 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLUE: Neural Networks Calibration via Learning Uncertainty-Error alignment
May 28, 2025



Reliable uncertainty estimation is critical for deploying neural networks (NNs) in real-world applications. While existing calibration techniques often rely on post-hoc adjustments or coarse-grained binning methods, they remain limited in scalability, differentiability, and generalization across domains. In this work, we introduce CLUE (Calibration via Learning Uncertainty-Error Alignment), a novel approach that explicitly aligns predicted uncertainty with observed error during training, grounded in the principle that well-calibrated models should produce uncertainty estimates that match their empirical loss. CLUE adopts a novel loss function that jointly optimizes predictive performance and calibration, using summary statistics of uncertainty and loss as proxies. The proposed method is fully differentiable, domain-agnostic, and compatible with standard training pipelines. Through extensive experiments on vision, regression, and language modeling tasks, including out-of-distribution and domain-shift scenarios, we demonstrate that CLUE achieves superior calibration quality and competitive predictive performance with respect to state-of-the-art approaches without imposing significant computational overhead.
Error-Driven Uncertainty Aware Training
May 02, 2024



Neural networks are often overconfident about their predictions, which undermines their reliability and trustworthiness. In this work, we present a novel technique, named Error-Driven Uncertainty Aware Training (EUAT), which aims to enhance the ability of neural models to estimate their uncertainty correctly, namely to be highly uncertain when they output inaccurate predictions and low uncertain when their output is accurate. The EUAT approach operates during the model's training phase by selectively employing two loss functions depending on whether the training examples are correctly or incorrectly predicted by the model. This allows for pursuing the twofold goal of i) minimizing model uncertainty for correctly predicted inputs and ii) maximizing uncertainty for mispredicted inputs, while preserving the model's misprediction rate. We evaluate EUAT using diverse neural models and datasets in the image recognition domains considering both non-adversarial and adversarial settings. The results show that EUAT outperforms existing approaches for uncertainty estimation (including other uncertainty-aware training techniques, calibration, ensembles, and DEUP) by providing uncertainty estimates that not only have higher quality when evaluated via statistical metrics (e.g., correlation with residuals) but also when employed to build binary classifiers that decide whether the model's output can be trusted or not and under distributional data shifts.
