 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Armed Bandit Approach for Optimizing Training on Synthetic Data
Dec 06, 2024



Supervised machine learning methods require large-scale training datasets to perform well in practice. Synthetic data has been showing great progress recently and has been used as a complement to real data. However, there is yet a great urge to assess the usability of synthetically generated data. To this end, we propose a novel UCB-based training procedure combined with a dynamic usability metric. Our proposed metric integrates low-level and high-level information from synthetic images and their corresponding real and synthetic datasets, surpassing existing traditional metrics. By utilizing a UCB-based dynamic approach ensures continual enhancement of model learning. Unlike other approaches, our method effectively adapts to changes in the machine learning model's state and considers the evolving utility of training samples during the training process. We show that our metric is an effective way to rank synthetic images based on their usability. Furthermore, we propose a new attribute-aware bandit pipeline for generating synthetic data by integrating a Large Language Model with Stable Diffusion. Quantitative results show that our approach can boost the performance of a wide range of supervised classifiers. Notably, we observed an improvement of up to 10% in classification accuracy compared to traditional approaches, demonstrating the effectiveness of our approach. Our source code, datasets, and additional materials are publically available at https://github.com/A-Kerim/Synthetic-Data-Usability-2024.
Reward Certification for Policy Smoothed Reinforcement Learning
Dec 12, 2023


Reinforcement Learning (RL) has achieved remarkable success in safety-critical areas, but it can be weakened by adversarial attacks. Recent studies have introduced "smoothed policies" in order to enhance its robustness. Yet, it is still challenging to establish a provable guarantee to certify the bound of its total reward. Prior methods relied primarily on computing bounds using Lipschitz continuity or calculating the probability of cumulative reward above specific thresholds. However, these techniques are only suited for continuous perturbations on the RL agent's observations and are restricted to perturbations bounded by the $l_2$-norm. To address these limitations, this paper proposes a general black-box certification method capable of directly certifying the cumulative reward of the smoothed policy under various $l_p$-norm bounded perturbations. Furthermore, we extend our