 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Armed Bandit Approach for Optimizing Training on Synthetic Data
Dec 06, 2024



Supervised machine learning methods require large-scale training datasets to perform well in practice. Synthetic data has been showing great progress recently and has been used as a complement to real data. However, there is yet a great urge to assess the usability of synthetically generated data. To this end, we propose a novel UCB-based training procedure combined with a dynamic usability metric. Our proposed metric integrates low-level and high-level information from synthetic images and their corresponding real and synthetic datasets, surpassing existing traditional metrics. By utilizing a UCB-based dynamic approach ensures continual enhancement of model learning. Unlike other approaches, our method effectively adapts to changes in the machine learning model's state and considers the evolving utility of training samples during the training process. We show that our metric is an effective way to rank synthetic images based on their usability. Furthermore, we propose a new attribute-aware bandit pipeline for generating synthetic data by integrating a Large Language Model with Stable Diffusion. Quantitative results show that our approach can boost the performance of a wide range of supervised classifiers. Notably, we observed an improvement of up to 10% in classification accuracy compared to traditional approaches, demonstrating the effectiveness of our approach. Our source code, datasets, and additional materials are publically available at https://github.com/A-Kerim/Synthetic-Data-Usability-2024.
Leveraging Semantic Cues from Foundation Vision Models for Enhanced Local Feature Correspondence
Oct 12, 2024



Visual correspondence is a crucial step in key computer vision tasks, including camera localization, image registration, and structure from motion. The most effective techniques for matching keypoints currently involve using learned sparse or dense matchers, which need pairs of images. These neural networks have a good general understanding of features from both images, but they often struggle to match points from different semantic areas. This paper presents a new method that uses semantic cues from foundation vision model features (like DINOv2) to enhance local feature matching by incorporating semantic reasoning into existing descriptors. Therefore, the learned descriptors do not require image pairs at inference time, allowing feature caching and fast matching using similarity search, unlike learned matchers. We present adapted versions of six existing descriptors, with an average increase in performance of 29% in camera localization, with comparable accuracy to existing matchers as LightGlue and LoFTR in two existing benchmarks. Both code and trained models are available at https://www.verlab.dcc.ufmg.br/descriptors/reasoning_accv24
XFeat: Accelerated Features for Lightweight Image Matching
Apr 30, 2024



We introduce a lightweight and accurate architecture for resource-efficient visual correspondence. Our method, dubbed XFeat (Accelerated Features), revisits fundamental design choices in convolutional neural networks for detecting, extracting, and matching local features. Our new model satisfies a critical need for fast and robust algorithms suitable to resource-limited devices. In particular, accurate image matching requires sufficiently large image resolutions - for this reason, we keep the resolution as large as possible while limiting the number of channels in the network. Besides, our model is designed to offer the choice of matching at the sparse or semi-dense levels, each of which may be more suitable for different downstream applications, such as visual navigation and augmented reality. Our model is the first to offer semi-dense matching efficiently, leveraging a novel match refinement module that relies on coarse local descriptors. XFeat is versatile and hardware-independent, surpassing current deep learning-based local features in speed (up to 5x faster) with comparable or better accuracy, proven in pose estimation and visual localization. We showcase it running in real-time on an inexpensive laptop CPU without specialized hardware optimizations. Code and weights are available at www.verlab.dcc.ufmg.br/descriptors/xfeat_cvpr24.
