 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Aware PAC-Bayesian Generalization Analysis for Graph Neural Networks
Apr 12, 2026Graph neural networks have demonstrated excellent applicability to a wide range of domains, including social networks, biological systems, recommendation systems, and wireless communications. Yet a principled theoretical understanding of their generalization behavior remains limited, particularly for graph classification tasks where complex interactions between model parameters and graph structure play a crucial role. Among existing theoretical tools, PAC-Bayesian norm-based generalization bounds provide a flexible and data-dependent framework; however, current results for GNNs often restrict the exploitation of graph structures. In this work, we propose a topology-aware PAC-Bayesian norm-based generalization framework for graph convolutional networks (GCNs) that extends a previously developed framework to graph-structured models. Our approach reformulates the derivation of generalization bounds as a stochastic optimization problem and introduces sensitivity matrices that measure the response of classification outputs with respect to structured weight perturbations. By imposing different structures on sensitivity matrices from both spatial and spectral perspectives, we derive a family of generalization error bounds with graph structures explicitly embedded. Such bounds could recover existing results as special cases, while yielding bounds that are tighter than state-of-the-art PAC-Bayesian bounds for GNNs. Notably, the proposed framework explicitly integrates graph structural properties into the generalization analysis, enabling a unified inspection of GNN generalization behavior from both spatial aggregation and spectral filtering viewpoints.
S2O: Enhancing Adversarial Training with Second-Order Statistics of Weights
Mar 01, 2026Adversarial training has emerged as a highly effective way to improve the robustness of deep neural networks (DNNs). It is typically conceptualized as a min-max optimization problem over model weights and adversarial perturbations, where the weights are optimized using gradient descent methods, such as SGD. In this paper, we propose a novel approach by treating model weights as random variables, which paves the way for enhancing adversarial training through \textbf{S}econd-Order \textbf{S}tatistics \textbf{O}ptimization (S$^2$O) over model weights. We challenge and relax a prevalent, yet often unrealistic, assumption in prior PAC-Bayesian frameworks: the statistical independence of weights. From this relaxation, we derive an improved PAC-Bayesian robust generalization bound. Our theoretical developments suggest that optimizing the second-order statistics of weights can substantially tighten this bound. We complement this theoretical insight by conducting an extensive set of experiments that demonstrate that S$^2$O not only enhances the robustness and generalization of neural networks when used in isolation, but also seamlessly augments other state-of-the-art adversarial training techniques. The code is available at https://github.com/Alexkael/S2O.
Towards A Unified PAC-Bayesian Framework for Norm-based Generalization Bounds
Jan 13, 2026Understanding the generalization behavior of deep neural networks remains a fundamental challenge in modern statistical learning theory. Among existing approaches, PAC-Bayesian norm-based bounds have demonstrated particular promise due to their data-dependent nature and their ability to capture algorithmic and geometric properties of learned models. However, most existing results rely on isotropic Gaussian posteriors, heavy use of spectral-norm concentration for weight perturbations, and largely architecture-agnostic analyses, which together limit both the tightness and practical relevance of the resulting bounds. To address these limitations, in this work, we propose a unified framework for PAC-Bayesian norm-based generalization by reformulating the derivation of generalization bounds as a stochastic optimization problem over anisotropic Gaussian posteriors. The key to our approach is a sensitivity matrix that quantifies the network outputs with respect to structured weight perturbations, enabling the explicit incorporation of heterogeneous parameter sensitivities and architectural structures. By imposing different structural assumptions on this sensitivity matrix, we derive a family of generalization bounds that recover several existing PAC-Bayesian results as special cases, while yielding bounds that are comparable to or tighter than state-of-the-art approaches. Such a unified framework provides a principled and flexible way for geometry-/structure-aware and interpretable generalization analysis in deep learning.
