 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Trilateration: Approximate Maximum Likelihood Estimator for Initial Orbit Determination in Low-Earth Orbit
Jul 21, 2024



With the increase in the number of active satellites and space debris in orbit, the problem of initial orbit determination (IOD) becomes increasingly important, demanding a high accuracy. Over the years, different approaches have been presented such as filtering methods (for example, Extended Kalman Filter), differential algebra or solving Lambert's problem. In this work, we consider a setting of three monostatic radars, where all available measurements are taken approximately at the same instant. This follows a similar setting as trilateration, a state-of-the-art approach, where each radar is able to obtain a single measurement of range and range-rate. Differently, and due to advances in Multiple-Input Multiple-Output (MIMO) radars, we assume that each location is able to obtain a larger set of range, angle and Doppler shift measurements. Thus, our method can be understood as an extension of trilateration leveraging more recent technology and incorporating additional data. We formulate the problem as a Maximum Likelihood Estimator (MLE), which for some number of observations is asymptotically unbiased and asymptotically efficient. Through numerical experiments, we demonstrate that our method attains the same accuracy as the trilateration method for the same number of measurements and offers an alternative and generalization, returning a more accurate estimation of the satellite's state vector, as the number of available measurements increases.
One-Shot Initial Orbit Determination in Low-Earth Orbit
Dec 20, 2023



Due to the importance of satellites for society and the exponential increase in the number of objects in orbit, it is important to accurately determine the state (e.g., position and velocity) of these Resident Space Objects (RSOs) at any time and in a timely manner. State-of-the-art methodologies for initial orbit determination consist of Kalman-type filters that process sequential data over time and return the state and associated uncertainty of the object, as is the case of the Extended Kalman Filter (EKF). However, these methodologies are dependent on a good initial guess for the state vector and usually simplify the physical dynamical model, due to the difficulty of precisely modeling perturbative forces, such as atmospheric drag and solar radiation pressure. Other approaches do not require assumptions about the dynamical system, such as the trilateration method, and require simultaneous measurements, such as three measurements of range and range-rate for the particular case of trilateration. We consider the same setting of simultaneous measurements (one-shot), resorting to time delay and Doppler shift measurements. Based on recent advancements in the problem of moving target localization for sonar multistatic systems, we are able to formulate the problem of initial orbit determination as a Weighted Least Squares. With this approach, we are able to directly obtain the state of the object (position and velocity) and the associated covariance matrix from the Fisher's Information Matrix (FIM). We demonstrate that, for small noise, our estimator is able to attain the Cram\'er-Rao Lower Bound accuracy, i.e., the accuracy attained by the unbiased estimator with minimum variance. We also numerically demonstrate that our estimator is able to attain better accuracy on the state estimation than the trilateration method and returns a smaller uncertainty associated with the estimation.
Extreme Multilabel Classification for Specialist Doctor Recommendation with Implicit Feedback and Limited Patient Metadata
Aug 21, 2023

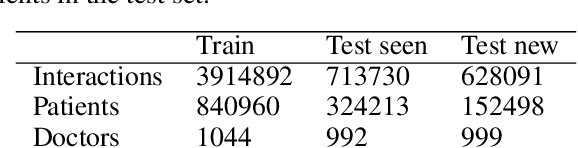

Recommendation Systems (RS) are often used to address the issue of medical doctor referrals. However, these systems require access to patient feedback and medical records, which may not always be available in real-world scenarios. Our research focuses on medical referrals and aims to predict recommendations in different specialties of physicians for both new patients and those with a consultation history. We use Extreme Multilabel Classification (XML), commonly employed in text-based classification tasks, to encode available features and explore different scenarios. While its potential for recommendation tasks has often been suggested, this has not been thoroughly explored in the literature. Motivated by the doctor referral case, we show how to recast a traditional recommender setting into a multilabel classification problem that current XML methods can solve. Further, we propose a unified model leveraging patient history across different specialties. Compared to state-of-the-art RS using the same features, our approach consistently improves standard recommendation metrics up to approximately $10\%$ for patients with a previous consultation history. For new patients, XML proves better at exploiting available features, outperforming the benchmark in favorable scenarios, with particular emphasis on recall metrics. Thus, our approach brings us one step closer to creating more effective and personalized doctor referral systems. Additionally, it highlights XML as a promising alternative to current hybrid or content-based RS, while identifying key aspects to take into account when using XML for recommendation tasks.
Probabilistic Registration for Gaussian Process 3D shape modelling in the presence of extensive missing data
Mar 26, 2022