methodology to certify perturbations on action spaces. Our approach leverages f-divergence to measure the distinction between the original distribution and the perturbed distribution, subsequently determining the certification bound by solving a convex optimisation problem. We provide a comprehensive theoretical analysis and run sufficient experiments in multiple environments. Our results show that our method not only improves the certified lower bound of mean cumulative reward but also demonstrates better efficiency than state-of-the-art techniques.
Certified Policy Smoothing for Cooperative Multi-Agent Reinforcement Learning
Dec 22, 2022Cooperative multi-agent reinforcement learning (c-MARL) is widely applied in safety-critical scenarios, thus the analysis of robustness for c-MARL models is profoundly important. However, robustness certification for c-MARLs has not yet been explored in the community. In this paper, we propose a novel certification method, which is the first work to leverage a scalable approach for c-MARLs to determine actions with guaranteed certified bounds. c-MARL certification poses two key challenges compared with single-agent systems: (i) the accumulated uncertainty as the number of agents increases; (ii) the potential lack of impact when changing the action of a single agent into a global team reward. These challenges prevent us from directly using existing algorithms. Hence, we employ the false discovery rate (FDR) controlling procedure considering the importance of each agent to certify per-state robustness and propose a tree-search-based algorithm to find a lower bound of the global reward under the minimal certified perturbation. As our method is general, it can also be applied in single-agent environments. We empirically show that our certification bounds are much tighter than state-of-the-art RL certification solutions. We also run experiments on two popular c-MARL algorithms: QMIX and VDN, in two different environments, with two and four agents. The experimental results show that our method produces meaningful guaranteed robustness for all models and environments. Our tool CertifyCMARL is available at https://github.com/TrustAI/CertifyCMA
Semantic Segmentation under Adverse Conditions: A Weather and Nighttime-aware Synthetic Data-based Approach
Oct 11, 2022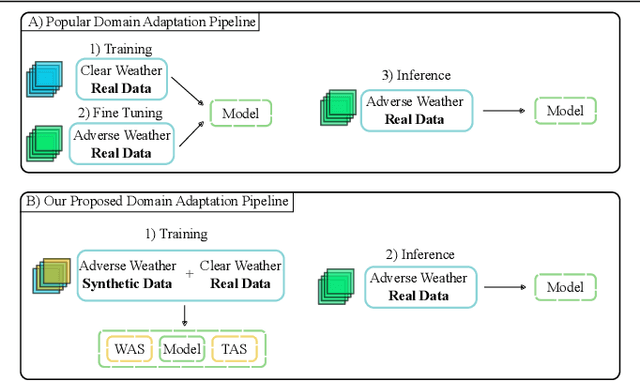


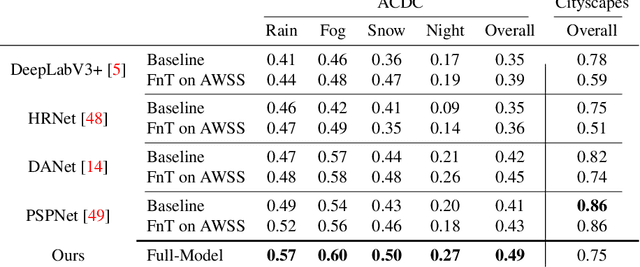
