 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipal Eigenvalue Regularization for Improved Worst-Class Certified Robustness of Smoothed Classifiers
Mar 21, 2025Recent studies have identified a critical challenge in deep neural networks (DNNs) known as ``robust fairness", where models exhibit significant disparities in robust accuracy across different classes. While prior work has attempted to address this issue in adversarial robustness, the study of worst-class certified robustness for smoothed classifiers remains unexplored. Our work bridges this gap by developing a PAC-Bayesian bound for the worst-class error of smoothed classifiers. Through theoretical analysis, we demonstrate that the largest eigenvalue of the smoothed confusion matrix fundamentally influences the worst-class error of smoothed classifiers. Based on this insight, we introduce a regularization method that optimizes the largest eigenvalue of smoothed confusion matrix to enhance worst-class accuracy of the smoothed classifier and further improve its worst-class certified robustness. We provide extensive experimental validation across multiple datasets and model architectures to demonstrate the effectiveness of our approach.
Invariant Correlation of Representation with Label
Jul 01, 2024



The Invariant Risk Minimization (IRM) approach aims to address the challenge of domain generalization by training a feature representation that remains invariant across multiple environments. However, in noisy environments, IRM-related techniques such as IRMv1 and VREx may be unable to achieve the optimal IRM solution, primarily due to erroneous optimization directions. To address this issue, we introduce ICorr (an abbreviation for \textbf{I}nvariant \textbf{Corr}elation), a novel approach designed to surmount the above challenge in noisy settings. Additionally, we dig into a case study to analyze why previous methods may lose ground while ICorr can succeed. Through a theoretical lens, particularly from a causality perspective, we illustrate that the invariant correlation of representation with label is a necessary condition for the optimal invariant predictor in noisy environments, whereas the optimization motivations for other methods may not be. Furthermore, we empirically demonstrate the effectiveness of ICorr by comparing it with other domain generalization methods on various noisy datasets.
Safeguarding Large Language Models: A Survey
Jun 03, 2024
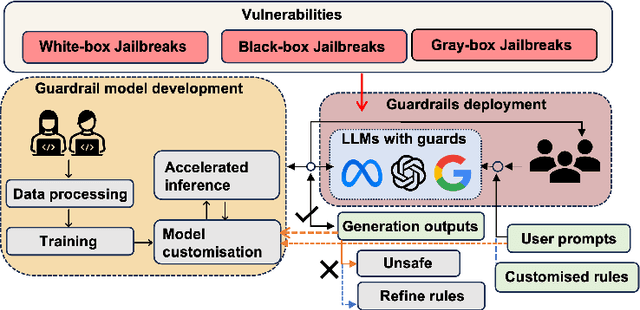
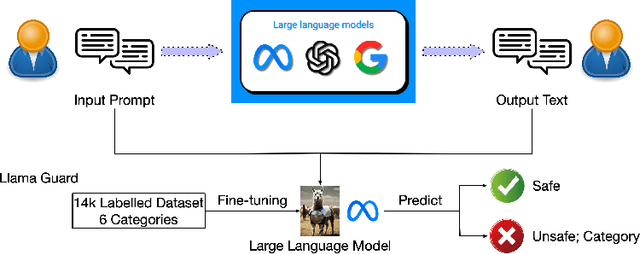
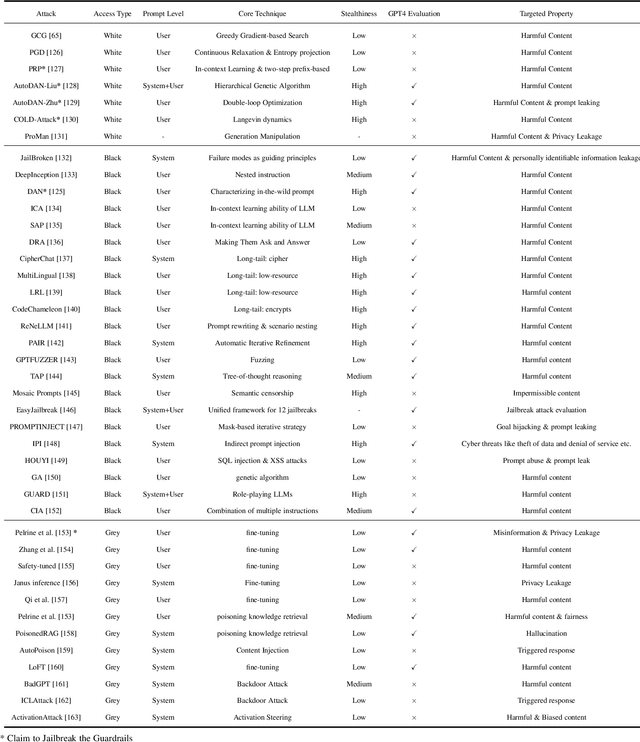
