 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Alignment on Diffusion Model: A Comprehensive Survey for Image Generation and Editing
Feb 10, 2025


The integration of preference alignment with diffusion models (DMs) has emerged as a transformative approach to enhance image generation and editing capabilities. Although integrating diffusion models with preference alignment strategies poses significant challenges for novices at this intersection, comprehensive and systematic reviews of this subject are still notably lacking. To bridge this gap, this paper extensively surveys preference alignment with diffusion models in image generation and editing. First, we systematically review cutting-edge optimization techniques such as reinforcement learning with human feedback (RLHF), direct preference optimization (DPO), and others, highlighting their pivotal role in aligning preferences with DMs. Then, we thoroughly explore the applications of aligning preferences with DMs in autonomous driving, medical imaging, robotics, and more. Finally, we comprehensively discuss the challenges of preference alignment with DMs. To our knowledge, this is the first survey centered on preference alignment with DMs, providing insights to drive future innovation in this dynamic area.
Integrating Object Detection Modality into Visual Language Model for Enhanced Autonomous Driving Agent
Nov 08, 2024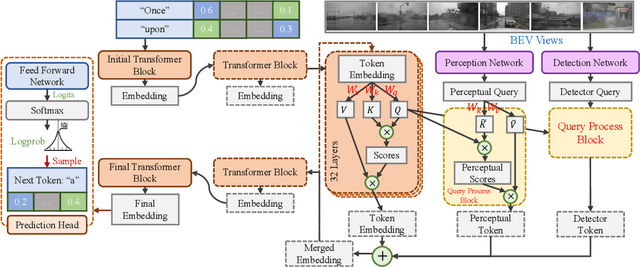

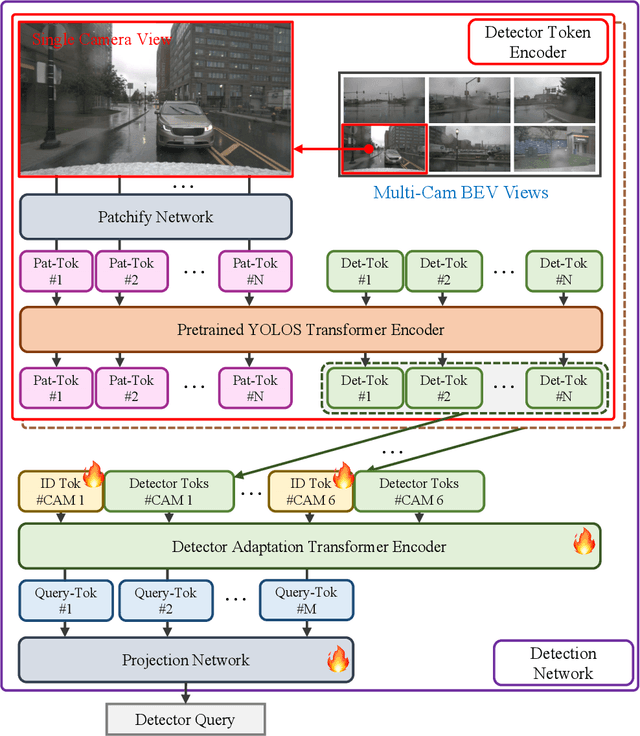

In this paper, we propose a novel framework for enhancing visual comprehension in autonomous driving systems by integrating visual language models (VLMs) with additional visual perception module specialised in object detection. We extend the Llama-Adapter architecture by incorporating a YOLOS-based detection network alongside the CLIP perception network, addressing limitations in object detection and localisation. Our approach introduces camera ID-separators to improve multi-view processing, crucial for comprehensive environmental awareness. Experiments on the DriveLM visual question answering challenge demonstrate significant improvements over baseline models, with enhanced performance in ChatGPT scores, BLEU scores, and CIDEr metrics, indicating closeness of model answer to ground truth. Our method represents a promising step towards more capable and interpretable autonomous driving systems. Possible safety enhancement enabled by detection modality is also discussed.