Improving the matching of deformable objects by learning to detect keypoints
Sep 12, 2023


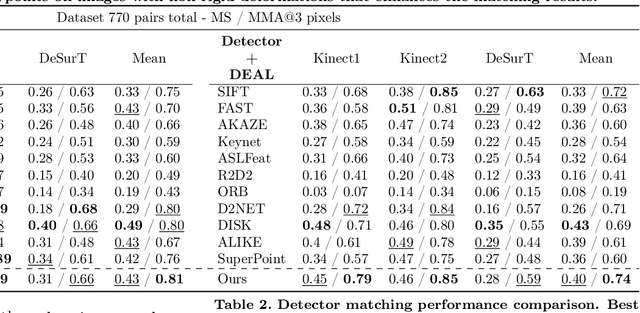
We propose a novel learned keypoint detection method to increase the number of correct matches for the task of non-rigid image correspondence. By leveraging true correspondences acquired by matching annotated image pairs with a specified descriptor extractor, we train an end-to-end convolutional neural network (CNN) to find keypoint locations that are more appropriate to the considered descriptor. For that, we apply geometric and photometric warpings to images to generate a supervisory signal, allowing the optimization of the detector. Experiments demonstrate that our method enhances the Mean Matching Accuracy of numerous descriptors when used in conjunction with our detection method, while outperforming the state-of-the-art keypoint detectors on real images of non-rigid objects by 20 p.p. We also apply our method on the complex real-world task of object retrieval where our detector performs on par with the finest keypoint detectors currently available for this task. The source code and trained models are publicly available at https://github.com/verlab/LearningToDetect_PRL_2023
* This is the accepted version of the paper to appear at Pattern Recognition Letters (PRL). The final journal version will be available at https://doi.org/10.1016/j.patrec.2023.08.012
Enhancing Deformable Local Features by Jointly Learning to Detect and Describe Keypoints
Apr 02, 2023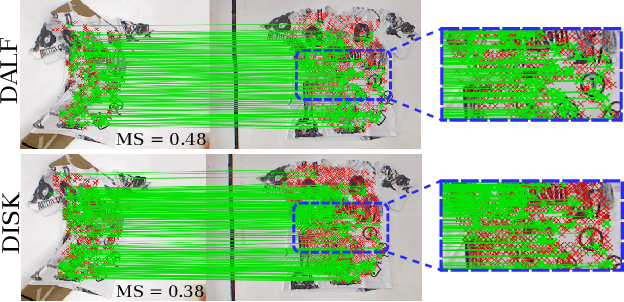

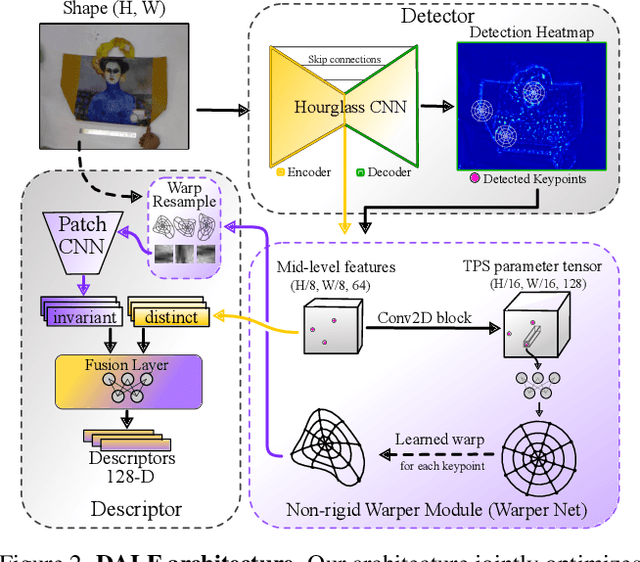

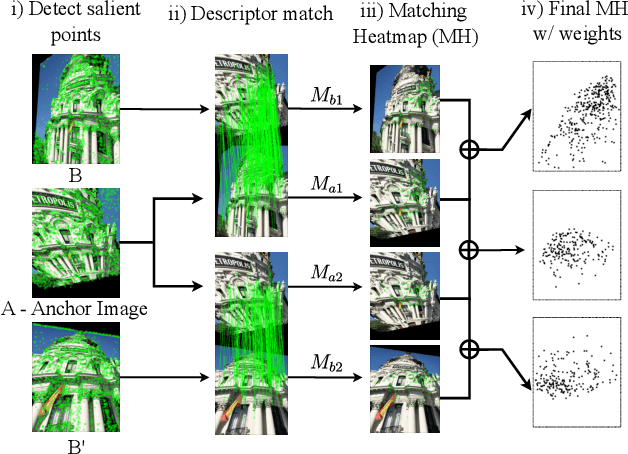
Local feature extraction is a standard approach in computer vision for tackling important tasks such as image matching and retrieval. The core assumption of most methods is that images undergo affine transformations, disregarding more complicated effects such as non-rigid deformations. Furthermore, incipient works tailored for non-rigid correspondence still rely on keypoint detectors designed for rigid transformations, hindering performance due to the limitations of the detector. We propose DALF (Deformation-Aware Local Features), a novel deformation-aware network for jointly detecting and describing keypoints, to handle the challenging problem of matching deformable surfaces. All network components work cooperatively through a feature fusion approach that enforces the descriptors' distinctiveness and invariance. Experiments using real deforming objects showcase the superiority of our method, where it delivers 8% improvement in matching scores compared to the previous best results. Our approach also enhances the performance of two real-world applications: deformable object retrieval and non-rigid 3D surface registration. Code for training, inference, and applications are publicly available at https://verlab.dcc.ufmg.br/descriptors/dalf_cvpr23.
