 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassive Open-Vocabulary Keyword Spotting
Jun 09, 2026Automatic speech recognition systems have been shown to under-perform when it comes to transcribing words rarely seen in the training data, namely specialized terminology. Open-vocabulary keyword spotting, combined with contextual biasing, has been shown to mitigate this issue. However, existing systems can only handle glossaries of a few hundred terms without becoming an infeasible bottleneck. We propose a system that stores features with a memory footprint up to 128 times smaller than a comparable baseline and allows users to process massive databases while remaining open-vocabulary. Without fine-tuning the speech recognition model, our system achieves a comparable entity recall as uncompressed solutions, even in languages not seen during training.
Multi-Target Cross-Lingual Summarization: a novel task and a language-neutral approach
Oct 01, 2024
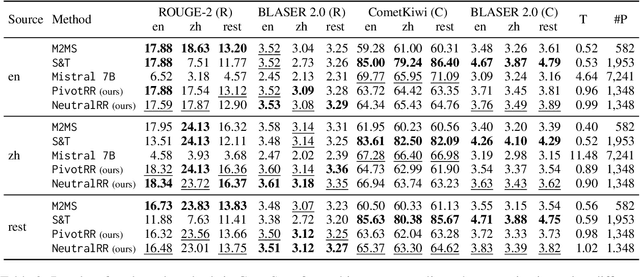
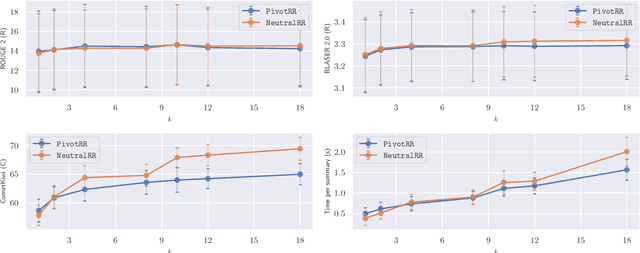
Cross-lingual summarization aims to bridge language barriers by summarizing documents in different languages. However, ensuring semantic coherence across languages is an overlooked challenge and can be critical in several contexts. To fill this gap, we introduce multi-target cross-lingual summarization as the task of summarizing a document into multiple target languages while ensuring that the produced summaries are semantically similar. We propose a principled re-ranking approach to this problem and a multi-criteria evaluation protocol to assess semantic coherence across target languages, marking a first step that will hopefully stimulate further research on this problem.
Supervising the Centroid Baseline for Extractive Multi-Document Summarization
Nov 29, 2023



The centroid method is a simple approach for extractive multi-document summarization and many improvements to its pipeline have been proposed. We further refine it by adding a beam search process to the sentence selection and also a centroid estimation attention model that leads to improved results. We demonstrate this in several multi-document summarization datasets, including in a multilingual scenario.
