 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decomposable Forward Process in Diffusion Models for Time-Series Forecasting
Jan 29, 2026We introduce a model-agnostic forward diffusion process for time-series forecasting that decomposes signals into spectral components, preserving structured temporal patterns such as seasonality more effectively than standard diffusion. Unlike prior work that modifies the network architecture or diffuses directly in the frequency domain, our proposed method alters only the diffusion process itself, making it compatible with existing diffusion backbones (e.g., DiffWave, TimeGrad, CSDI). By staging noise injection according to component energy, it maintains high signal-to-noise ratios for dominant frequencies throughout the diffusion trajectory, thereby improving the recoverability of long-term patterns. This strategy enables the model to maintain the signal structure for a longer period in the forward process, leading to improved forecast quality. Across standard forecasting benchmarks, we show that applying spectral decomposition strategies, such as the Fourier or Wavelet transform, consistently improves upon diffusion models using the baseline forward process, with negligible computational overhead. The code for this paper is available at https://anonymous.4open.science/r/D-FDP-4A29.
CLASP: An online learning algorithm for Convex Losses And Squared Penalties
Jan 24, 2026We study Constrained Online Convex Optimization (COCO), where a learner chooses actions iteratively, observes both unanticipated convex loss and convex constraint, and accumulates loss while incurring penalties for constraint violations. We introduce CLASP (Convex Losses And Squared Penalties), an algorithm that minimizes cumulative loss together with squared constraint violations. Our analysis departs from prior work by fully leveraging the firm non-expansiveness of convex projectors, a proof strategy not previously applied in this setting. For convex losses, CLASP achieves regret $O\left(T^{\max\{β,1-β\}}\right)$ and cumulative squared penalty $O\left(T^{1-β}\right)$ for any $β\in (0,1)$. Most importantly, for strongly convex problems, CLASP provides the first logarithmic guarantees on both regret and cumulative squared penalty. In the strongly convex case, the regret is upper bounded by $O( \log T )$ and the cumulative squared penalty is also upper bounded by $O( \log T )$.
C-PATH: Conversational Patient Assistance and Triage in Healthcare System
Jun 07, 2025Navigating healthcare systems can be complex and overwhelming, creating barriers for patients seeking timely and appropriate medical attention. In this paper, we introduce C-PATH (Conversational Patient Assistance and Triage in Healthcare), a novel conversational AI system powered by large language models (LLMs) designed to assist patients in recognizing symptoms and recommending appropriate medical departments through natural, multi-turn dialogues. C-PATH is fine-tuned on medical knowledge, dialogue data, and clinical summaries using a multi-stage pipeline built on the LLaMA3 architecture. A core contribution of this work is a GPT-based data augmentation framework that transforms structured clinical knowledge from DDXPlus into lay-person-friendly conversations, allowing alignment with patient communication norms. We also implement a scalable conversation history management strategy to ensure long-range coherence. Evaluation with GPTScore demonstrates strong performance across dimensions such as clarity, informativeness, and recommendation accuracy. Quantitative benchmarks show that C-PATH achieves superior performance in GPT-rewritten conversational datasets, significantly outperforming domain-specific baselines. C-PATH represents a step forward in the development of user-centric, accessible, and accurate AI tools for digital health assistance and triage.
Modular Federated Learning: A Meta-Framework Perspective
May 13, 2025Federated Learning (FL) enables distributed machine learning training while preserving privacy, representing a paradigm shift for data-sensitive and decentralized environments. Despite its rapid advancements, FL remains a complex and multifaceted field, requiring a structured understanding of its methodologies, challenges, and applications. In this survey, we introduce a meta-framework perspective, conceptualising FL as a composition of modular components that systematically address core aspects such as communication, optimisation, security, and privacy. We provide a historical contextualisation of FL, tracing its evolution from distributed optimisation to modern distributed learning paradigms. Additionally, we propose a novel taxonomy distinguishing Aggregation from Alignment, introducing the concept of alignment as a fundamental operator alongside aggregation. To bridge theory with practice, we explore available FL frameworks in Python, facilitating real-world implementation. Finally, we systematise key challenges across FL sub-fields, providing insights into open research questions throughout the meta-framework modules. By structuring FL within a meta-framework of modular components and emphasising the dual role of Aggregation and Alignment, this survey provides a holistic and adaptable foundation for understanding and advancing FL research and deployment.