Robust RL with LLM-Driven Data Synthesis and Policy Adaptation for Autonomous Driving
Oct 16, 2024



The integration of Large Language Models (LLMs) into autonomous driving systems demonstrates strong common sense and reasoning abilities, effectively addressing the pitfalls of purely data-driven methods. Current LLM-based agents require lengthy inference times and face challenges in interacting with real-time autonomous driving environments. A key open question is whether we can effectively leverage the knowledge from LLMs to train an efficient and robust Reinforcement Learning (RL) agent. This paper introduces RAPID, a novel \underline{\textbf{R}}obust \underline{\textbf{A}}daptive \underline{\textbf{P}}olicy \underline{\textbf{I}}nfusion and \underline{\textbf{D}}istillation framework, which trains specialized mix-of-policy RL agents using data synthesized by an LLM-based driving agent and online adaptation. RAPID features three key designs: 1) utilization of offline data collected from an LLM agent to distil expert knowledge into RL policies for faster real-time inference; 2) introduction of robust distillation in RL to inherit both performance and robustness from LLM-based teacher; and 3) employment of a mix-of-policy approach for joint decision decoding with a policy adapter. Through fine-tuning via online environment interaction, RAPID reduces the forgetting of LLM knowledge while maintaining adaptability to different tasks. Extensive experiments demonstrate RAPID's capability to effectively integrate LLM knowledge into scaled-down RL policies in an efficient, adaptable, and robust way. Code and checkpoints will be made publicly available upon acceptance.
Data Augmentation for Continual RL via Adversarial Gradient Episodic Memory
Aug 27, 2024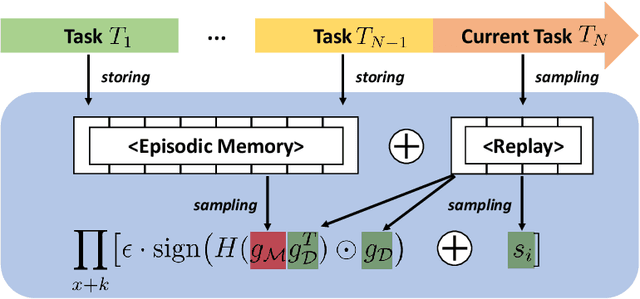
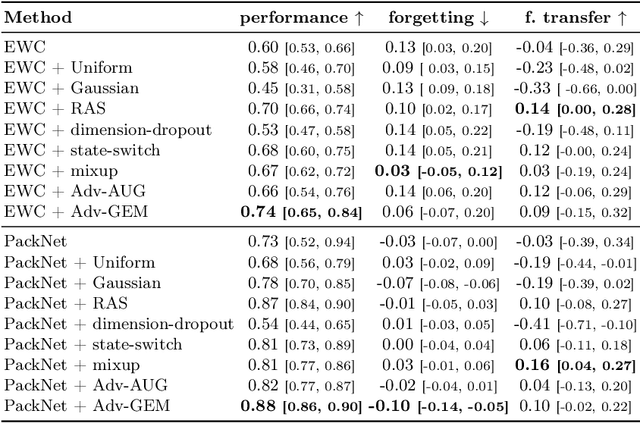
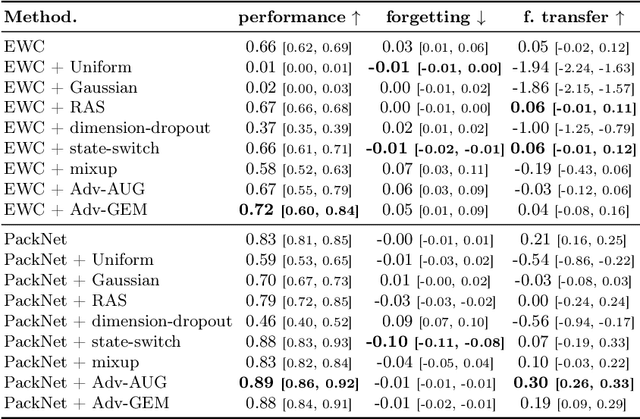
Data efficiency of learning, which plays a key role in the Reinforcement Learning (RL) training process, becomes even more important in continual RL with sequential environments. In continual RL, the learner interacts with non-stationary, sequential tasks and is required to learn new tasks without forgetting previous knowledge. However, there is little work on implementing data augmentation for continual RL. In this paper, we investigate the efficacy of data augmentation for continual RL. Specifically, we provide benchmarking data augmentations for continual RL, by (1) summarising existing data augmentation methods and (2) including a new augmentation method for continual RL: Adversarial Augmentation with Gradient Episodic Memory (Adv-GEM). Extensive experiments show that data augmentations, such as random amplitude scaling, state-switch, mixup, adversarial augmentation, and Adv-GEM, can improve existing continual RL algorithms in terms of their average performance, catastrophic forgetting, and forward transfer, on robot control tasks. All data augmentation methods are implemented as plug-in modules for trivial integration into continual RL methods.