Recent semantic segmentation models perform well under standard weather conditions and sufficient illumination but struggle with adverse weather conditions and nighttime. Collecting and annotating training data under these conditions is expensive, time-consuming, error-prone, and not always practical. Usually, synthetic data is used as a feasible data source to increase the amount of training data. However, just directly using synthetic data may actually harm the model's performance under normal weather conditions while getting only small gains in adverse situations. Therefore, we present a novel architecture specifically designed for using synthetic training data for domain adaptation. We propose a simple yet powerful addition to DeepLabV3+ by using weather and time-of-the-day supervisors trained with multi-task learning, making it both weather and nighttime aware, which improves its mIoU accuracy by $14$ percentage points on the ACDC dataset while maintaining a score of $75\%$ mIoU on the Cityscapes dataset. Our code is available at https://github.com/lsmcolab/Semantic-Segmentation-under-Adverse-Conditions.
Leveraging Synthetic Data to Learn Video Stabilization Under Adverse Conditions
Aug 26, 2022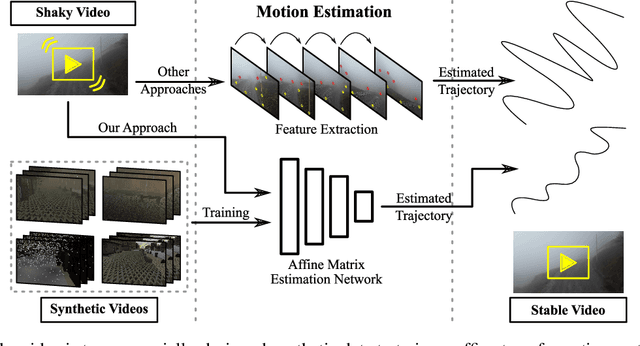
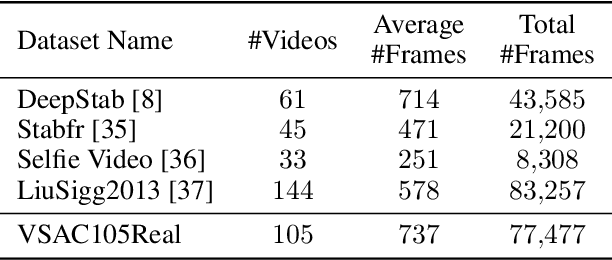
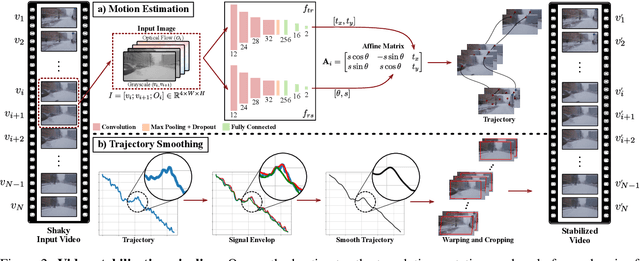
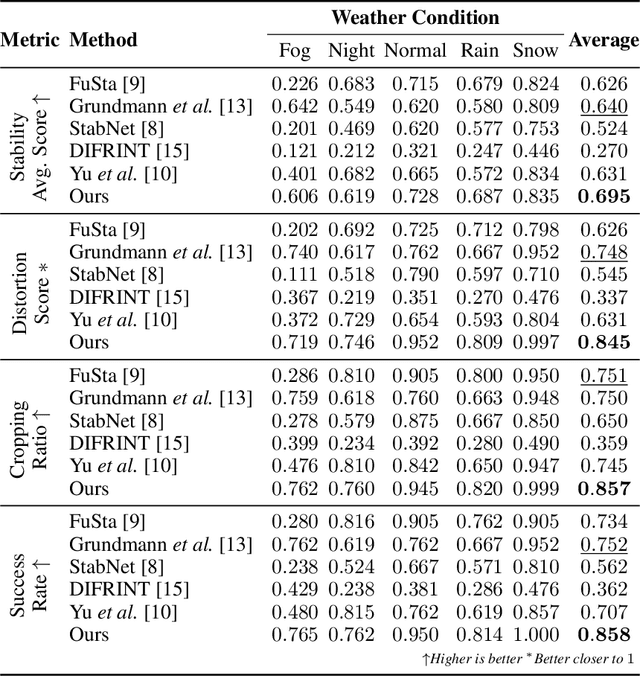
Video stabilization plays a central role to improve videos quality. However, despite the substantial progress made by these methods, they were, mainly, tested under standard weather and lighting conditions, and may perform poorly under adverse conditions. In this paper, we propose a synthetic-aware adverse weather robust algorithm for video stabilization that does not require real data and can be trained only on synthetic data. We also present Silver, a novel rendering engine to generate the required training data with an automatic ground-truth extraction procedure. Our approach uses our specially generated synthetic data for training an affine transformation matrix estimator avoiding the feature extraction issues faced by current methods. Additionally, since no video stabilization datasets under adverse conditions are available, we propose the novel VSAC105Real dataset for evaluation. We compare our method to five state-of-the-art video stabilization algorithms using two benchmarks. Our results show that current approaches perform poorly in at least one weather condition, and that, even training in a small dataset with synthetic data only, we achieve the best performance in terms of stability average score, distortion score, success rate, and average cropping ratio when considering all weather conditions. Hence, our video stabilization model generalizes well on real-world videos and does not require large-scale synthetic training data to converge.