OrbitZoo: Multi-Agent Reinforcement Learning Environment for Orbital Dynamics
Apr 05, 2025
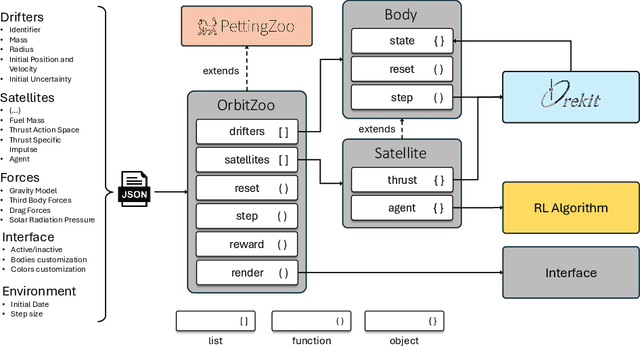


The increasing number of satellites and orbital debris has made space congestion a critical issue, threatening satellite safety and sustainability. Challenges such as collision avoidance, station-keeping, and orbital maneuvering require advanced techniques to handle dynamic uncertainties and multi-agent interactions. Reinforcement learning (RL) has shown promise in this domain, enabling adaptive, autonomous policies for space operations; however, many existing RL frameworks rely on custom-built environments developed from scratch, which often use simplified models and require significant time to implement and validate the orbital dynamics, limiting their ability to fully capture real-world complexities. To address this, we introduce OrbitZoo, a versatile multi-agent RL environment built on a high-fidelity industry standard library, that enables realistic data generation, supports scenarios like collision avoidance and cooperative maneuvers, and ensures robust and accurate orbital dynamics. The environment is validated against a real satellite constellation, Starlink, achieving a Mean Absolute Percentage Error (MAPE) of 0.16% compared to real-world data. This validation ensures reliability for generating high-fidelity simulations and enabling autonomous and independent satellite operations.
Follow-the-Regularized-Leader with Adversarial Constraints
Mar 17, 2025Constrained Online Convex Optimization (COCO) can be seen as a generalization of the standard Online Convex Optimization (OCO) framework. At each round, a cost function and constraint function are revealed after a learner chooses an action. The goal is to minimize both the regret and cumulative constraint violation (CCV) against an adaptive adversary. We show for the first time that is possible to obtain the optimal $O(\sqrt{T})$ bound on both regret and CCV, improving the best known bounds of $O \left( \sqrt{T} \right)$ and $\~{O} \left( \sqrt{T} \right)$ for the regret and CCV, respectively.
Advancing Solutions for the Three-Body Problem Through Physics-Informed Neural Networks
Mar 06, 2025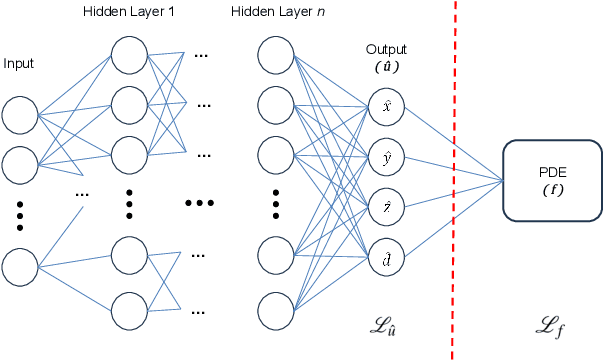


First formulated by Sir Isaac Newton in his work "Philosophiae Naturalis Principia Mathematica", the concept of the Three-Body Problem was put forth as a study of the motion of the three celestial bodies within the Earth-Sun-Moon system. In a generalized definition, it seeks to predict the motion for an isolated system composed of three point masses freely interacting under Newton's law of universal attraction. This proves to be analogous to a multitude of interactions between celestial bodies, and thus, the problem finds applicability within the studies of celestial mechanics. Despite numerous attempts by renowned physicists to solve it throughout the last three centuries, no general closed-form solutions have been reached due to its inherently chaotic nature for most initial conditions. Current state-of-the-art solutions are based on two approaches, either numerical high-precision integration or machine learning-based. Notwithstanding the breakthroughs of neural networks, these present a significant limitation, which is their ignorance of any prior knowledge of the chaotic systems presented. Thus, in this work, we propose a novel method that utilizes Physics-Informed Neural Networks (PINNs). These deep neural networks are able to incorporate any prior system knowledge expressible as an Ordinary Differential Equation (ODE) into their learning processes as a regularizing agent. Our findings showcase that PINNs surpass current state-of-the-art machine learning methods with comparable prediction quality. Despite a better prediction quality, the usability of numerical integrators suffers due to their prohibitively high computational cost. These findings confirm that PINNs are both effective and time-efficient open-form solvers of the Three-Body Problem that capitalize on the extensive knowledge we hold of classical mechanics.
