from the saliency model literature, and used the breast cancer metastases detection dataset PatchCamelyon with 327,680 patches of histopathological images of sentinel lymph node sections to validate the proposed approach. Overall, SmoothGrad and Occlusion were found to have a statistically bigger overlap with ProtoPNet while Deconvolution and Lime have been found to have the least.
Simplifying Multilingual News Clustering Through Projection From a Shared Space
Apr 28, 2022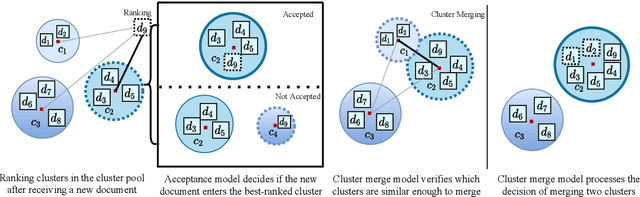
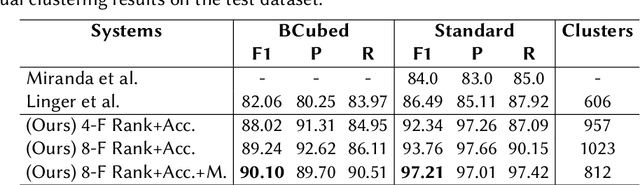
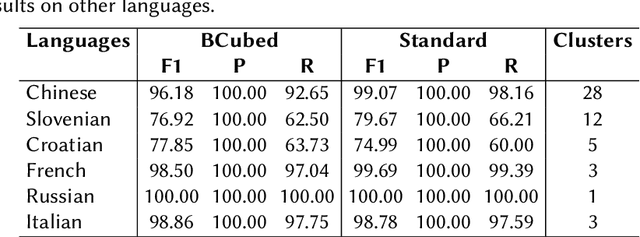
The task of organizing and clustering multilingual news articles for media monitoring is essential to follow news stories in real time. Most approaches to this task focus on high-resource languages (mostly English), with low-resource languages being disregarded. With that in mind, we present a much simpler online system that is able to cluster an incoming stream of documents without depending on language-specific features. We empirically demonstrate that the use of multilingual contextual embeddings as the document representation significantly improves clustering quality. We challenge previous crosslingual approaches by removing the precondition of building monolingual clusters. We model the clustering process as a set of linear classifiers to aggregate similar documents, and correct closely-related multilingual clusters through merging in an online fashion. Our system achieves state-of-the-art results on a multilingual news stream clustering dataset, and we introduce a new evaluation for zero-shot news clustering in multiple languages. We make our code available as open-source.
* 10 pages, 1 figure