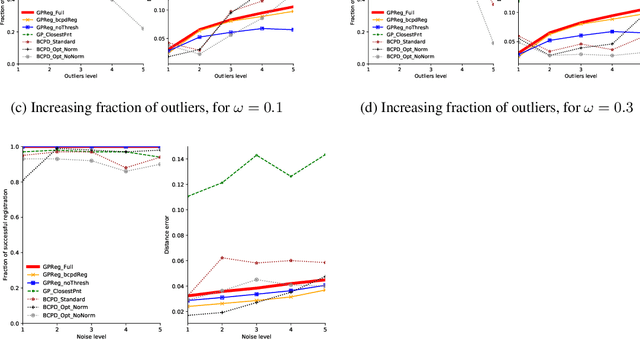

Gaussian Processes are a powerful tool for shape modelling. While the existing methods on this area prove to work well for the general case of the human head, when looking at more detailed and deformed data, with a high prevalence of missing data, such as the ears, the results are not satisfactory. In order to overcome this, we formulate the shape fitting problem as a multi-annotator Gaussian Process Regression and establish a parallel with the standard probabilistic registration. The achieved method GPReg shows better performance when dealing with extensive areas of missing data when compared to a state-of-the-art registration method and the current approach for registration with GP.
Ranking with Confidence for Large Scale Comparison Data
Feb 03, 2022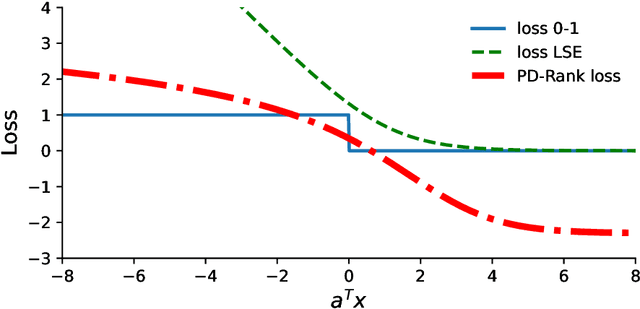
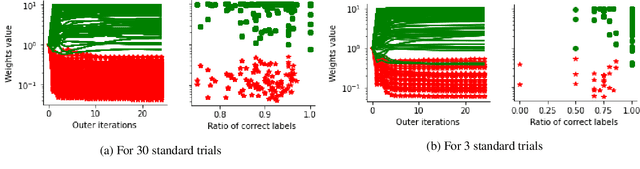

