 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENEOnet: Statistical analysis supporting explainability and trustworthiness
Mar 12, 2025


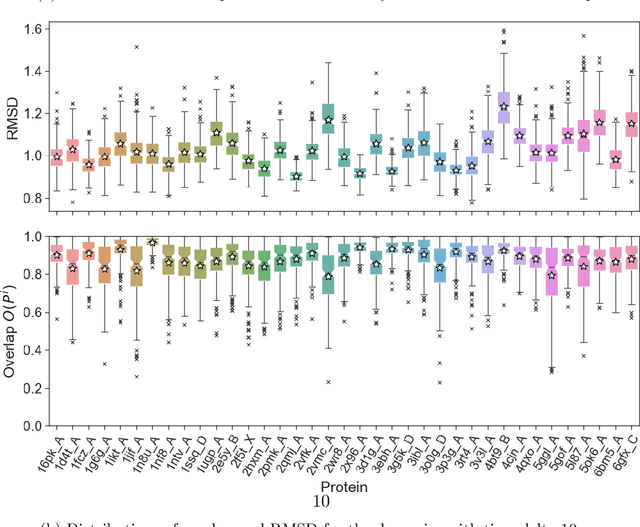
Group Equivariant Non-Expansive Operators (GENEOs) have emerged as mathematical tools for constructing networks for Machine Learning and Artificial Intelligence. Recent findings suggest that such models can be inserted within the domain of eXplainable Artificial Intelligence (XAI) due to their inherent interpretability. In this study, we aim to verify this claim with respect to GENEOnet, a GENEO network developed for an application in computational biochemistry by employing various statistical analyses and experiments. Such experiments first allow us to perform a sensitivity analysis on GENEOnet's parameters to test their significance. Subsequently, we show that GENEOnet exhibits a significantly higher proportion of equivariance compared to other methods. Lastly, we demonstrate that GENEOnet is on average robust to perturbations arising from molecular dynamics. These results collectively serve as proof of the explainability, trustworthiness, and robustness of GENEOnet and confirm the beneficial use of GENEOs in the context of Trustworthy Artificial Intelligence.
Enhancing Power Grid Inspections with Machine Learning
Feb 18, 2025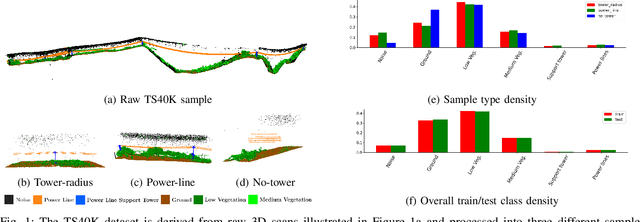



Ensuring the safety and reliability of power grids is critical as global energy demands continue to rise. Traditional inspection methods, such as manual observations or helicopter surveys, are resource-intensive and lack scalability. This paper explores the use of 3D computer vision to automate power grid inspections, utilizing the TS40K dataset -- a high-density, annotated collection of 3D LiDAR point clouds. By concentrating on 3D semantic segmentation, our approach addresses challenges like class imbalance and noisy data to enhance the detection of critical grid components such as power lines and towers. The benchmark results indicate significant performance improvements, with IoU scores reaching 95.53% for the detection of power lines using transformer-based models. Our findings illustrate the potential for integrating ML into grid maintenance workflows, increasing efficiency and enabling proactive risk management strategies.
TS40K: a 3D Point Cloud Dataset of Rural Terrain and Electrical Transmission System
May 22, 2024



Research on supervised learning algorithms in 3D scene understanding has risen in prominence and witness great increases in performance across several datasets. The leading force of this research is the problem of autonomous driving followed by indoor scene segmentation. However, openly available 3D data on these tasks mainly focuses on urban scenarios. In this paper, we propose TS40K, a 3D point cloud dataset that encompasses more than 40,000 Km on electrical transmission systems situated in European rural terrain. This is not only a novel problem for the research community that can aid in the high-risk mission of power-grid inspection, but it also offers 3D point clouds with distinct characteristics from those in self-driving and indoor 3D data, such as high point-density and no occlusion. In our dataset, each 3D point is labeled with 1 out of 22 annotated classes. We evaluate the performance of state-of-the-art methods on our dataset concerning 3D semantic segmentation and 3D object detection. Finally, we provide a comprehensive analysis of the results along with key challenges such as using labels that were not originally intended for learning tasks.
Achieving Constraints in Neural Networks: A Stochastic Augmented Lagrangian Approach
Oct 25, 2023