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as "safeguards" or "guardrails", has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
Towards Fairness-Aware Adversarial Learning
Feb 27, 2024Although adversarial training (AT) has proven effective in enhancing the model's robustness, the recently revealed issue of fairness in robustness has not been well addressed, i.e. the robust accuracy varies significantly among different categories. In this paper, instead of uniformly evaluating the model's average class performance, we delve into the issue of robust fairness, by considering the worst-case distribution across various classes. We propose a novel learning paradigm, named Fairness-Aware Adversarial Learning (FAAL). As a generalization of conventional AT, we re-define the problem of adversarial training as a min-max-max framework, to ensure both robustness and fairness of the trained model. Specifically, by taking advantage of distributional robust optimization, our method aims to find the worst distribution among different categories, and the solution is guaranteed to obtain the upper bound performance with high probability. In particular, FAAL can fine-tune an unfair robust model to be fair within only two epochs, without compromising the overall clean and robust accuracies. Extensive experiments on various image datasets validate the superior performance and efficiency of the proposed FAAL compared to other state-of-the-art methods.
Building Guardrails for Large Language Models
Feb 02, 2024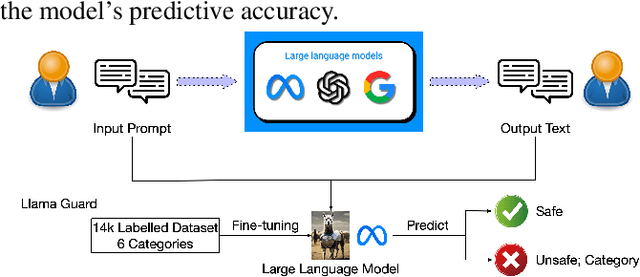
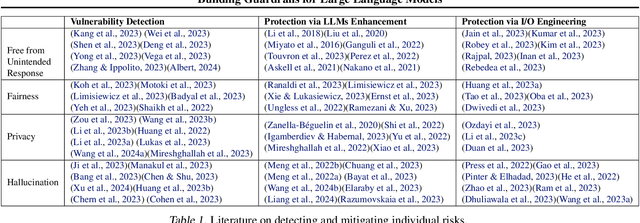


As Large Language Models (LLMs) become more integrated into our daily lives, it is crucial to identify and mitigate their risks, especially when the risks can have profound impacts on human users and societies. Guardrails, which filter the inputs or outputs of LLMs, have emerged as a core safeguarding technology. This position paper takes a deep look at current open-source solutions (Llama Guard, Nvidia NeMo, Guardrails AI), and discusses the challenges and the road towards building more complete solutions. Drawing on robust evidence from previous research, we advocate for a systematic approach to construct guardrails for LLMs, based on comprehensive consideration of diverse contexts across various LLMs applications. We propose employing socio-technical methods through collaboration with a multi-disciplinary team to pinpoint precise technical requirements, exploring advanced neural-symbolic implementations to embrace the complexity of the requirements, and developing verification and testing to ensure the utmost quality of the final product.
