 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Viewpoint-Invariance and Temporal Consistency for Action Detection
May 21, 2026Viewpoint change invariance and action temporal consistency are critical aspects for the effective deployment of human action detection of untrimmed videos. Existing appearance-based video detection methods often struggle with limited viewpoint diversity during training, while motion-based detection approaches frequently fail to model fine-grained temporal relationships across consecutive motion windows. This paper introduces a novel two-stage action detection approach designed to improve both view-invariance and global temporal coherence properties. In the first stage, we extract motion features from augmented virtual viewpoints, solely used at training. Then, the second stage introduces a new view-invariant, multi-scale temporal encoder based on selective state-space sequence modelling to aggregate information across viewpoints and time scales. Experiments on PKU-MMD and BABEL benchmarks demonstrate that this approach significantly outperforms state-of-the-art methods in all considered splits. Code and trained models are available at: https://icb-vision-ai.github.io/HydraView-TAD
Cross-Domain Human Action Recognition from Multiview Motion and Textual Descriptions
May 21, 2026Robustness to domain changes is a key capability for effective deployment of human action recognition systems in real-world scenarios, where action categories at inference can present important domain shifts or even unseen actions from training. In this context, improving the recognition capabilities of Zero-Shot Action Recognition models (ZSAR), without requiring strong annotation efforts, remains a central challenge. Most ZSAR approaches assume that actions are observed under geometric conditions similar to those seen during training. In practice, variations in human body orientation and camera viewpoint add a significant domain gap in ZSAR, substantially limiting generalization to novel action-motion combinations. In this context, this paper presents a novel orientation-aware action recognition approach with improved cross-domain capabilities. Our approach combines motion cues of multiple camera viewpoints and text descriptions of human actions in the training phase. We present a new orientation-aware motion encoding network to learn different motion features, and adapt a specific orientation-aware text prompt to match the corresponding features at inference. Extensive experiments demonstrate that the proposed method consistently improves ZSAR performance across different recognition benchmarks, outperforming recent state-of-the-art zero-shot approaches on NTU-RGB+D, BABEL, NW-UCLA, and on two surveillance datasets. In addition, the learned representations exhibit strong transfer learning capabilities, yielding competitive performance on both cross-domain and same-domain recognition of seen actions. Code and trained models are available at: https://icb-vision-ai.github.io/OrientationAware-HAR
Dense Scene Reconstruction from Light-Field Images Affected by Rolling Shutter
Dec 04, 2024



This paper presents a dense depth estimation approach from light-field (LF) images that is able to compensate for strong rolling shutter (RS) effects. Our method estimates RS compensated views and dense RS compensated disparity maps. We present a two-stage method based on a 2D Gaussians Splatting that allows for a ``render and compare" strategy with a point cloud formulation. In the first stage, a subset of sub-aperture images is used to estimate an RS agnostic 3D shape that is related to the scene target shape ``up to a motion". In the second stage, the deformation of the 3D shape is computed by estimating an admissible camera motion. We demonstrate the effectiveness and advantages of this approach through several experiments conducted for different scenes and types of motions. Due to lack of suitable datasets for evaluation, we also present a new carefully designed synthetic dataset of RS LF images. The source code, trained models and dataset will be made publicly available at: https://github.com/ICB-Vision-AI/DenseRSLF
Leveraging Semantic Cues from Foundation Vision Models for Enhanced Local Feature Correspondence
Oct 12, 2024



Visual correspondence is a crucial step in key computer vision tasks, including camera localization, image registration, and structure from motion. The most effective techniques for matching keypoints currently involve using learned sparse or dense matchers, which need pairs of images. These neural networks have a good general understanding of features from both images, but they often struggle to match points from different semantic areas. This paper presents a new method that uses semantic cues from foundation vision model features (like DINOv2) to enhance local feature matching by incorporating semantic reasoning into existing descriptors. Therefore, the learned descriptors do not require image pairs at inference time, allowing feature caching and fast matching using similarity search, unlike learned matchers. We present adapted versions of six existing descriptors, with an average increase in performance of 29% in camera localization, with comparable accuracy to existing matchers as LightGlue and LoFTR in two existing benchmarks. Both code and trained models are available at https://www.verlab.dcc.ufmg.br/descriptors/reasoning_accv24
XFeat: Accelerated Features for Lightweight Image Matching
Apr 30, 2024