Text-Driven Video Acceleration: A Weakly-Supervised Reinforcement Learning Method
Mar 29, 2022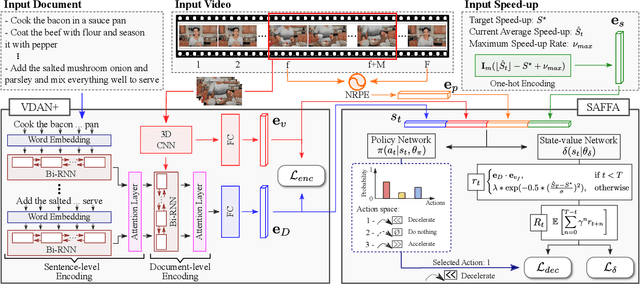

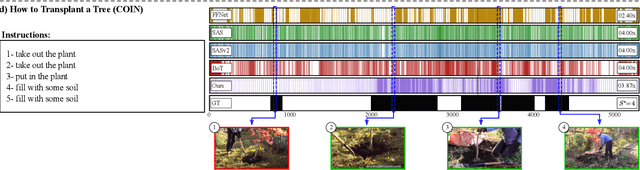
The growth of videos in our digital age and the users' limited time raise the demand for processing untrimmed videos to produce shorter versions conveying the same information. Despite the remarkable progress that summarization methods have made, most of them can only select a few frames or skims, creating visual gaps and breaking the video context. This paper presents a novel weakly-supervised methodology based on a reinforcement learning formulation to accelerate instructional videos using text. A novel joint reward function guides our agent to select which frames to remove and reduce the input video to a target length without creating gaps in the final video. We also propose the Extended Visually-guided Document Attention Network (VDAN+), which can generate a highly discriminative embedding space to represent both textual and visual data. Our experiments show that our method achieves the best performance in Precision, Recall, and F1 Score against the baselines while effectively controlling the video's output length. Visit https://www.verlab.dcc.ufmg.br/semantic-hyperlapse/tpami2022/ for code and extra results.
Congestion control algorithms for robotic swarms with a common target based on the throughput of the target area
Jan 25, 2022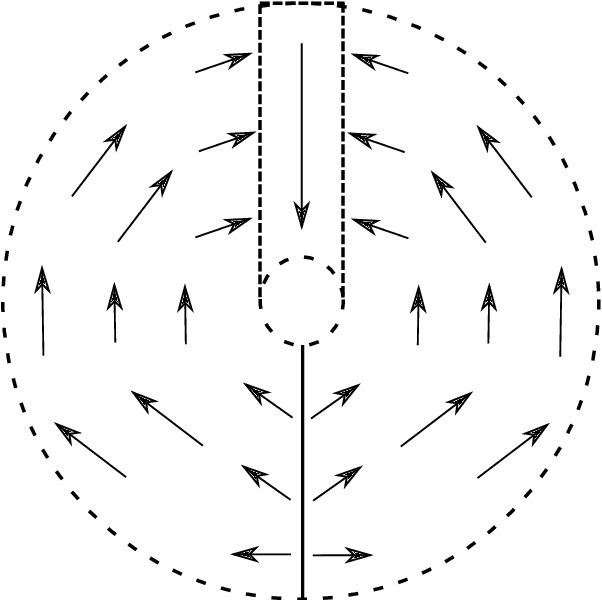
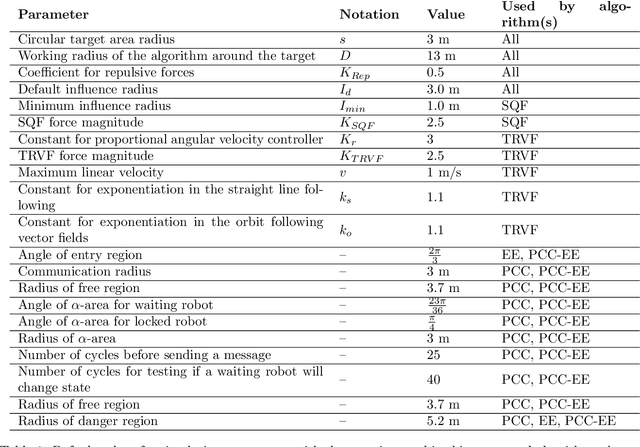
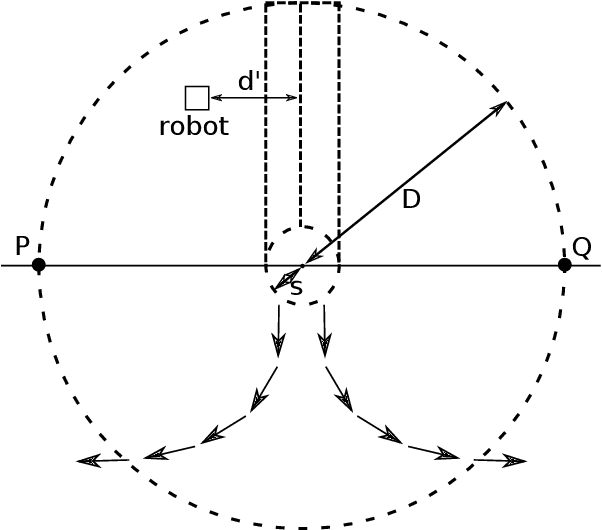

When a large number of robots try to reach a common area, congestions happen, causing severe delays. To minimise congestion in a robotic swarm system, traffic control algorithms must be employed in a decentralised manner. Based on strategies aimed to maximise the throughput of the common target area, we developed two novel algorithms for robots using artificial potential fields for obstacle avoidance and