Improving abstractive summarization with energy-based re-ranking
Nov 07, 2022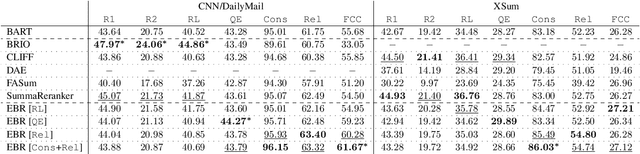

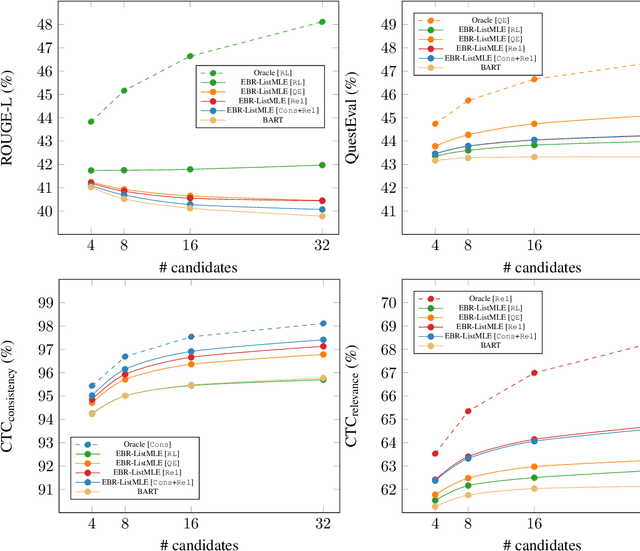

Current abstractive summarization systems present important weaknesses which prevent their deployment in real-world applications, such as the omission of relevant information and the generation of factual inconsistencies (also known as hallucinations). At the same time, automatic evaluation metrics such as CTC scores have been recently proposed that exhibit a higher correlation with human judgments than traditional lexical-overlap metrics such as ROUGE. In this work, we intend to close the loop by leveraging the recent advances in summarization metrics to create quality-aware abstractive summarizers. Namely, we propose an energy-based model that learns to re-rank summaries according to one or a combination of these metrics. We experiment using several metrics to train our energy-based re-ranker and show that it consistently improves the scores achieved by the predicted summaries. Nonetheless, human evaluation results show that the re-ranking approach should be used with care for highly abstractive summaries, as the available metrics are not yet sufficiently reliable for this purpose.
Simplifying Multilingual News Clustering Through Projection From a Shared Space
Apr 28, 2022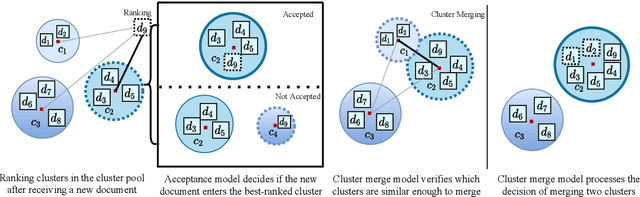
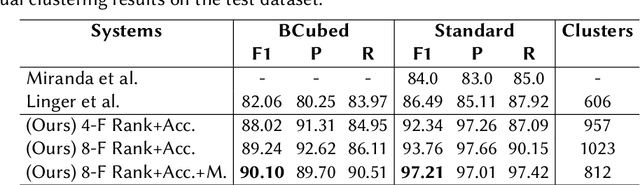
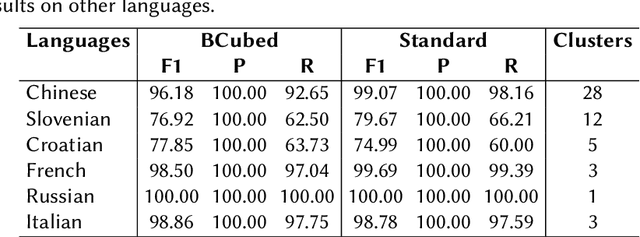
The task of organizing and clustering multilingual news articles for media monitoring is essential to follow news stories in real time. Most approaches to this task focus on high-resource languages (mostly English), with low-resource languages being disregarded. With that in mind, we present a much simpler online system that is able to cluster an incoming stream of documents without depending on language-specific features. We empirically demonstrate that the use of multilingual contextual embeddings as the document representation significantly improves clustering quality. We challenge previous crosslingual approaches by removing the precondition of building monolingual clusters. We model the clustering process as a set of linear classifiers to aggregate similar documents, and correct closely-related multilingual clusters through merging in an online fashion. Our system achieves state-of-the-art results on a multilingual news stream clustering dataset, and we introduce a new evaluation for zero-shot news clustering in multiple languages. We make our code available as open-source.