We introduce a lightweight and accurate architecture for resource-efficient visual correspondence. Our method, dubbed XFeat (Accelerated Features), revisits fundamental design choices in convolutional neural networks for detecting, extracting, and matching local features. Our new model satisfies a critical need for fast and robust algorithms suitable to resource-limited devices. In particular, accurate image matching requires sufficiently large image resolutions - for this reason, we keep the resolution as large as possible while limiting the number of channels in the network. Besides, our model is designed to offer the choice of matching at the sparse or semi-dense levels, each of which may be more suitable for different downstream applications, such as visual navigation and augmented reality. Our model is the first to offer semi-dense matching efficiently, leveraging a novel match refinement module that relies on coarse local descriptors. XFeat is versatile and hardware-independent, surpassing current deep learning-based local features in speed (up to 5x faster) with comparable or better accuracy, proven in pose estimation and visual localization. We showcase it running in real-time on an inexpensive laptop CPU without specialized hardware optimizations. Code and weights are available at www.verlab.dcc.ufmg.br/descriptors/xfeat_cvpr24.
Pola4All: survey of polarimetric applications and an open-source toolkit to analyze polarization
Dec 22, 2023Polarization information of the light can provide rich cues for computer vision and scene understanding tasks, such as the type of material, pose, and shape of the objects. With the advent of new and cheap polarimetric sensors, this imaging modality is becoming accessible to a wider public for solving problems such as pose estimation, 3D reconstruction, underwater navigation, and depth estimation. However, we observe several limitations regarding the usage of this sensorial modality, as well as a lack of standards and publicly available tools to analyze polarization images. Furthermore, although polarization camera manufacturers usually provide acquisition tools to interface with their cameras, they rarely include processing algorithms that make use of the polarization information. In this paper, we review recent advances in applications that involve polarization imaging, including a comprehensive survey of recent advances on polarization for vision and robotics perception tasks. We also introduce a complete software toolkit that provides common standards to communicate with and process information from most of the existing micro-grid polarization cameras on the market. The toolkit also implements several image processing algorithms for this modality, and it is publicly available on GitHub: https://github.com/vibot-lab/Pola4all_JEI_2023.
Joint 3D Shape and Motion Estimation from Rolling Shutter Light-Field Images
Nov 02, 2023
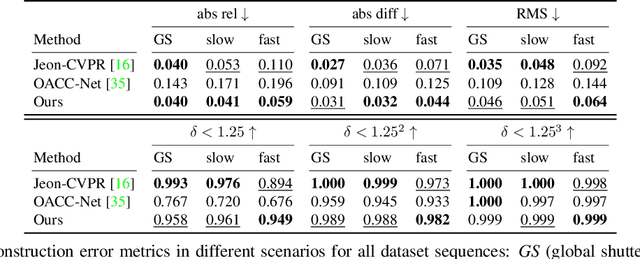
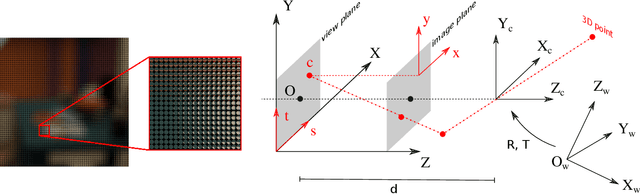
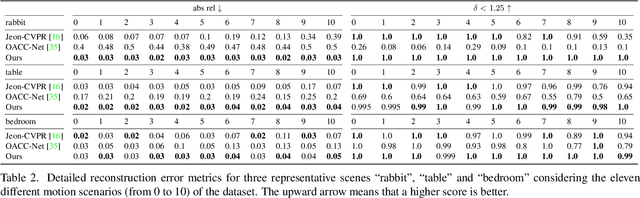
In this paper, we propose an approach to address the problem of 3D reconstruction of scenes from a single image captured by a light-field camera equipped with a rolling shutter sensor. Our method leverages the 3D information cues present in the light-field and the motion information provided by the rolling shutter effect. We present a generic model for the imaging process of this sensor and a two-stage algorithm that minimizes the re-projection error while considering the position and motion of the camera in a motion-shape bundle adjustment estimation strategy. Thereby, we provide an instantaneous 3D shape-and-pose-and-velocity sensing paradigm. To the best of our knowledge, this is the first study to leverage this type of sensor for this purpose. We also present a new benchmark dataset composed of different light-fields showing rolling shutter effects, which can be used as a common base to improve the evaluation and tracking the progress in the field. We demonstrate the effectiveness and advantages of our approach through several experiments conducted for different scenes and types of motions. The source code and dataset are publicly available at: https://github.com/ICB-Vision-AI/RSLF
Improving the matching of deformable objects by learning to detect keypoints
Sep 12, 2023