Reward Certification for Policy Smoothed Reinforcement Learning
Dec 12, 2023


Reinforcement Learning (RL) has achieved remarkable success in safety-critical areas, but it can be weakened by adversarial attacks. Recent studies have introduced "smoothed policies" in order to enhance its robustness. Yet, it is still challenging to establish a provable guarantee to certify the bound of its total reward. Prior methods relied primarily on computing bounds using Lipschitz continuity or calculating the probability of cumulative reward above specific thresholds. However, these techniques are only suited for continuous perturbations on the RL agent's observations and are restricted to perturbations bounded by the $l_2$-norm. To address these limitations, this paper proposes a general black-box certification method capable of directly certifying the cumulative reward of the smoothed policy under various $l_p$-norm bounded perturbations. Furthermore, we extend our methodology to certify perturbations on action spaces. Our approach leverages f-divergence to measure the distinction between the original distribution and the perturbed distribution, subsequently determining the certification bound by solving a convex optimisation problem. We provide a comprehensive theoretical analysis and run sufficient experiments in multiple environments. Our results show that our method not only improves the certified lower bound of mean cumulative reward but also demonstrates better efficiency than state-of-the-art techniques.
A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
May 19, 2023



Large Language Models (LLMs) have exploded a new heatwave of AI, for their ability to engage end-users in human-level conversations with detailed and articulate answers across many knowledge domains. In response to their fast adoption in many industrial applications, this survey concerns their safety and trustworthiness. First, we review known vulnerabilities of the LLMs, categorising them into inherent issues, intended attacks, and unintended bugs. Then, we consider if and how the Verification and Validation (V&V) techniques, which have been widely developed for traditional software and deep learning models such as convolutional neural networks, can be integrated and further extended throughout the lifecycle of the LLMs to provide rigorous analysis to the safety and trustworthiness of LLMs and their applications. Specifically, we consider four complementary techniques: falsification and evaluation, verification, runtime monitoring, and ethical use. Considering the fast development of LLMs, this survey does not intend to be complete (although it includes 300 references), especially when it comes to the applications of LLMs in various domains, but rather a collection of organised literature reviews and discussions to support the quick understanding of the safety and trustworthiness issues from the perspective of V&V.
Randomized Adversarial Training via Taylor Expansion
Mar 19, 2023



In recent years, there has been an explosion of research into developing more robust deep neural networks against adversarial examples. Adversarial training appears as one of the most successful methods. To deal with both the robustness against adversarial examples and the accuracy over clean examples, many works develop enhanced adversarial training methods to achieve various trade-offs between them. Leveraging over the studies that smoothed update on weights during training may help find flat minima and improve generalization, we suggest reconciling the robustness-accuracy trade-off from another perspective, i.e., by adding random noise into deterministic weights. The randomized weights enable our design of a novel adversarial training method via Taylor expansion of a small Gaussian noise, and we show that the new adversarial training method can flatten loss landscape and find flat minima. With PGD, CW, and Auto Attacks, an extensive set of experiments demonstrate that our method enhances the state-of-the-art adversarial training methods, boosting both robustness and clean accuracy. The code is available at https://github.com/Alexkael/Randomized-Adversarial-Training.