Hyper-parameter Tuning for Adversarially Robust Models
Apr 05, 2023
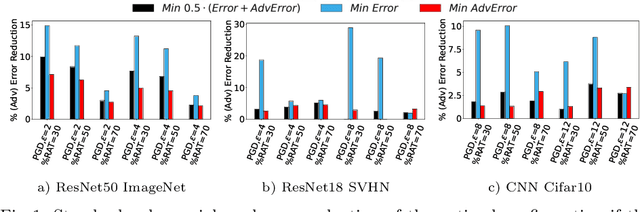
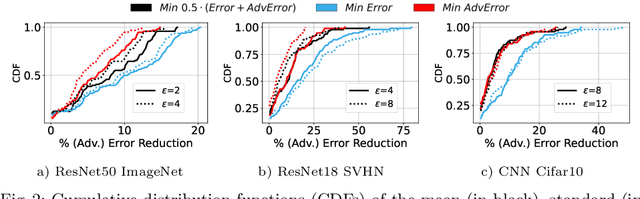
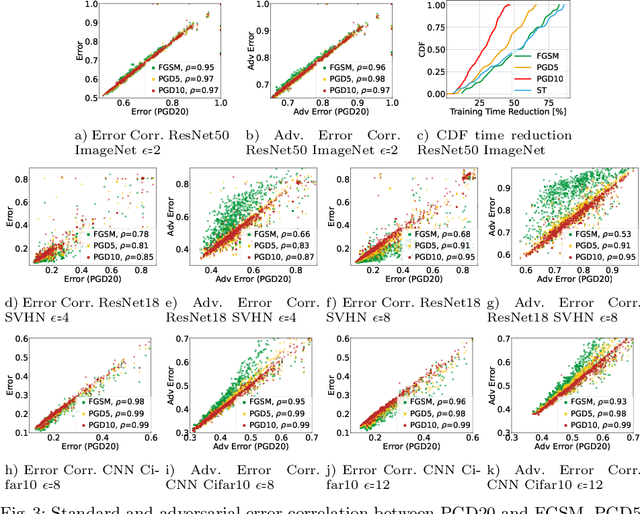
This work focuses on the problem of hyper-parameter tuning (HPT) for robust (i.e., adversarially trained) models, with the twofold goal of i) establishing which additional HPs are relevant to tune in adversarial settings, and ii) reducing the cost of HPT for robust models. We pursue the first goal via an extensive experimental study based on 3 recent models widely adopted in the prior literature on adversarial robustness. Our findings show that the complexity of the HPT problem, already notoriously expensive, is exacerbated in adversarial settings due to two main reasons: i) the need of tuning additional HPs which balance standard and adversarial training; ii) the need of tuning the HPs of the standard and adversarial training phases independently. Fortunately, we also identify new opportunities to reduce the cost of HPT for robust models. Specifically, we propose to leverage cheap adversarial training methods to obtain inexpensive, yet highly correlated, estimations of the quality achievable using state-of-the-art methods (PGD). We show that, by exploiting this novel idea in conjunction with a recent multi-fidelity optimizer (taKG), the efficiency of the HPT process can be significantly enhanced.
An NLP Solution to Foster the Use of Information in Electronic Health Records for Efficiency in Decision-Making in Hospital Care
Feb 24, 2022
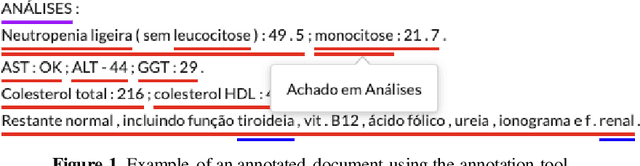
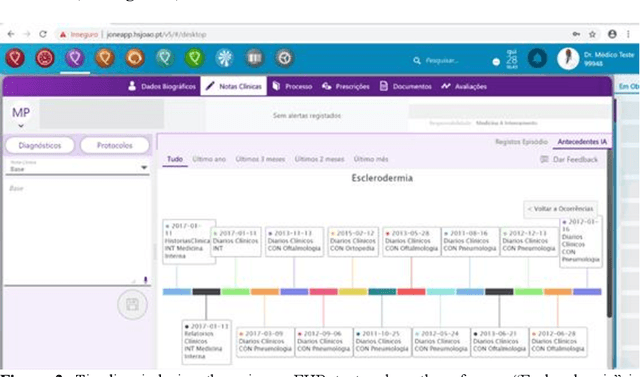
The project aimed to define the rules and develop a technological solution to automatically identify a set of attributes within free-text clinical records written in Portuguese. The first application developed and implemented on this basis was a structured summary of a patient's clinical history, including previous diagnoses and procedures, usual medication, and relevant characteristics or conditions for clinical decisions, such as allergies, being under anticoagulant therapy, etc. The project's goal was achieved by a multidisciplinary team that included clinicians, epidemiologists, computational linguists, machine learning researchers and software engineers, bringing together the expertise and perspectives of a public hospital, the university and the private sector. Relevant benefits to users and patients are related with facilitated access to the patient's history, which translates into exhaustiveness in apprehending the patient's clinical past and efficiency due to time saving.