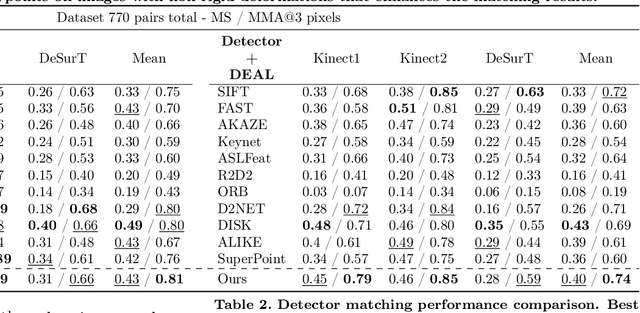
We propose a novel learned keypoint detection method to increase the number of correct matches for the task of non-rigid image correspondence. By leveraging true correspondences acquired by matching annotated image pairs with a specified descriptor extractor, we train an end-to-end convolutional neural network (CNN) to find keypoint locations that are more appropriate to the considered descriptor. For that, we apply geometric and photometric warpings to images to generate a supervisory signal, allowing the optimization of the detector. Experiments demonstrate that our method enhances the Mean Matching Accuracy of numerous descriptors when used in conjunction with our detection method, while outperforming the state-of-the-art keypoint detectors on real images of non-rigid objects by 20 p.p. We also apply our method on the complex real-world task of object retrieval where our detector performs on par with the finest keypoint detectors currently available for this task. The source code and trained models are publicly available at https://github.com/verlab/LearningToDetect_PRL_2023
* This is the accepted version of the paper to appear at Pattern Recognition Letters (PRL). The final journal version will be available at https://doi.org/10.1016/j.patrec.2023.08.012
Enhancing Deformable Local Features by Jointly Learning to Detect and Describe Keypoints
Apr 02, 2023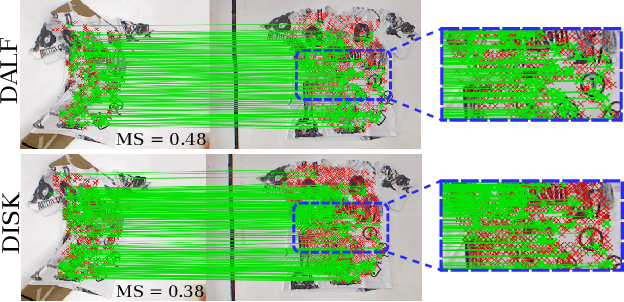