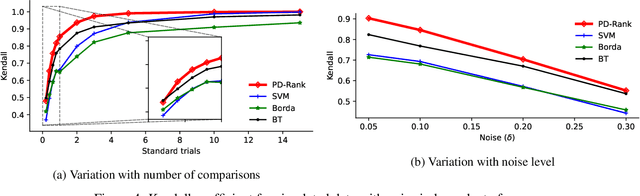
In this work, we leverage a generative data model considering comparison noise to develop a fast, precise, and informative ranking algorithm from pairwise comparisons that produces a measure of confidence on each comparison. The problem of ranking a large number of items from noisy and sparse pairwise comparison data arises in diverse applications, like ranking players in online games, document retrieval or ranking human perceptions. Although different algorithms are available, we need fast, large-scale algorithms whose accuracy degrades gracefully when the number of comparisons is too small. Fitting our proposed model entails solving a non-convex optimization problem, which we tightly approximate by a sum of quasi-convex functions and a regularization term. Resorting to an iterative reweighted minimization and the Primal-Dual Hybrid Gradient method, we obtain PD-Rank, achieving a Kendall tau 0.1 higher than all comparing methods, even for 10\% of wrong comparisons in simulated data matching our data model, and leading in accuracy if data is generated according to the Bradley-Terry model, in both cases faster by one order of magnitude, in seconds. In real data, PD-Rank requires less computational time to achieve the same Kendall tau than active learning methods.
Range and Bearing Data Fusion for Precise Convex Network Localization
Oct 01, 2021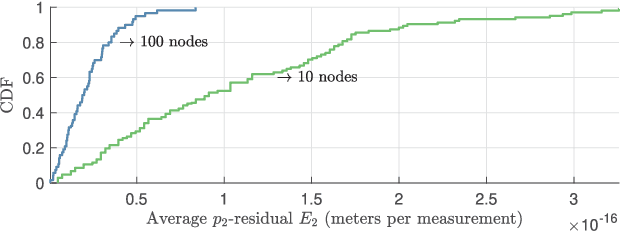
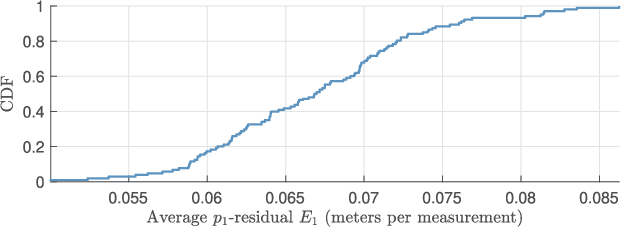
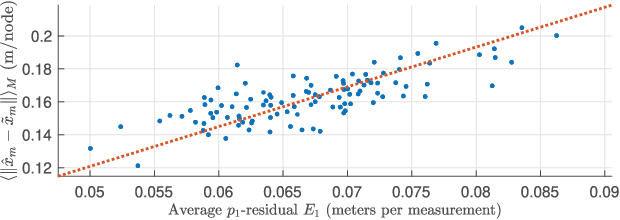
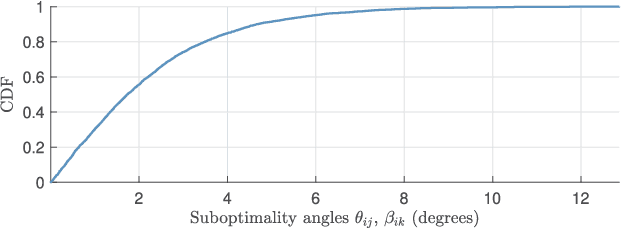
Hybrid localization in GNSS-challenged environments using measured ranges and angles is becoming increasingly popular, in particular with the advent of multimodal communication systems. Here, we address the hybrid network localization problem using ranges and bearings to jointly determine the positions of a number of agents through a single maximum-likelihood (ML) optimization problem that seamlessly fuses all the available pairwise range and angle measurements. We propose a tight convex surrogate to the ML estimator, we examine practical measures for the accuracy of the relaxation, and we comprehensively characterize its behavior in simulation. We found that our relaxation outperforms a state of the art SDP relaxation by one order of magnitude in terms of localization error, and is amenable to much more lightweight solution algorithms.
RANSIP : From noisy point clouds to complete ear models, unsupervised
Aug 22, 2020
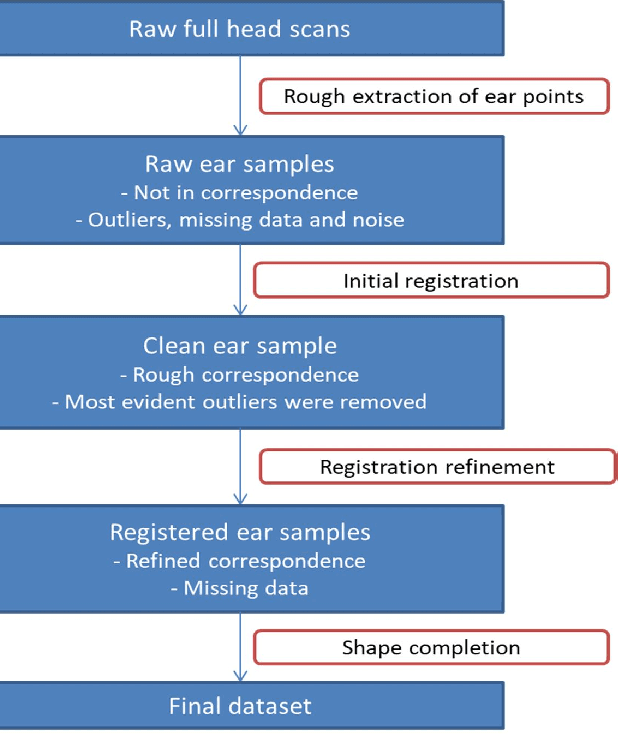

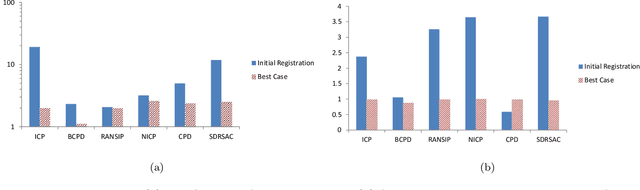
Ears are a particularly difficult region of the human face to model, not only due to the non-rigid deformations existing between shapes but also to the challenges in processing the retrieved data. The first step towards obtaining a good model is to have complete scans in correspondence, but these usually present a higher amount of occlusions, noise and outliers when compared to most face regions, thus requiring a specific procedure. Therefore, we propose a complete pipeline taking as input unordered 3D point clouds with the aforementioned problems, and producing as output a dataset in correspondence, with completion of the missing data. We provide a comparison of several state-of-the-art registration methods and propose a new approach for one of the steps of the pipeline, with better performance for our data.