HyperJump: Accelerating HyperBand via Risk Modelling
Aug 05, 2021
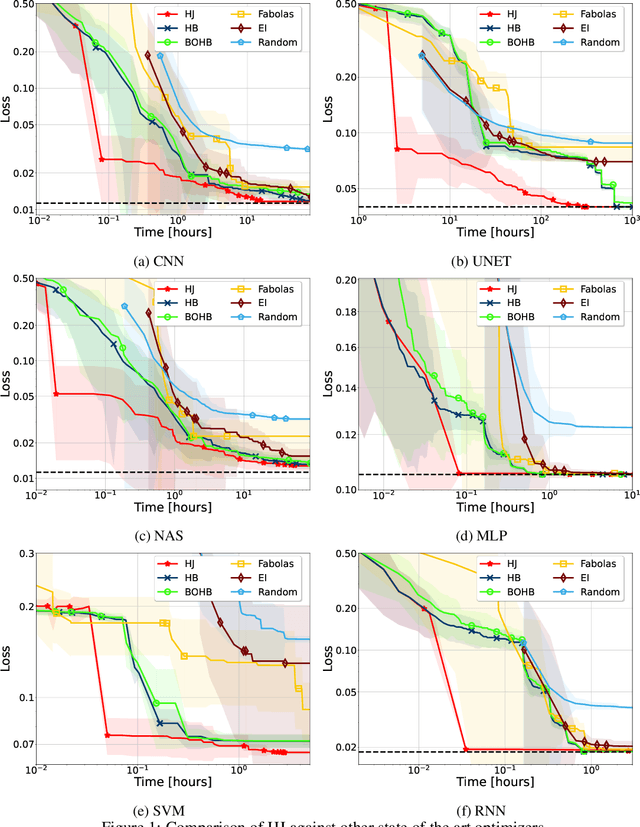
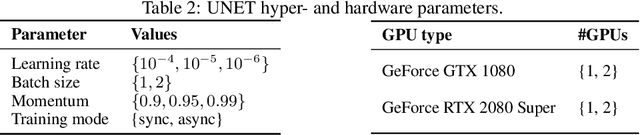

In the literature on hyper-parameter tuning, a number of recent solutions rely on low-fidelity observations (e.g., training with sub-sampled datasets or for short periods of time) to extrapolate good configurations to use when performing full training. Among these, HyperBand is arguably one of the most popular solutions, due to its efficiency and theoretically provable robustness. In this work, we introduce HyperJump, a new approach that builds on HyperBand's robust search strategy and complements it with novel model-based risk analysis techniques that accelerate the search by jumping the evaluation of low risk configurations, i.e., configurations that are likely to be discarded by HyperBand. We evaluate HyperJump on a suite of hyper-parameter optimization problems and show that it provides over one-order of magnitude speed-ups on a variety of deep-learning and kernel-based learning problems when compared to HyperBand as well as to a number of state of the art optimizers.
TrimTuner: Efficient Optimization of Machine Learning Jobs in the Cloud via Sub-Sampling
Nov 09, 2020
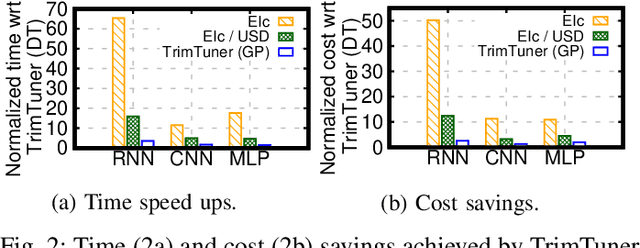
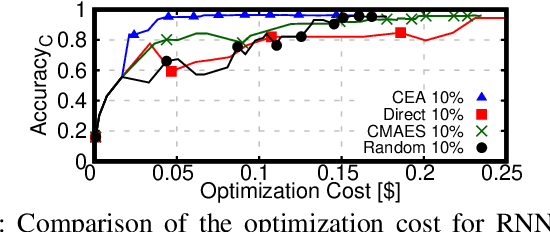
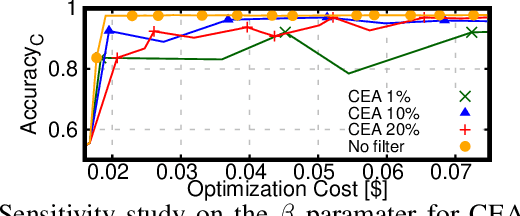
This work introduces TrimTuner, the first system for optimizing machine learning jobs in the cloud to exploit sub-sampling techniques to reduce the cost of the optimization process while keeping into account user-specified constraints. TrimTuner jointly optimizes the cloud and application-specific parameters and, unlike state of the art works for cloud optimization, eschews the need to train the model with the full training set every time a new configuration is sampled. Indeed, by leveraging sub-sampling techniques and data-sets that are up to 60x smaller than the original one, we show that TrimTuner can reduce the cost of the optimization process by up to 50x. Further, TrimTuner speeds-up the recommendation process by 65x with respect to state of the art techniques for hyper-parameter optimization that use sub-sampling techniques. The reasons for this improvement are twofold: i) a novel domain specific heuristic that reduces the number of configurations for which the acquisition function has to be evaluated; ii) the adoption of an ensemble of decision trees that enables boosting the speed of the recommendation process by one additional order of magnitude.