* 10 pages, 1 figure
An NLP Solution to Foster the Use of Information in Electronic Health Records for Efficiency in Decision-Making in Hospital Care
Feb 24, 2022
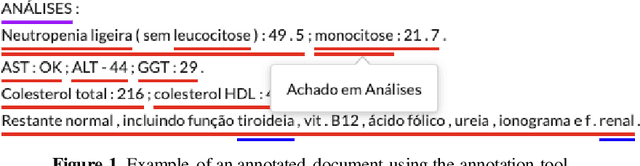
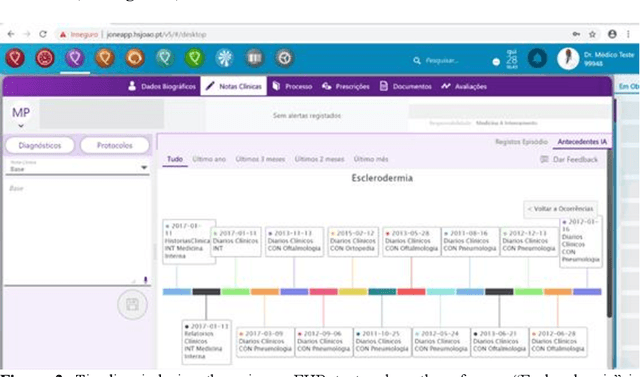
The project aimed to define the rules and develop a technological solution to automatically identify a set of attributes within free-text clinical records written in Portuguese. The first application developed and implemented on this basis was a structured summary of a patient's clinical history, including previous diagnoses and procedures, usual medication, and relevant characteristics or conditions for clinical decisions, such as allergies, being under anticoagulant therapy, etc. The project's goal was achieved by a multidisciplinary team that included clinicians, epidemiologists, computational linguists, machine learning researchers and software engineers, bringing together the expertise and perspectives of a public hospital, the university and the private sector. Relevant benefits to users and patients are related with facilitated access to the patient's history, which translates into exhaustiveness in apprehending the patient's clinical past and efficiency due to time saving.
Priberam at MESINESP Multi-label Classification of Medical Texts Task
May 12, 2021

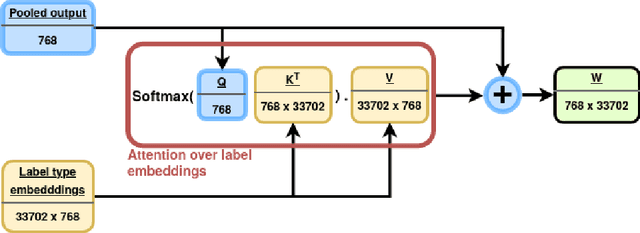
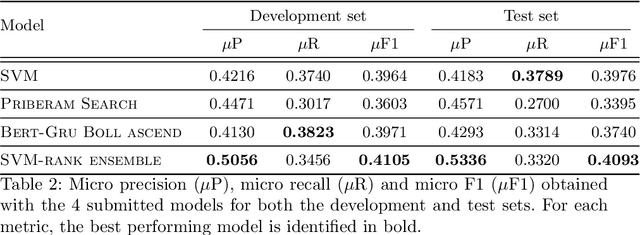
Medical articles provide current state of the art treatments and diagnostics to many medical practitioners and professionals. Existing public databases such as MEDLINE contain over 27 million articles, making it difficult to extract relevant content without the use of efficient search engines. Information retrieval tools are crucial in order to navigate and provide meaningful recommendations for articles and treatments. Classifying these articles into broader medical topics can improve the retrieval of related articles. The set of medical labels considered for the MESINESP task is on the order of several thousands of labels (DeCS codes), which falls under the extreme multi-label classification problem. The heterogeneous and highly hierarchical structure of medical topics makes the task of manually classifying articles extremely laborious and costly. It is, therefore, crucial to automate the process of classification. Typical machine learning algorithms become computationally demanding with such a large number of labels and achieving better recall on such datasets becomes an unsolved problem. This work presents Priberam's participation at the BioASQ task Mesinesp. We address the large multi-label classification problem through the use of four different models: a Support Vector Machine (SVM), a customised search engine (Priberam Search), a BERT based classifier, and a SVM-rank ensemble of all the previous models. Results demonstrate that all three individual models perform well and the best performance is achieved by their ensemble, granting Priberam the 6th place in the present challenge and making it the 2nd best team.