navigation. One algorithm is inspired by creating a queue to get to the target area (Single Queue Former -- SQF), while the other makes the robots touch the boundary of the circular area by using vector fields (Touch and Run Vector Fields -- TRVF). We performed simulation experiments to show that the proposed algorithms are bounded by the throughput of their inspired theoretical strategies and compare the two novel algorithms with state-of-art algorithms for the same problem (PCC, EE and PCC-EE). The SQF algorithm significantly outperforms all other algorithms for a large number of robots or when the circular target region radius is small. TRVF, on the other hand, is better than SQF only for a limited number of robots and outperforms only PCC for numerous robots. However, it allows us to analyse the potential impacts on the throughput when transferring an idea from a theoretical strategy to a concrete algorithm that considers changing velocities and distances between robots.
On the throughput of the common target area for robotic swarm strategies -- extended version
Jan 25, 2022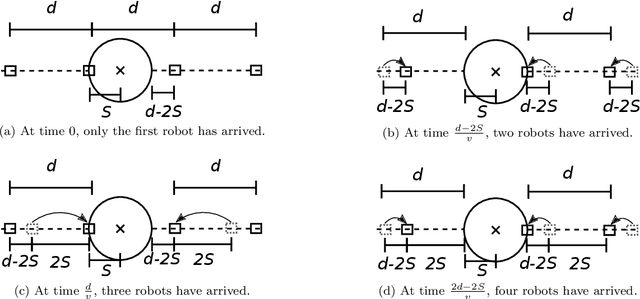
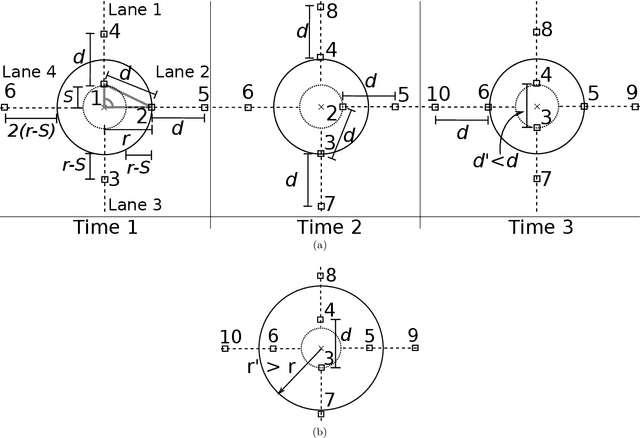
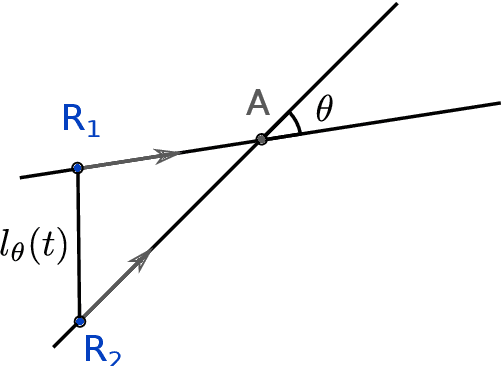
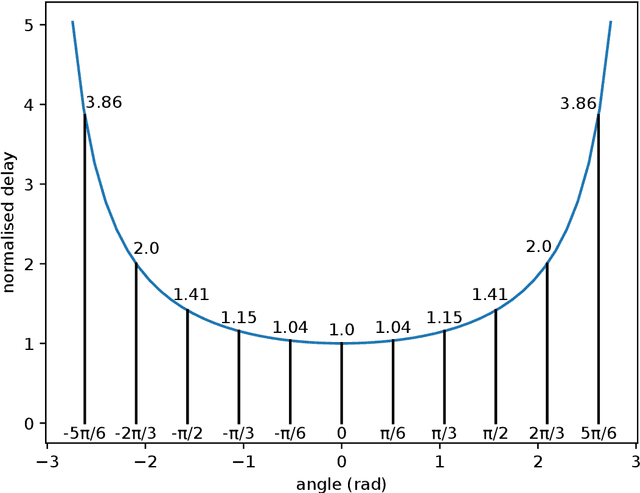
A robotic swarm may encounter traffic congestion when many robots simultaneously attempt to reach the same area. For solving that efficiently, robots must execute decentralised traffic control algorithms. In this work, we propose a measure for evaluating the access efficiency of a common target area as the number of robots in the swarm rises: the common target area throughput. We demonstrate that the throughput of a target region with a limited area as the time tends to infinity -- the asymptotic throughput -- is finite, opposed to the relation arrival time at target per number of robots that tends to infinity. Using this measure, we can analytically compare the effectiveness of different algorithms. In