Certified Policy Smoothing for Cooperative Multi-Agent Reinforcement Learning
Dec 22, 2022Cooperative multi-agent reinforcement learning (c-MARL) is widely applied in safety-critical scenarios, thus the analysis of robustness for c-MARL models is profoundly important. However, robustness certification for c-MARLs has not yet been explored in the community. In this paper, we propose a novel certification method, which is the first work to leverage a scalable approach for c-MARLs to determine actions with guaranteed certified bounds. c-MARL certification poses two key challenges compared with single-agent systems: (i) the accumulated uncertainty as the number of agents increases; (ii) the potential lack of impact when changing the action of a single agent into a global team reward. These challenges prevent us from directly using existing algorithms. Hence, we employ the false discovery rate (FDR) controlling procedure considering the importance of each agent to certify per-state robustness and propose a tree-search-based algorithm to find a lower bound of the global reward under the minimal certified perturbation. As our method is general, it can also be applied in single-agent environments. We empirically show that our certification bounds are much tighter than state-of-the-art RL certification solutions. We also run experiments on two popular c-MARL algorithms: QMIX and VDN, in two different environments, with two and four agents. The experimental results show that our method produces meaningful guaranteed robustness for all models and environments. Our tool CertifyCMARL is available at https://github.com/TrustAI/CertifyCMA
3DVerifier: Efficient Robustness Verification for 3D Point Cloud Models
Jul 15, 2022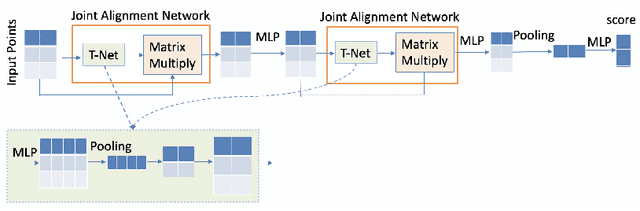


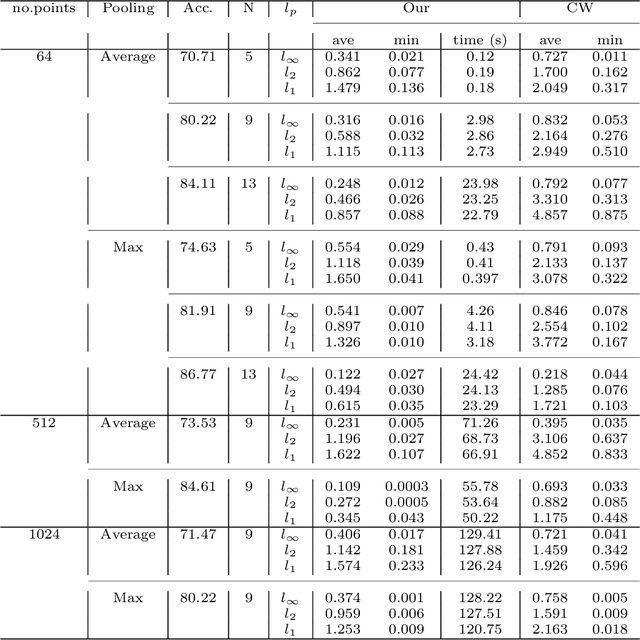
3D point cloud models are widely applied in safety-critical scenes, which delivers an urgent need to obtain more solid proofs to verify the robustness of models. Existing verification method for point cloud model is time-expensive and computationally unattainable on large networks. Additionally, they cannot handle the complete PointNet model with joint alignment network (JANet) that contains multiplication layers, which effectively boosts the performance of 3D models. This motivates us to design a more efficient and general framework to verify various architectures of point cloud models. The key challenges in verifying the large-scale complete PointNet models are addressed as dealing with the cross-non-linearity operations in the multiplication layers and the high computational complexity of high-dimensional point cloud inputs and added layers. Thus, we propose an efficient verification framework, 3DVerifier, to tackle both challenges by adopting a linear relaxation function to bound the multiplication layer and combining forward and backward propagation to compute the certified bounds of the outputs of the point cloud models. Our comprehensive experiments demonstrate that 3DVerifier outperforms existing verification algorithms for 3D models in terms of both efficiency and accuracy. Notably, our approach achieves an orders-of-magnitude improvement in verification efficiency for the large network, and the obtained certified bounds are also significantly tighter than the state-of-the-art verifiers. We release our tool 3DVerifier via https://github.com/TrustAI/3DVerifier for use by the community.