Learning to Unfold Fractional Programming for Multi-Cell MU-MIMO Beamforming with Graph Neural Networks
Jan 12, 2026In the multi-cell multiuser multi-input multi-output (MU-MIMO) systems, fractional programming (FP) has demonstrated considerable effectiveness in optimizing beamforming vectors, yet it suffers from high computational complexity. Recent improvements demonstrate reduced complexity by avoiding large-dimension matrix inversions (i.e., FastFP) and faster convergence by learning to unfold the FastFP algorithm (i.e., DeepFP).
Unlocking Symbol-Level Precoding Efficiency Through Tensor Equivariant Neural Network
Oct 02, 2025Although symbol-level precoding (SLP) based on constructive interference (CI) exploitation offers performance gains, its high complexity remains a bottleneck. This paper addresses this challenge with an end-to-end deep learning (DL) framework with low inference complexity that leverages the structure of the optimal SLP solution in the closed-form and its inherent tensor equivariance (TE), where TE denotes that a permutation of the input induces the corresponding permutation of the output. Building upon the computationally efficient model-based formulations, as well as their known closed-form solutions, we analyze their relationship with linear precoding (LP) and investigate the corresponding optimality condition. We then construct a mapping from the problem formulation to the solution and prove its TE, based on which the designed networks reveal a specific parameter-sharing pattern that delivers low computational complexity and strong generalization. Leveraging these, we propose the backbone of the framework with an attention-based TE module, achieving linear computational complexity. Furthermore, we demonstrate that such a framework is also applicable to imperfect CSI scenarios, where we design a TE-based network to map the CSI, statistics, and symbols to auxiliary variables. Simulation results show that the proposed framework captures substantial performance gains of optimal SLP, while achieving an approximately 80-times speedup over conventional methods and maintaining strong generalization across user numbers and symbol block lengths.
Tensor-Structured Bayesian Channel Prediction for Upper Mid-Band XL-MIMO Systems
Aug 11, 2025The upper mid-band balances coverage and capacity for the future cellular systems and also embraces XL-MIMO systems, offering enhanced spectral and energy efficiency. However, these benefits are significantly degraded under mobility due to channel aging, and further exacerbated by the unique near-field (NF) and spatial non-stationarity (SnS) propagation in such systems. To address this challenge, we propose a novel channel prediction approach that incorporates dedicated channel modeling, probabilistic representations, and Bayesian inference algorithms for this emerging scenario. Specifically, we develop tensor-structured channel models in both the spatial-frequency-temporal (SFT) and beam-delay-Doppler (BDD) domains, which leverage temporal correlations among multiple pilot symbols for channel prediction. The factor matrices of multi-linear transformations are parameterized by BDD domain grids and SnS factors, where beam domain grids are jointly determined by angles and slopes under spatial-chirp based NF representations. To enable tractable inference, we replace environment-dependent BDD domain grids with uniformly sampled ones, and introduce perturbation parameters in each domain to mitigate grid mismatch. We further propose a hybrid beam domain strategy that integrates angle-only sampling with slope hyperparameterization to avoid the computational burden of explicit slope sampling. Based on the probabilistic models, we develop tensor-structured bi-layer inference (TS-BLI) algorithm under the expectation-maximization (EM) framework, which reduces computational complexity via tensor operations by leveraging the bi-layer factor graph for approximate E-step inference and an alternating strategy with closed-form updates in the M-step. Numerical simulations based on the near-practical channel simulator demonstrate the superior channel prediction performance of the proposed algorithm.