particular, we propose and formally evaluate three different theoretical strategies for getting to a circular target area: (i) forming parallel queues towards the target area, (ii) forming a hexagonal packing through a corridor going to the target, and (iii) making multiple curved trajectories towards the boundary of the target area. We calculate the throughput for a fixed time and the asymptotic throughput for these strategies. Additionally, we corroborate these results by simulations, showing that when an algorithm has higher throughput, its arrival time per number of robots is lower. Thus, we conclude that using throughput is well suited for comparing congestion algorithms for a common target area in robotic swarms even if we do not have their closed asymptotic equation.
Sparse Adversarial Video Attacks with Spatial Transformations
Nov 10, 2021

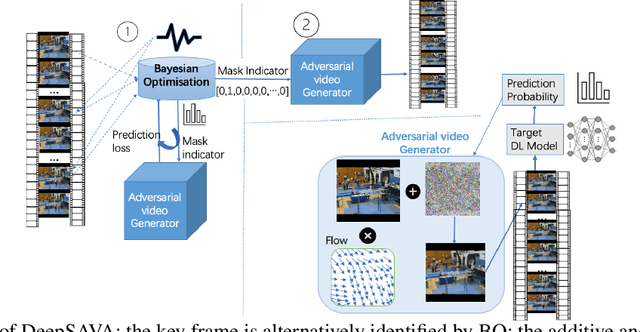

In recent years, a significant amount of research efforts concentrated on adversarial attacks on images, while adversarial video attacks have seldom been explored. We propose an adversarial attack strategy on videos, called DeepSAVA. Our model includes both additive perturbation and spatial transformation by a unified optimisation framework, where the structural similarity index (SSIM) measure is adopted to measure the adversarial distance. We design an effective and novel optimisation scheme which alternatively utilizes Bayesian optimisation to identify the most influential frame in a video and Stochastic gradient descent (SGD) based optimisation to produce both additive and spatial-transformed perturbations. Doing so enables DeepSAVA to perform a very sparse attack on videos for maintaining human imperceptibility while still achieving state-of-the-art performance in terms of both attack success rate and adversarial transferability. Our intensive experiments on various types of deep neural networks and video datasets confirm the superiority of DeepSAVA.
