 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfOlaf: Semi-Automated Tool for Systematic Literature Reviews
Oct 30, 2025Systematic reviews and mapping studies are critical for synthesizing research, identifying gaps, and guiding future work, but they are often labor-intensive and time-consuming. Existing tools provide partial support for specific steps, leaving much of the process manual and error-prone. We present ProfOlaf, a semi-automated tool designed to streamline systematic reviews while maintaining methodological rigor. ProfOlaf supports iterative snowballing for article collection with human-in-the-loop filtering and uses large language models to assist in analyzing articles, extracting key topics, and answering queries about the content of papers. By combining automation with guided manual effort, ProfOlaf enhances the efficiency, quality, and reproducibility of systematic reviews across research fields. A video describing and demonstrating ProfOlaf is available at: https://youtu.be/4noUXfcmxsE
Empowering Sign Language Communication: Integrating Sentiment and Semantics for Facial Expression Synthesis
Aug 27, 2024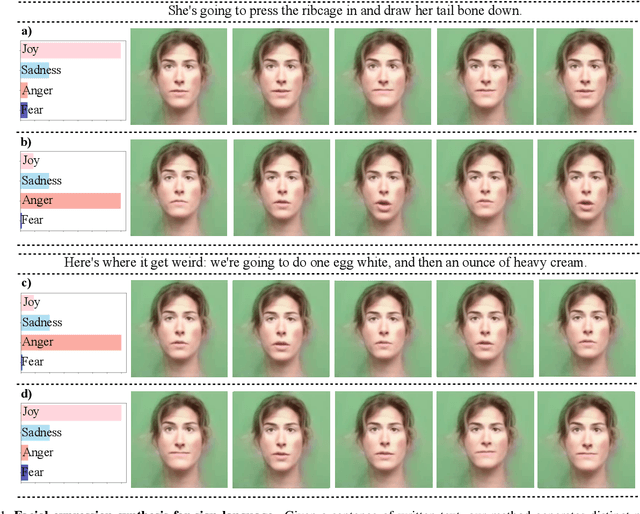

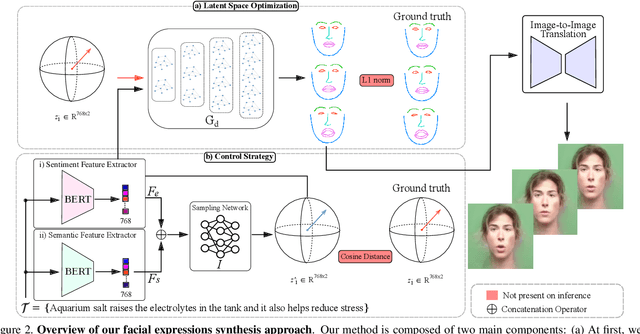
Translating written sentences from oral languages to a sequence of manual and non-manual gestures plays a crucial role in building a more inclusive society for deaf and hard-of-hearing people. Facial expressions (non-manual), in particular, are responsible for encoding the grammar of the sentence to be spoken, applying punctuation, pronouns, or emphasizing signs. These non-manual gestures are closely related to the semantics of the sentence being spoken and also to the utterance of the speaker's emotions. However, most Sign Language Production (SLP) approaches are centered on synthesizing manual gestures and do not focus on modeling the speakers expression. This paper introduces a new method focused in synthesizing facial expressions for sign language. Our goal is to improve sign language production by integrating sentiment information in facial expression generation. The approach leverages a sentence sentiment and semantic features to sample from a meaningful representation space, integrating the bias of the non-manual components into the sign language production process. To evaluate our method, we extend the Frechet Gesture Distance (FGD) and propose a new metric called Frechet Expression Distance (FED) and apply an extensive set of metrics to assess the quality of specific regions of the face. The experimental results showed that our method achieved state of the art, being superior to the competitors on How2Sign and PHOENIX14T datasets. Moreover, our architecture is based on a carefully designed graph pyramid that makes it simpler, easier to train, and capable of leveraging emotions to produce facial expressions.