Learning to Detect Good Keypoints to Match Non-Rigid Objects in RGB Images
Dec 13, 2022


We present a novel learned keypoint detection method designed to maximize the number of correct matches for the task of non-rigid image correspondence. Our training framework uses true correspondences, obtained by matching annotated image pairs with a predefined descriptor extractor, as a ground-truth to train a convolutional neural network (CNN). We optimize the model architecture by applying known geometric transformations to images as the supervisory signal. Experiments show that our method outperforms the state-of-the-art keypoint detector on real images of non-rigid objects by 20 p.p. on Mean Matching Accuracy and also improves the matching performance of several descriptors when coupled with our detection method. We also employ the proposed method in one challenging realworld application: object retrieval, where our detector exhibits performance on par with the best available keypoint detectors. The source code and trained model are publicly available at https://github.com/verlab/LearningToDetect SIBGRAPI 2022
Semantic Segmentation under Adverse Conditions: A Weather and Nighttime-aware Synthetic Data-based Approach
Oct 11, 2022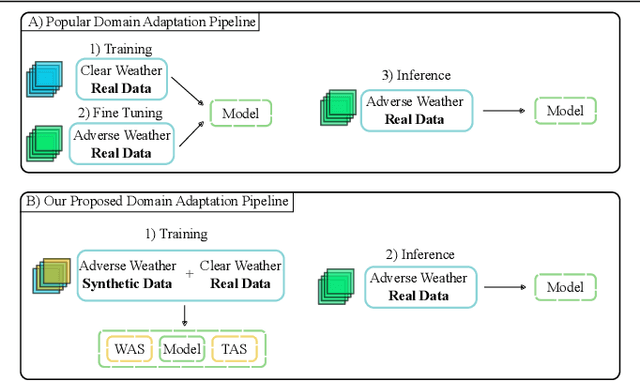


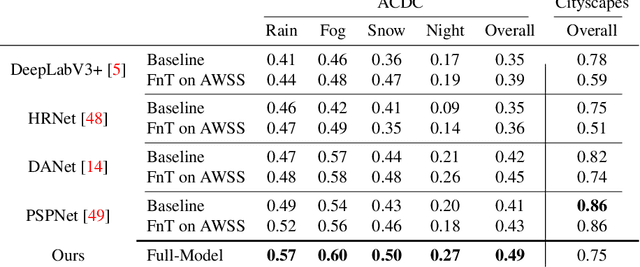
Recent semantic segmentation models perform well under standard weather conditions and sufficient illumination but struggle with adverse weather conditions and nighttime. Collecting and annotating training data under these conditions is expensive, time-consuming, error-prone, and not always practical. Usually, synthetic data is used as a feasible data source to increase the amount of training data. However, just directly using synthetic data may actually harm the model's performance under normal weather conditions while getting only small gains in adverse situations. Therefore, we present a novel architecture specifically designed for using synthetic training data for domain adaptation. We propose a simple yet powerful addition to DeepLabV3+ by using weather and time-of-the-day supervisors trained with multi-task learning, making it both weather and nighttime aware, which improves its mIoU accuracy by $14$ percentage points on the ACDC dataset while maintaining a score of $75\%$ mIoU on the Cityscapes dataset. Our code is available at https://github.com/lsmcolab/Semantic-Segmentation-under-Adverse-Conditions.