Straight to the Point: Fast-forwarding Videos via Reinforcement Learning Using Textual Data
Mar 31, 2020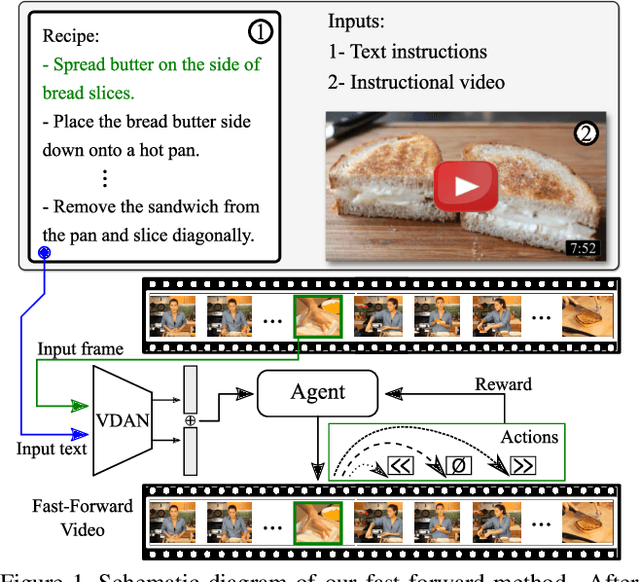
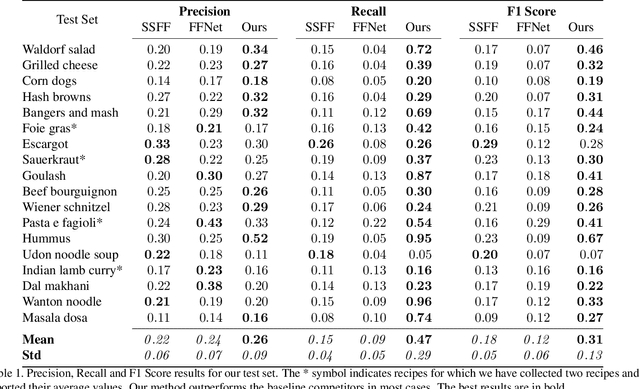
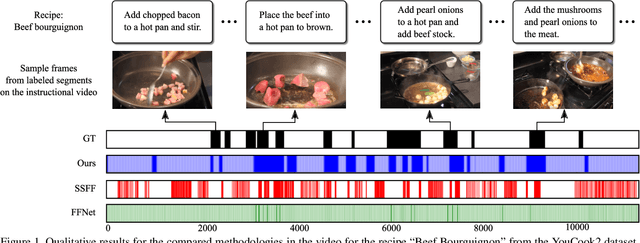
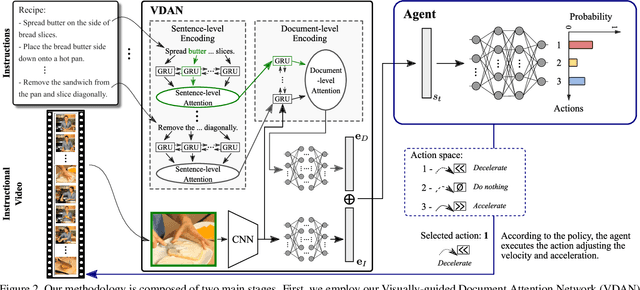
The rapid increase in the amount of published visual data and the limited time of users bring the demand for processing untrimmed videos to produce shorter versions that convey the same information. Despite the remarkable progress that has been made by summarization methods, most of them can only select a few frames or skims, which creates visual gaps and breaks the video context. In this paper, we present a novel methodology based on a reinforcement learning formulation to accelerate instructional videos. Our approach can adaptively select frames that are not relevant to convey the information without creating gaps in the final video. Our agent is textually and visually oriented to select which frames to remove to shrink the input video. Additionally, we propose a novel network, called Visually-guided Document Attention Network (VDAN), able to generate a highly discriminative embedding space to represent both textual and visual data. Our experiments show that our method achieves the best performance in terms of F1 Score and coverage at the video segment level.