Priberam Labs at the NTCIR-15 SHINRA2020-ML: Classification Task
May 12, 2021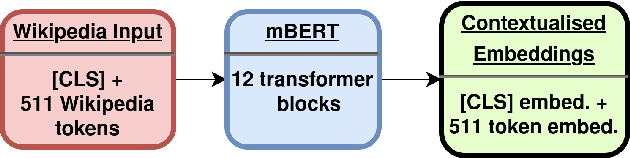
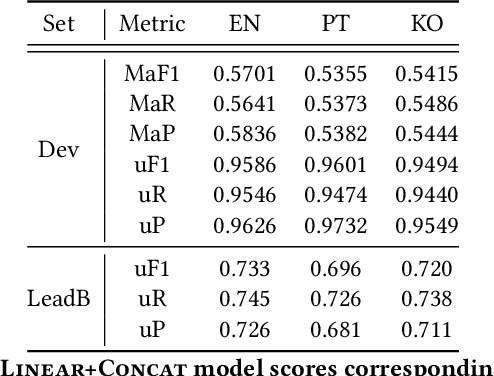
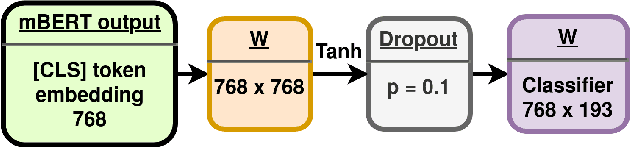
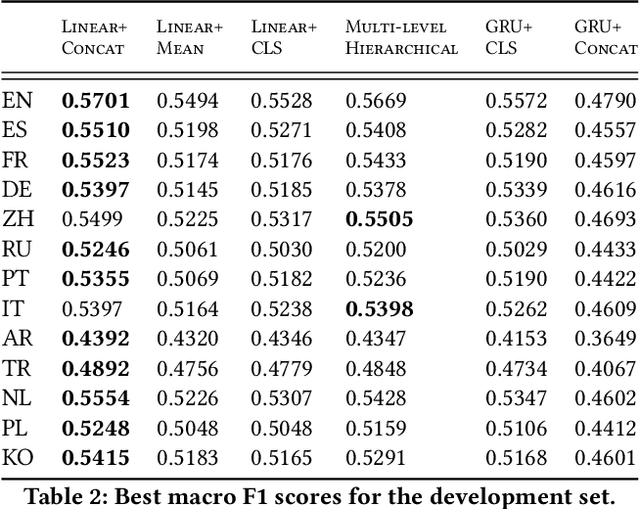
Wikipedia is an online encyclopedia available in 285 languages. It composes an extremely relevant Knowledge Base (KB), which could be leveraged by automatic systems for several purposes. However, the structure and organisation of such information are not prone to automatic parsing and understanding and it is, therefore, necessary to structure this knowledge. The goal of the current SHINRA2020-ML task is to leverage Wikipedia pages in order to categorise their corresponding entities across 268 hierarchical categories, belonging to the Extended Named Entity (ENE) ontology. In this work, we propose three distinct models based on the contextualised embeddings yielded by Multilingual BERT. We explore the performances of a linear layer with and without explicit usage of the ontology's hierarchy, and a Gated Recurrent Units (GRU) layer. We also test several pooling strategies to leverage BERT's embeddings and selection criteria based on the labels' scores. We were able to achieve good performance across a large variety of languages, including those not seen during the fine-tuning process (zero-shot languages).