* 14 pages, 25 figures, 3 tables. 75th International Astronautical Congress (IAC), Milan, Italy, 14-18 October
Generalizing Trilateration: Approximate Maximum Likelihood Estimator for Initial Orbit Determination in Low-Earth Orbit
Jul 21, 2024



With the increase in the number of active satellites and space debris in orbit, the problem of initial orbit determination (IOD) becomes increasingly important, demanding a high accuracy. Over the years, different approaches have been presented such as filtering methods (for example, Extended Kalman Filter), differential algebra or solving Lambert's problem. In this work, we consider a setting of three monostatic radars, where all available measurements are taken approximately at the same instant. This follows a similar setting as trilateration, a state-of-the-art approach, where each radar is able to obtain a single measurement of range and range-rate. Differently, and due to advances in Multiple-Input Multiple-Output (MIMO) radars, we assume that each location is able to obtain a larger set of range, angle and Doppler shift measurements. Thus, our method can be understood as an extension of trilateration leveraging more recent technology and incorporating additional data. We formulate the problem as a Maximum Likelihood Estimator (MLE), which for some number of observations is asymptotically unbiased and asymptotically efficient. Through numerical experiments, we demonstrate that our method attains the same accuracy as the trilateration method for the same number of measurements and offers an alternative and generalization, returning a more accurate estimation of the satellite's state vector, as the number of available measurements increases.
TS40K: a 3D Point Cloud Dataset of Rural Terrain and Electrical Transmission System
May 22, 2024



Research on supervised learning algorithms in 3D scene understanding has risen in prominence and witness great increases in performance across several datasets. The leading force of this research is the problem of autonomous driving followed by indoor scene segmentation. However, openly available 3D data on these tasks mainly focuses on urban scenarios. In this paper, we propose TS40K, a 3D point cloud dataset that encompasses more than 40,000 Km on electrical transmission systems situated in European rural terrain. This is not only a novel problem for the research community that can aid in the high-risk mission of power-grid inspection, but it also offers 3D point clouds with distinct characteristics from those in self-driving and indoor 3D data, such as high point-density and no occlusion. In our dataset, each 3D point is labeled with 1 out of 22 annotated classes. We evaluate the performance of state-of-the-art methods on our dataset concerning 3D semantic segmentation and 3D object detection. Finally, we provide a comprehensive analysis of the results along with key challenges such as using labels that were not originally intended for learning tasks.
PeersimGym: An Environment for Solving the Task Offloading Problem with Reinforcement Learning
Apr 02, 2024Task offloading, crucial for balancing computational loads across devices in networks such as the Internet of Things, poses significant optimization challenges, including minimizing latency and energy usage under strict communication and storage constraints. While traditional optimization falls short in scalability; and heuristic approaches lack in achieving optimal outcomes, Reinforcement Learning (RL) offers a promising avenue by enabling the learning of optimal offloading strategies through iterative interactions. However, the efficacy of RL hinges on access to rich datasets and custom-tailored, realistic training environments. To address this, we introduce PeersimGym, an open-source, customizable simulation environment tailored for developing and optimizing task offloading strategies within computational networks. PeersimGym supports a wide range of network topologies and computational constraints and integrates a \textit{PettingZoo}-based interface for RL agent deployment in both solo and multi-agent setups. Furthermore, we demonstrate the utility of the environment through experiments with Deep Reinforcement Learning agents, showcasing the potential of RL-based approaches to significantly enhance offloading strategies in distributed computing settings. PeersimGym thus bridges the gap between theoretical RL models and their practical applications, paving the way for advancements in efficient task offloading methodologies.