Leveraging Synthetic Data to Learn Video Stabilization Under Adverse Conditions
Aug 26, 2022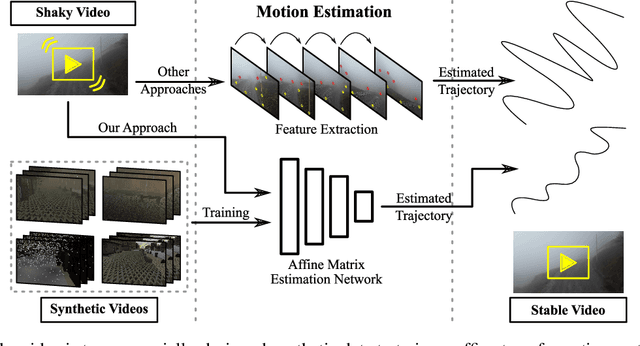
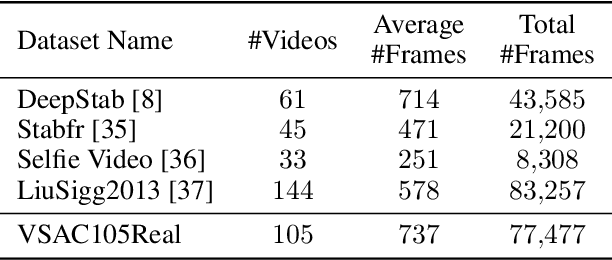
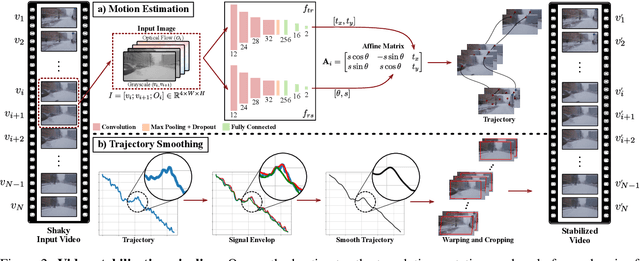
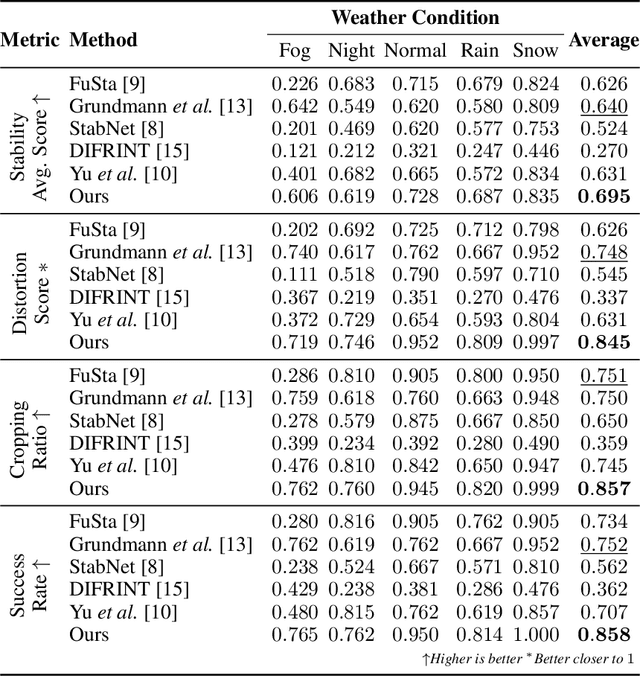
Video stabilization plays a central role to improve videos quality. However, despite the substantial progress made by these methods, they were, mainly, tested under standard weather and lighting conditions, and may perform poorly under adverse conditions. In this paper, we propose a synthetic-aware adverse weather robust algorithm for video stabilization that does not require real data and can be trained only on synthetic data. We also present Silver, a novel rendering engine to generate the required training data with an automatic ground-truth extraction procedure. Our approach uses our specially generated synthetic data for training an affine transformation matrix estimator avoiding the feature extraction issues faced by current methods. Additionally, since no video stabilization datasets under adverse conditions are available, we propose the novel VSAC105Real dataset for evaluation. We compare our method to five state-of-the-art video stabilization algorithms using two benchmarks. Our results show that current approaches perform poorly in at least one weather condition, and that, even training in a small dataset with synthetic data only, we achieve the best performance in terms of stability average score, distortion