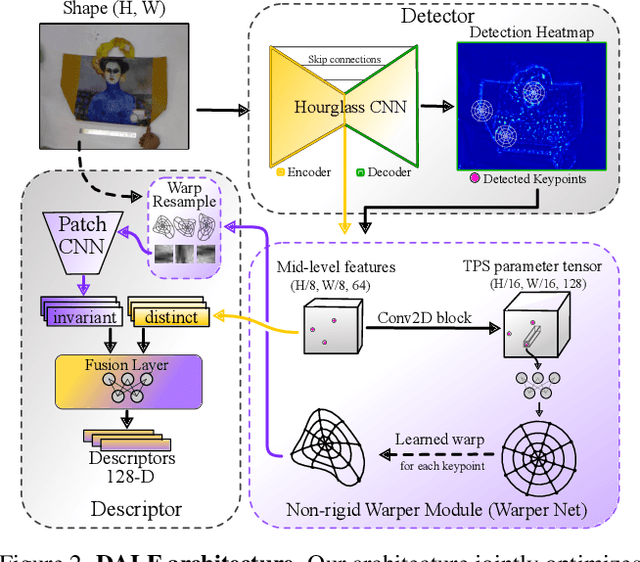

Local feature extraction is a standard approach in computer vision for tackling important tasks such as image matching and retrieval. The core assumption of most methods is that images undergo affine transformations, disregarding more complicated effects such as non-rigid deformations. Furthermore, incipient works tailored for non-rigid correspondence still rely on keypoint detectors designed for rigid transformations, hindering performance due to the limitations of the detector. We propose DALF (Deformation-Aware Local Features), a novel deformation-aware network for jointly detecting and describing keypoints, to handle the challenging problem of matching deformable surfaces. All network components work cooperatively through a feature fusion approach that enforces the descriptors' distinctiveness and invariance. Experiments using real deforming objects showcase the superiority of our method, where it delivers 8% improvement in matching scores compared to the previous best results. Our approach also enhances the performance of two real-world applications: deformable object retrieval and non-rigid 3D surface registration. Code for training, inference, and applications are publicly available at https://verlab.dcc.ufmg.br/descriptors/dalf_cvpr23.
Learning to Detect Good Keypoints to Match Non-Rigid Objects in RGB Images
Dec 13, 2022

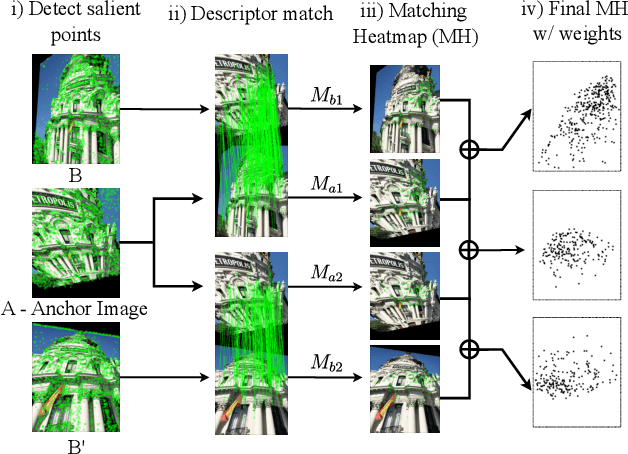

We present a novel learned keypoint detection method designed to maximize the number of correct matches for the task of non-rigid image correspondence. Our training framework uses true correspondences, obtained by matching annotated image pairs with a predefined descriptor extractor, as a ground-truth to train a convolutional neural network (CNN). We optimize the model architecture by applying known geometric transformations to images as the supervisory signal. Experiments show that our method outperforms the state-of-the-art keypoint detector on real images of non-rigid objects by 20 p.p. on Mean Matching Accuracy and also improves the matching performance of several descriptors when coupled with our detection method. We also employ the proposed method in one challenging realworld application: object retrieval, where our detector exhibits performance on par with the best available keypoint detectors. The source code and trained model are publicly available at https://github.com/verlab/LearningToDetect SIBGRAPI 2022