A Tensor-Structured Approach to Dynamic Channel Prediction for Massive MIMO Systems with Temporal Non-Stationarity
Dec 09, 2024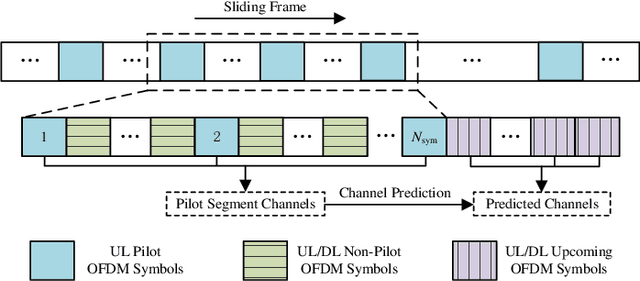
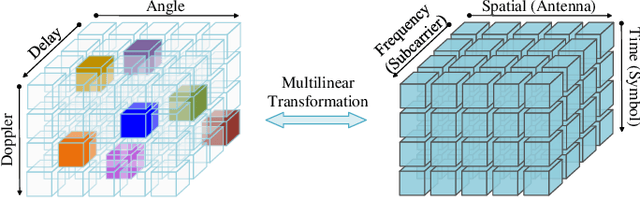
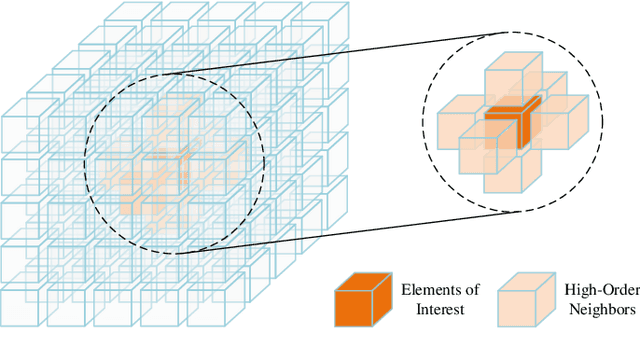
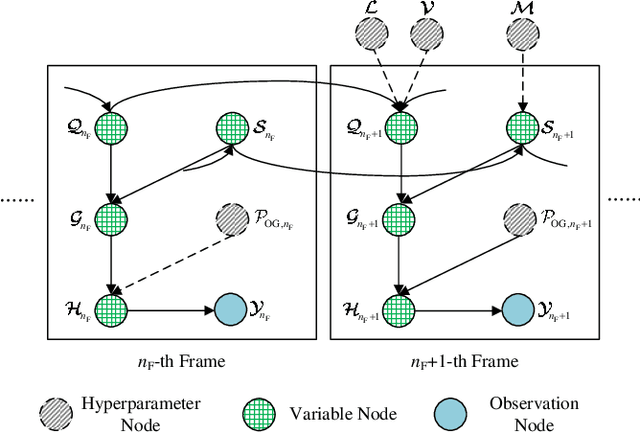
In moderate- to high-mobility scenarios, channel state information (CSI) varies rapidly and becomes temporally non-stationary, leading to significant performance degradation in channel reciprocity-dependent massive multiple-input multiple-output (MIMO) transmission. To address this challenge, we propose a tensor-structured approach to dynamic channel prediction (TS-DCP) for massive MIMO systems with temporal non-stationarity, leveraging dual-timescale and cross-domain correlations. Specifically, due to the inherent spatial consistency, non-stationary channels on long-timescales are treated as stationary on short-timescales, decoupling complicated correlations into more tractable dual-timescale ones. To exploit such property, we frame the pilot symbols, capturing short-timescale correlations within frames by Doppler domain modeling and long-timescale correlations across frames by Markov/autoregressive processes. Based on this, we develop the tensor-structured signal model in the spatial-frequency-temporal domain, incorporating correlated angle-delay-Doppler domain channels and Vandermonde-structured factor matrices. Furthermore, we model cross-domain correlations within each frame, arising from clustered scatterer distributions, using tensor-structured upgradations of Markov processes and coupled Gaussian distributions. Following these probabilistic models, we formulate the TS-DCP as the variational free energy (VFE) minimization problem, designing trial belief structures through online approximation and the Bethe method. This yields the online TS-DCP algorithm derived from a dual-layer VFE optimization process, where both outer and inner layers leverage the multilinear structure of channels to reduce computational complexity significantly. Numerical simulations demonstrate the significant superiority of the proposed algorithm over benchmarks in terms of channel prediction performance.