score, success rate, and average cropping ratio when considering all weather conditions. Hence, our video stabilization model generalizes well on real-world videos and does not require large-scale synthetic training data to converge.
Text-Driven Video Acceleration: A Weakly-Supervised Reinforcement Learning Method
Mar 29, 2022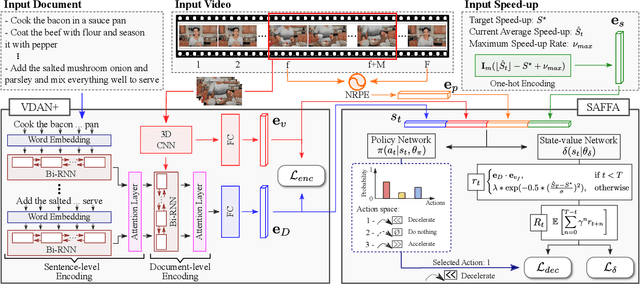

The growth of videos in our digital age and the users' limited time raise the demand for processing untrimmed videos to produce shorter versions conveying the same information. Despite the remarkable progress that summarization methods have made, most of them can only select a few frames or skims, creating visual gaps and breaking the video context. This paper presents a novel weakly-supervised methodology based on a reinforcement learning formulation to accelerate instructional videos using text. A novel joint reward function guides our agent to select which frames to remove and reduce the input video to a target length without creating gaps in the final video. We also propose the Extended Visually-guided Document Attention Network (VDAN+), which can generate a highly discriminative embedding space to represent both textual and visual data. Our experiments show that our method achieves the best performance in Precision, Recall, and F1 Score against the baselines while effectively controlling the video's output length. Visit https://www.verlab.dcc.ufmg.br/semantic-hyperlapse/tpami2022/ for code and extra results.