Faster than LASER -- Towards Stream Reasoning with Deep Neural Networks
Jun 15, 2021
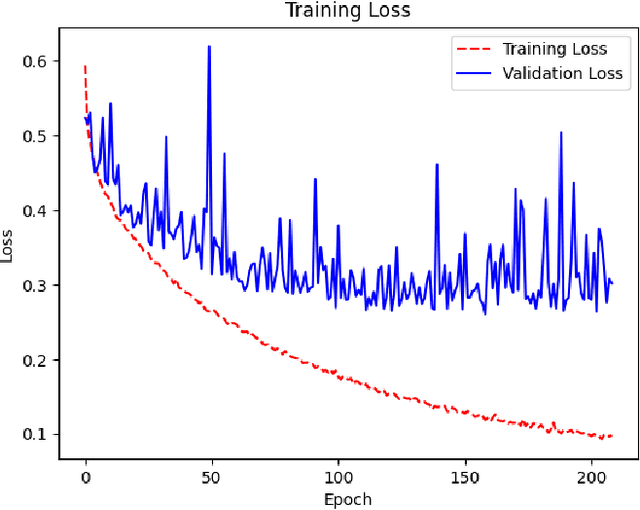
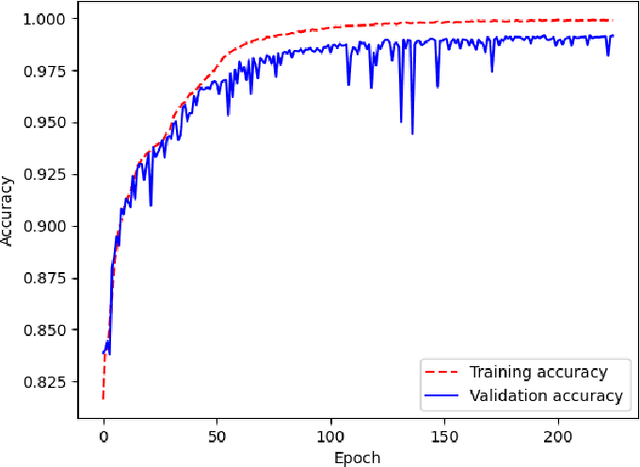
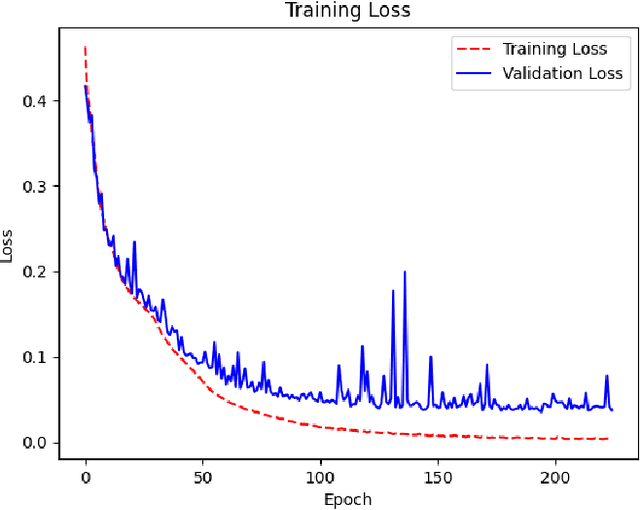
With the constant increase of available data in various domains, such as the Internet of Things, Social Networks or Smart Cities, it has become fundamental that agents are able to process and reason with such data in real time. Whereas reasoning over time-annotated data with background knowledge may be challenging, due to the volume and velocity in which such data is being produced, such complex reasoning is necessary in scenarios where agents need to discover potential problems and this cannot be done with simple stream processing techniques. Stream Reasoners aim at bridging this gap between reasoning and stream processing and LASER is such a stream reasoner designed to analyse and perform complex reasoning over streams of data. It is based on LARS, a rule-based logical language extending Answer Set Programming, and it has shown better runtime results than other state-of-the-art stream reasoning systems. Nevertheless, for high levels of data throughput even LASER may be unable to compute answers in a timely fashion. In this paper, we study whether Convolutional and Recurrent Neural Networks, which have shown to be particularly well-suited for time series forecasting and classification, can be trained to approximate reasoning with LASER, so that agents can benefit from their high processing speed.