Regularizing Deep Neural Networks (DNNs) is essential for improving generalizability and preventing overfitting. Fixed penalty methods, though common, lack adaptability and suffer from hyperparameter sensitivity. In this paper, we propose a novel approach to DNN regularization by framing the training process as a constrained optimization problem. Where the data fidelity term is the minimization objective and the regularization terms serve as constraints. Then, we employ the Stochastic Augmented Lagrangian (SAL) method to achieve a more flexible and efficient regularization mechanism. Our approach extends beyond black-box regularization, demonstrating significant improvements in white-box models, where weights are often subject to hard constraints to ensure interpretability. Experimental results on image-based classification on MNIST, CIFAR10, and CIFAR100 datasets validate the effectiveness of our approach. SAL consistently achieves higher Accuracy while also achieving better constraint satisfaction, thus showcasing its potential for optimizing DNNs under constrained settings.
Low-Resource White-Box Semantic Segmentation of Supporting Towers on 3D Point Clouds via Signature Shape Identification
Jun 13, 2023



Research in 3D semantic segmentation has been increasing performance metrics, like the IoU, by scaling model complexity and computational resources, leaving behind researchers and practitioners that (1) cannot access the necessary resources and (2) do need transparency on the model decision mechanisms. In this paper, we propose SCENE-Net, a low-resource white-box model for 3D point cloud semantic segmentation. SCENE-Net identifies signature shapes on the point cloud via group equivariant non-expansive operators (GENEOs), providing intrinsic geometric interpretability. Our training time on a laptop is 85~min, and our inference time is 20~ms. SCENE-Net has 11 trainable geometrical parameters and requires fewer data than black-box models. SCENE--Net offers robustness to noisy labeling and data imbalance and has comparable IoU to state-of-the-art methods. With this paper, we release a 40~000 Km labeled dataset of rural terrain point clouds and our code implementation.
Probabilistic Registration for Gaussian Process 3D shape modelling in the presence of extensive missing data
Mar 26, 2022

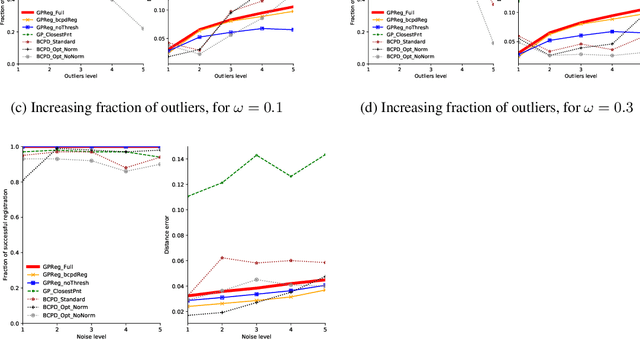

Gaussian Processes are a powerful tool for shape modelling. While the existing methods on this area prove to work well for the general case of the human head, when looking at more detailed and deformed data, with a high prevalence of missing data, such as the ears, the results are not satisfactory. In order to overcome this, we formulate the shape fitting problem as a multi-annotator Gaussian Process Regression and establish a parallel with the standard probabilistic registration. The achieved method GPReg shows better performance when dealing with extensive areas of missing data when compared to a state-of-the-art registration method and the current approach for registration with GP.
GENEOnet: A new machine learning paradigm based on Group Equivariant Non-Expansive Operators. An application to protein pocket detection
Jan 31, 2022