Facial Expressions Tracking and Recognition: Database Protocols for Systems Validation and Evaluation
Jun 02, 2015

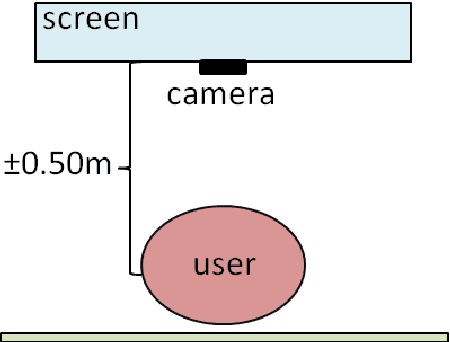

Each human face is unique. It has its own shape, topology, and distinguishing features. As such, developing and testing facial tracking systems are challenging tasks. The existing face recognition and tracking algorithms in Computer Vision mainly specify concrete situations according to particular goals and applications, requiring validation methodologies with data that fits their purposes. However, a database that covers all possible variations of external and factors does not exist, increasing researchers' work in acquiring their own data or compiling groups of databases. To address this shortcoming, we propose a methodology for facial data acquisition through definition of fundamental variables, such as subject characteristics, acquisition hardware, and performance parameters. Following this methodology, we also propose two protocols that allow the capturing of facial behaviors under uncontrolled and real-life situations. As validation, we executed both protocols which lead to creation of two sample databases: FdMiee (Facial database with Multi input, expressions, and environments) and FACIA (Facial Multimodal database driven by emotional induced acting). Using different types of hardware, FdMiee captures facial information under environmental and facial behaviors variations. FACIA is an extension of FdMiee introducing a pipeline to acquire additional facial behaviors and speech using an emotion-acting method. Therefore, this work eases the creation of adaptable database according to algorithm's requirements and applications, leading to simplified validation and testing processes.