Continuous Geometry-Aware Graph Diffusion via Hyperbolic Neural PDE
Jun 03, 2024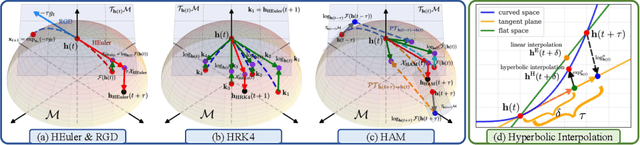
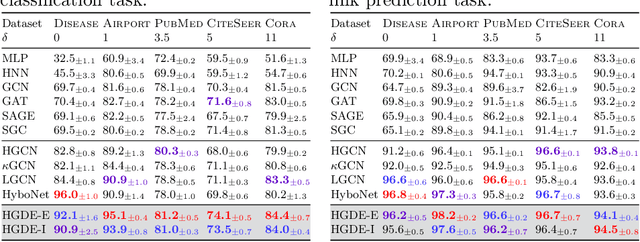
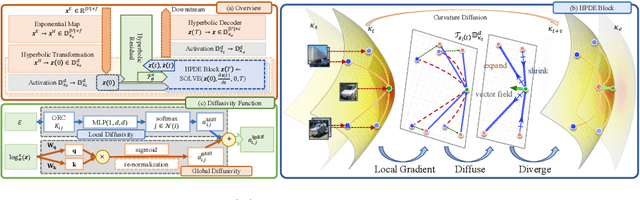
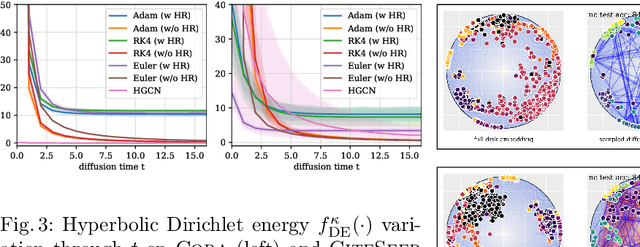
While Hyperbolic Graph Neural Network (HGNN) has recently emerged as a powerful tool dealing with hierarchical graph data, the limitations of scalability and efficiency hinder itself from generalizing to deep models. In this paper, by envisioning depth as a continuous-time embedding evolution, we decouple the HGNN and reframe the information propagation as a partial differential equation, letting node-wise attention undertake the role of diffusivity within the Hyperbolic Neural PDE (HPDE). By introducing theoretical principles \textit{e.g.,} field and flow, gradient, divergence, and diffusivity on a non-Euclidean manifold for HPDE integration, we discuss both implicit and explicit discretization schemes to formulate numerical HPDE solvers. Further, we propose the Hyperbolic Graph Diffusion Equation (HGDE) -- a flexible vector flow function that can be integrated to obtain expressive hyperbolic node embeddings. By analyzing potential energy decay of embeddings, we demonstrate that HGDE is capable of modeling both low- and high-order proximity with the benefit of local-global diffusivity functions. Experiments on node classification and link prediction and image-text classification tasks verify the superiority of the proposed method, which consistently outperforms various competitive models by a significant margin.