On Development and Evaluation of Retargeting Human Motion and Appearance in Monocular Videos
Mar 29, 2021
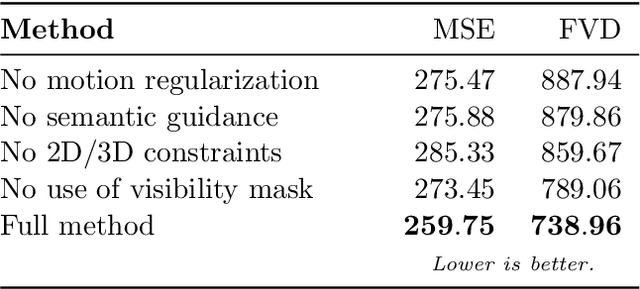
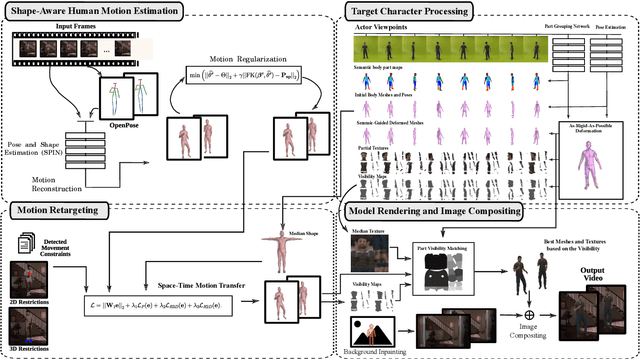
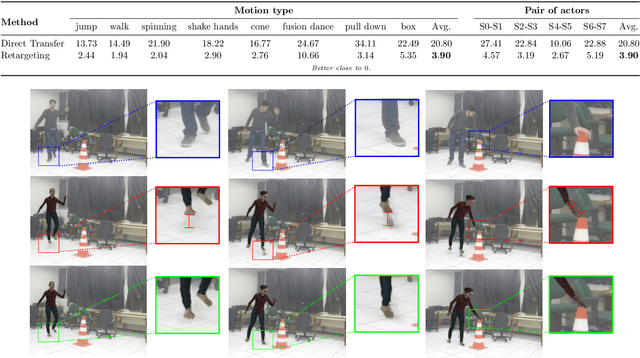
Transferring human motion and appearance between videos of human actors remains one of the key challenges in Computer Vision. Despite the advances from recent image-to-image translation approaches, there are several transferring contexts where most end-to-end learning-based retargeting methods still perform poorly. Transferring human appearance from one actor to another is only ensured when a strict setup has been complied, which is generally built considering their training regime's specificities. The contribution of this paper is two-fold: first, we propose a novel and high-performant approach based on a hybrid image-based rendering technique that exhibits competitive visual retargeting quality compared to state-of-the-art neural rendering approaches. The formulation leverages user body shape into the retargeting while considering physical constraints of the motion in 3D and the 2D image domain. We also present a new video retargeting benchmark dataset composed of different videos with annotated human motions to evaluate the task of synthesizing people's videos, which can be used as a common base to improve tracking the progress in the field. The dataset and its evaluation protocols are designed to evaluate retargeting methods in more general and challenging conditions. Our method is validated in several experiments, comprising publicly available videos of actors with different shapes, motion types and camera setups. The dataset and retargeting code are publicly available to the community at: https://www.verlab.dcc.ufmg.br/retargeting-motion.
Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
Jan 21, 2020


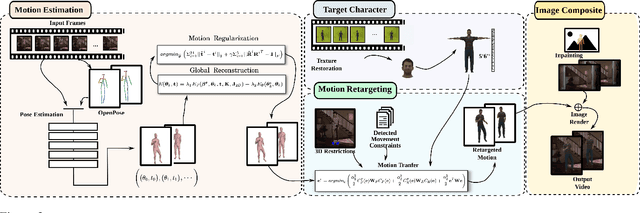
Creating plausible virtual actors from images of real actors remains one of the key challenges in computer vision and computer graphics. Marker-less human motion estimation and shape modeling from images in the wild bring this challenge to the fore. Although the recent advances on view synthesis and image-to-image translation, currently available formulations are limited to transfer solely style and do not take into account the character's motion and shape, which are by nature intermingled to produce plausible human forms. In this paper, we propose a unifying formulation for transferring appearance and retargeting human motion from monocular videos that regards all these aspects. Our method synthesizes new videos of people in a different context where they were initially recorded. Differently from recent appearance transferring methods, our approach takes into account body shape, appearance, and motion constraints. The evaluation is performed with several experiments using publicly available real videos containing hard conditions. Our method is able to transfer both human motion and appearance outperforming state-of-the-art methods, while preserving specific features of the motion that must be maintained (e.g., feet touching the floor, hands touching a particular object) and holding the best visual quality and appearance metrics such as Structural Similarity (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS).