Computer Poker Research at LIACC
Jan 25, 2013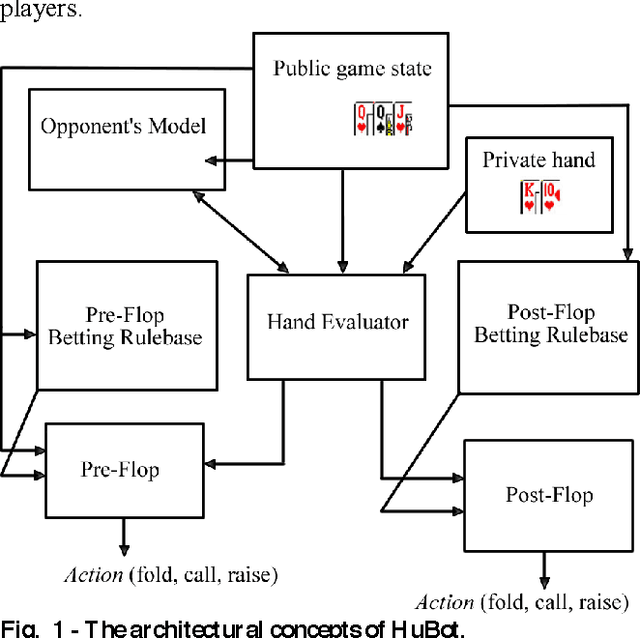

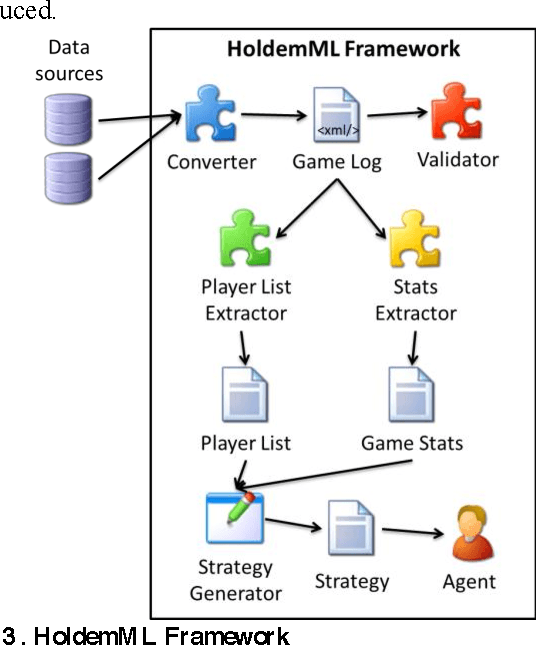
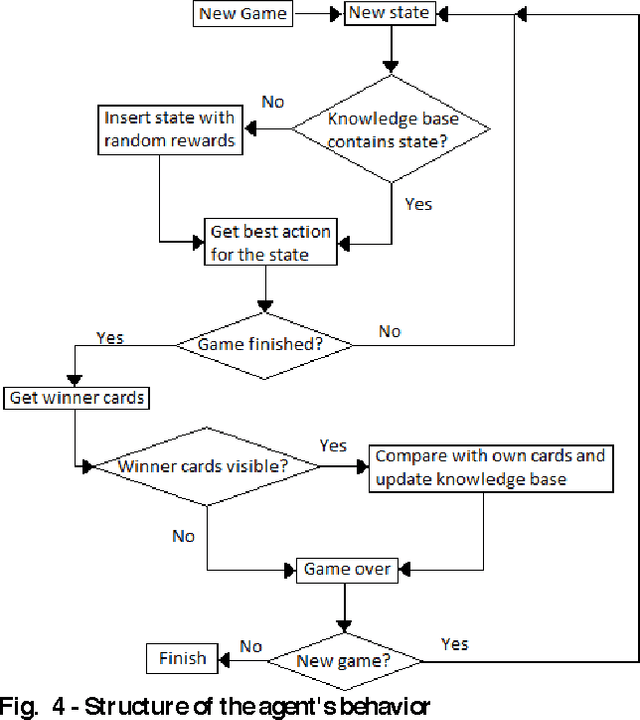
Computer Poker's unique characteristics present a well-suited challenge for research in artificial intelligence. For that reason, and due to the Poker's market increase in popularity in Portugal since 2008, several members of LIACC have researched in this field. Several works were published as papers and master theses and more recently a member of LIACC engaged on a research in this area as a Ph.D. thesis in order to develop a more extensive and in-depth work. This paper describes the existing research in LIACC about Computer Poker, with special emphasis on the completed master's theses and plans for future work. This paper means to present a summary of the lab's work to the research community in order to encourage the exchange of ideas with other labs / individuals. LIACC hopes this will improve research in this area so as to reach the goal of creating an agent that surpasses the best human players.