Nowadays there is a big spotlight cast on the development of techniques of explainable machine learning. Here we introduce a new computational paradigm based on Group Equivariant Non-Expansive Operators, that can be regarded as the product of a rising mathematical theory of information-processing observers. This approach, that can be adjusted to different situations, may have many advantages over other common tools, like Neural Networks, such as: knowledge injection and information engineering, selection of relevant features, small number of parameters and higher transparency. We chose to test our method, called GENEOnet, on a key problem in drug design: detecting pockets on the surface of proteins that can host ligands. Experimental results confirmed that our method works well even with a quite small training set, providing thus a great computational advantage, while the final comparison with other state-of-the-art methods shows that GENEOnet provides better or comparable results in terms of accuracy.
Emotion pattern detection on facial videos using functional statistics
Mar 01, 2021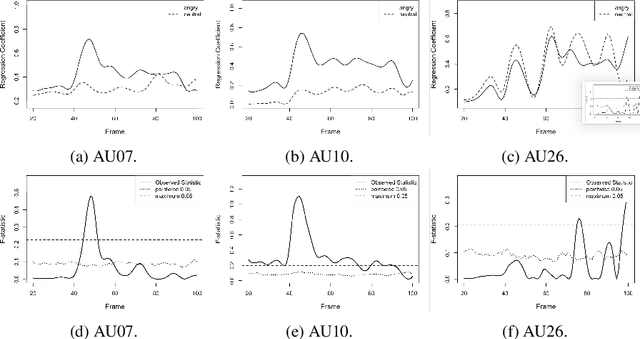
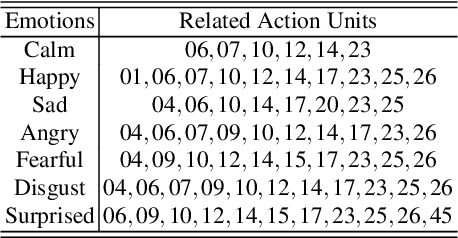
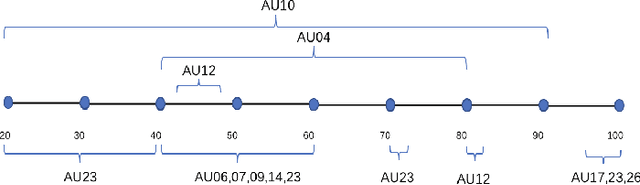
There is an increasing scientific interest in automatically analysing and understanding human behavior, with particular reference to the evolution of facial expressions and the recognition of the corresponding emotions. In this paper we propose a technique based on Functional ANOVA to extract significant patterns of face muscles movements, in order to identify the emotions expressed by actors in recorded videos. We determine if there are time-related differences on expressions among emotional groups by using a functional F-test. Such results are the first step towards the construction of a reliable automatic emotion recognition system
RANSIP : From noisy point clouds to complete ear models, unsupervised
Aug 22, 2020
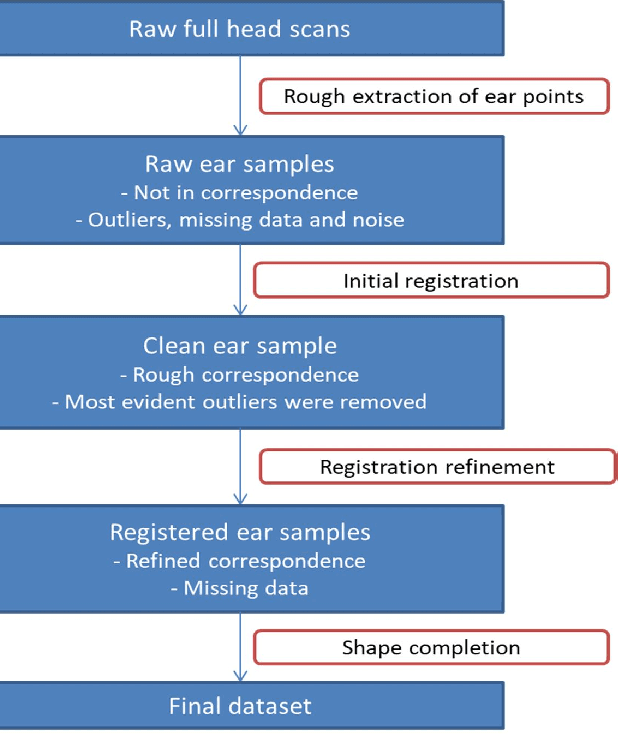

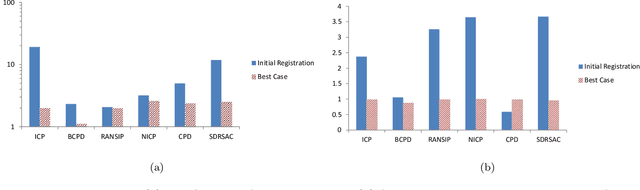
Ears are a particularly difficult region of the human face to model, not only due to the non-rigid deformations existing between shapes but also to the challenges in processing the retrieved data. The first step towards obtaining a good model is to have complete scans in correspondence, but these usually present a higher amount of occlusions, noise and outliers when compared to most face regions, thus requiring a specific procedure. Therefore, we propose a complete pipeline taking as input unordered 3D point clouds with the aforementioned problems, and producing as output a dataset in correspondence, with completion of the missing data. We provide a comparison of several state-of-the-art registration methods and propose a new approach for one of the steps of the pipeline, with better performance for our data.