Learning Geodesic-Aware Local Features from RGB-D Images
Mar 22, 2022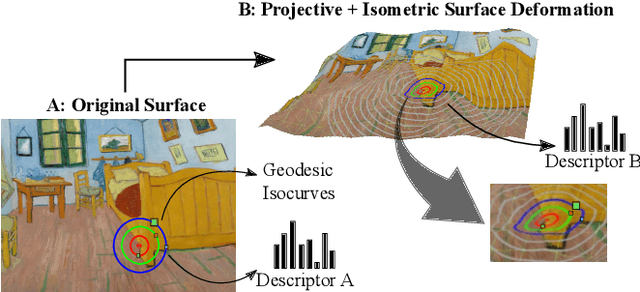
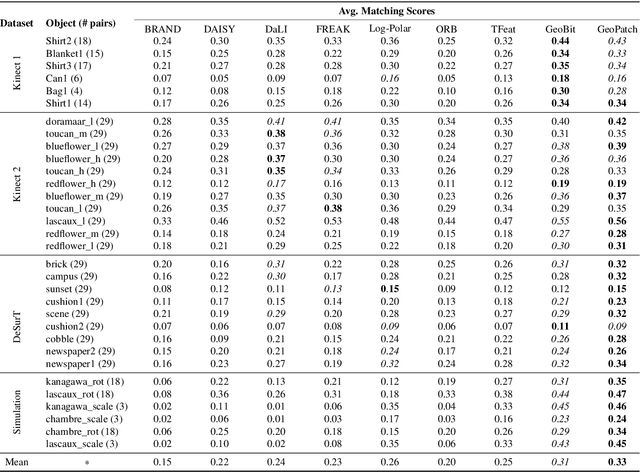
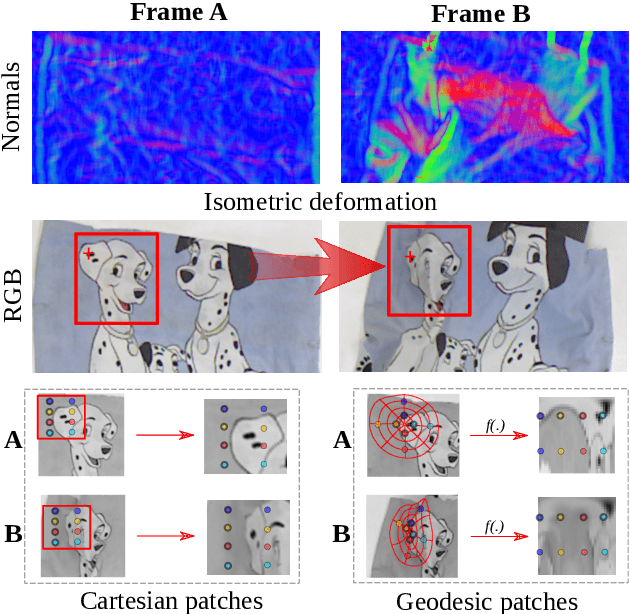
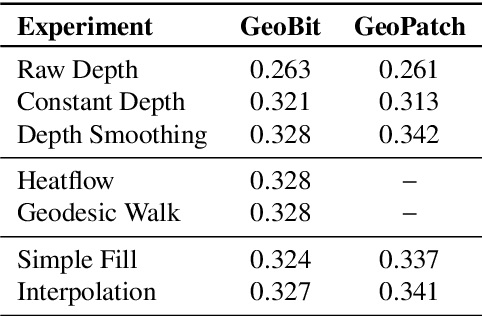
Most of the existing handcrafted and learning-based local descriptors are still at best approximately invariant to affine image transformations, often disregarding deformable surfaces. In this paper, we take one step further by proposing a new approach to compute descriptors from RGB-D images (where RGB refers to the pixel color brightness and D stands for depth information) that are invariant to isometric non-rigid deformations, as well as to scale changes and rotation. Our proposed description strategies are grounded on the key idea of learning feature representations on undistorted local image patches using surface geodesics. We design two complementary local descriptors strategies to compute geodesic-aware features efficiently: one efficient binary descriptor based on handcrafted binary tests (named GeoBit), and one learning-based descriptor (GeoPatch) with convolutional neural networks (CNNs) to compute features. In different experiments using real and publicly available RGB-D data benchmarks, they consistently outperforms state-of-the-art handcrafted and learning-based image and RGB-D descriptors in matching scores, as well as in object retrieval and non-rigid surface tracking experiments, with comparable processing times. We also provide to the community a new dataset with accurate matching annotations of RGB-D images of different objects (shirts, cloths, paintings, bags), subjected to strong non-rigid deformations, for evaluation benchmark of deformable surface correspondence algorithms.