Joint User Scheduling and Precoding for RIS-Aided MU-MISO Systems: A MADRL Approach
Oct 25, 2024With the increasing demand for spectrum efficiency and energy efficiency, reconfigurable intelligent surfaces (RISs) have attracted massive attention due to its low-cost and capability of controlling wireless environment. However, there is still a lack of treatments to deal with the growth of the number of users and RIS elements, which may incur performance degradation or computational complexity explosion. In this paper, we investigate the joint optimization of user scheduling and precoding for distributed RIS-aided communication systems. Firstly, we propose an optimization-based numerical method to obtain suboptimal solutions with the aid of the approximation of ergodic sum rate. Secondly, to reduce the computational complexity caused by the high dimensionality, we propose a data-driven scalable and generalizable multi-agent deep reinforcement learning (MADRL) framework with the aim to maximize the ergodic sum rate approximation through the cooperation of all agents. Further, we propose a novel dynamic working process exploiting the trained MADRL algorithm, which enables distributed RISs to configure their own passive precoding independently. Simulation results show that our algorithm substantially reduces the computational complexity by a time reduction of three orders of magnitude at the cost of 3% performance degradation, compared with the optimization-based method, and achieves 6% performance improvement over the state-of-the-art MADRL algorithms.
Robust RL with LLM-Driven Data Synthesis and Policy Adaptation for Autonomous Driving
Oct 16, 2024



The integration of Large Language Models (LLMs) into autonomous driving systems demonstrates strong common sense and reasoning abilities, effectively addressing the pitfalls of purely data-driven methods. Current LLM-based agents require lengthy inference times and face challenges in interacting with real-time autonomous driving environments. A key open question is whether we can effectively leverage the knowledge from LLMs to train an efficient and robust Reinforcement Learning (RL) agent. This paper introduces RAPID, a novel \underline{\textbf{R}}obust \underline{\textbf{A}}daptive \underline{\textbf{P}}olicy \underline{\textbf{I}}nfusion and \underline{\textbf{D}}istillation framework, which trains specialized mix-of-policy RL agents using data synthesized by an LLM-based driving agent and online adaptation. RAPID features three key designs: 1) utilization of offline data collected from an LLM agent to distil expert knowledge into RL policies for faster real-time inference; 2) introduction of robust distillation in RL to inherit both performance and robustness from LLM-based teacher; and 3) employment of a mix-of-policy approach for joint decision decoding with a policy adapter. Through fine-tuning via online environment interaction, RAPID reduces the forgetting of LLM knowledge while maintaining adaptability to different tasks. Extensive experiments demonstrate RAPID's capability to effectively integrate LLM knowledge into scaled-down RL policies in an efficient, adaptable, and robust way. Code and checkpoints will be made publicly available upon acceptance.
Meta-Learning Empowered Graph Neural Networks for Radio Resource Management
Aug 29, 2024



In this paper, we consider a radio resource management (RRM) problem in the dynamic wireless networks, comprising multiple communication links that share the same spectrum resource. To achieve high network throughput while ensuring fairness across all links, we formulate a resilient power optimization problem with per-user minimum-rate constraints. We obtain the corresponding Lagrangian dual problem and parameterize all variables with neural networks, which can be trained in an unsupervised manner due to the provably acceptable duality gap. We develop a meta-learning approach with graph neural networks (GNNs) as parameterization that exhibits fast adaptation and scalability to varying network configurations. We formulate the objective of meta-learning by amalgamating the Lagrangian functions of different network configurations and utilize a first-order meta-learning algorithm, called Reptile, to obtain the meta-parameters. Numerical results verify that our method can efficiently improve the overall throughput and ensure the minimum rate performance. We further demonstrate that using the meta-parameters as initialization, our method can achieve fast adaptation to new wireless network configurations and reduce the number of required training data samples.