Jointly Extracting and Compressing Documents with Summary State Representations
Apr 05, 2019
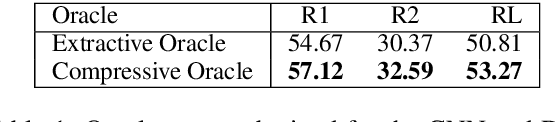
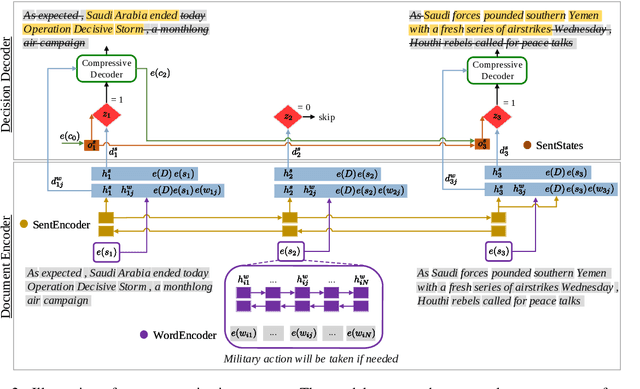

We present a new neural model for text summarization that first extracts sentences from a document and then compresses them. The proposed model offers a balance that sidesteps the difficulties in abstractive methods while generating more concise summaries than extractive methods. In addition, our model dynamically determines the length of the output summary based on the gold summaries it observes during training and does not require length constraints typical to extractive summarization. The model achieves state-of-the-art results on the CNN/DailyMail and Newsroom datasets, improving over current extractive and abstractive methods. Human evaluations demonstrate that our model generates concise and informative summaries. We also make available a new dataset of oracle compressive summaries derived automatically from the CNN/DailyMail reference summaries.
Automated Fact Checking in the News Room
Apr 03, 2019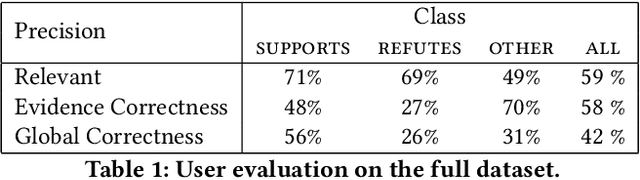
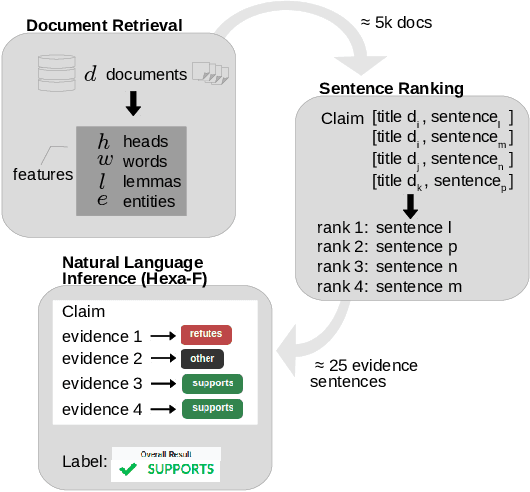
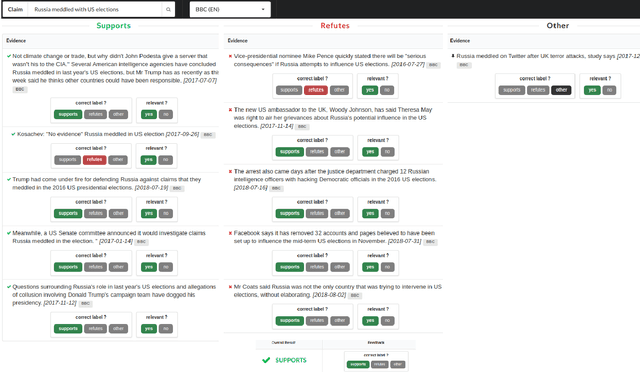
Fact checking is an essential task in journalism; its importance has been highlighted due to recently increased concerns and efforts in combating misinformation. In this paper, we present an automated fact-checking platform which given a claim, it retrieves relevant textual evidence from a document collection, predicts whether each piece of evidence supports or refutes the claim, and returns a final verdict. We describe the architecture of the system and the user interface, focusing on the choices made to improve its user-friendliness and transparency. We conduct a user study of the fact-checking platform in a journalistic setting: we integrated it with a collection of news articles and provide an evaluation of the platform using feedback from journalists in their workflow. We found that the predictions of our platform were correct 58\% of the time, and 59\% of the returned evidence was relevant.