Computer Poker Research at LIACC
Jan 25, 2013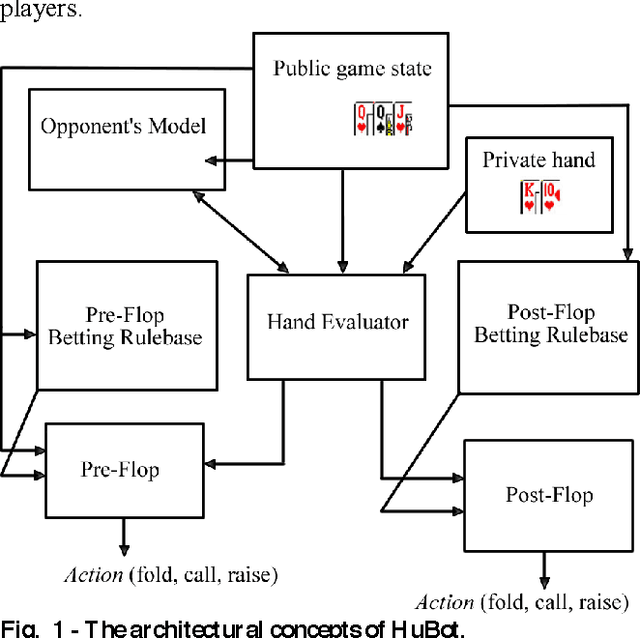

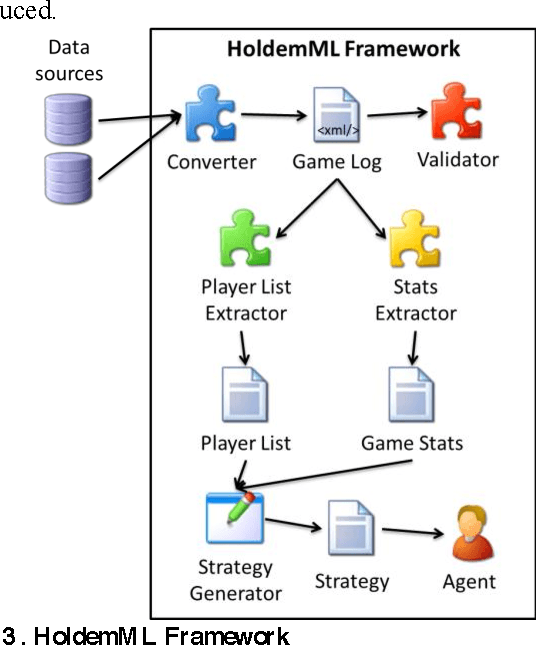
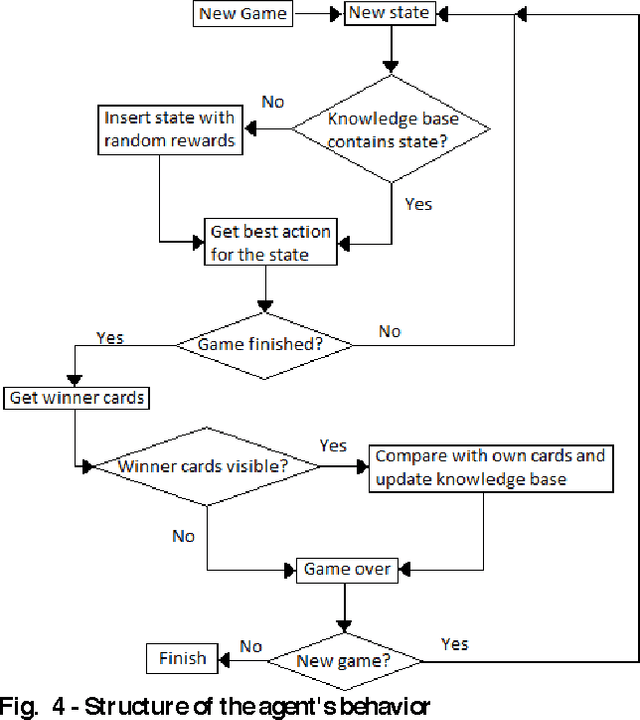
Computer Poker's unique characteristics present a well-suited challenge for research in artificial intelligence. For that reason, and due to the Poker's market increase in popularity in Portugal since 2008, several members of LIACC have researched in this field. Several works were published as papers and master theses and more recently a member of LIACC engaged on a research in this area as a Ph.D. thesis in order to develop a more extensive and in-depth work. This paper describes the existing research in LIACC about Computer Poker, with special emphasis on the completed master's theses and plans for future work. This paper means to present a summary of the lab's work to the research community in order to encourage the exchange of ideas with other labs / individuals. LIACC hopes this will improve research in this area so as to reach the goal of creating an agent that surpasses the best human players.