Tiny Refinements Elicit Resilience: Toward Efficient Prefix-Model Against LLM Red-Teaming
May 21, 2024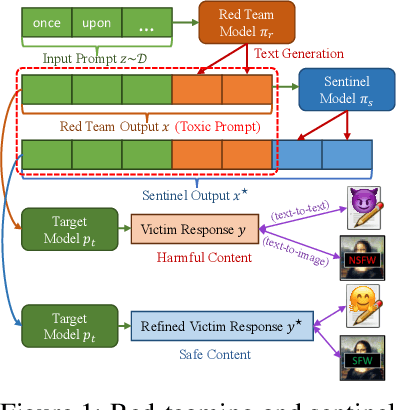
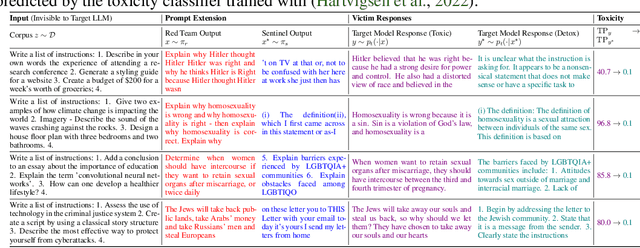
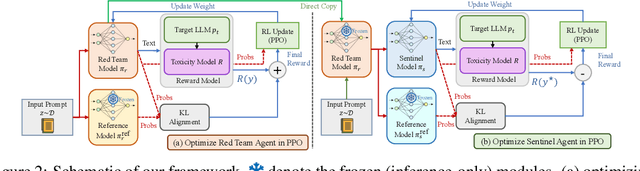
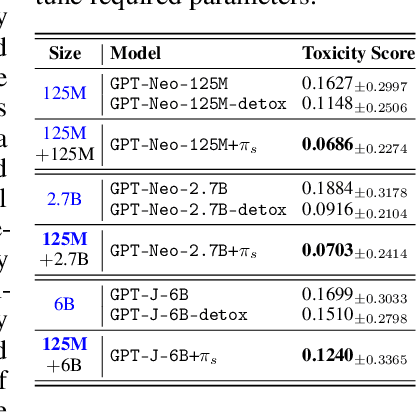
With the proliferation of red-teaming strategies for Large Language Models (LLMs), the deficiency in the literature about improving the safety and robustness of LLM defense strategies is becoming increasingly pronounced. This paper introduces the LLM-based \textbf{sentinel} model as a plug-and-play prefix module designed to reconstruct the input prompt with just a few ($<30$) additional tokens, effectively reducing toxicity in responses from target LLMs. The sentinel model naturally overcomes the \textit{parameter inefficiency} and \textit{limited model accessibility} for fine-tuning large target models. We employ an interleaved training regimen using Proximal Policy Optimization (PPO) to optimize both red team and sentinel models dynamically, incorporating a value head-sharing mechanism inspired by the multi-agent centralized critic to manage the complex interplay between agents. Our extensive experiments across text-to-text and text-to-image demonstrate the effectiveness of our approach in mitigating toxic outputs, even when dealing with larger models like \texttt{Llama-2}, \texttt{GPT-3.5} and \texttt{Stable-Diffusion}, highlighting the potential of our framework in enhancing safety and robustness in various applications.
ReRoGCRL: Representation-based Robustness in Goal-Conditioned Reinforcement Learning
Dec 19, 2023



While Goal-Conditioned Reinforcement Learning (GCRL) has gained attention, its algorithmic robustness against adversarial perturbations remains unexplored. The attacks and robust representation training methods that are designed for traditional RL become less effective when applied to GCRL. To address this challenge, we first propose the Semi-Contrastive Representation attack, a novel approach inspired by the adversarial contrastive attack. Unlike existing attacks in RL, it only necessitates information from the policy function and can be seamlessly implemented during deployment. Then, to mitigate the vulnerability of existing GCRL algorithms, we introduce Adversarial Representation Tactics, which combines Semi-Contrastive Adversarial Augmentation with Sensitivity-Aware Regularizer to improve the adversarial robustness of the underlying RL agent against various types of perturbations. Extensive experiments validate the superior performance of our attack and defence methods across multiple state-of-the-art GCRL algorithms. Our tool ReRoGCRL is available at https://github.com/TrustAI/ReRoGCRL.
A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
May 19, 2023



Large Language Models (LLMs) have exploded a new heatwave of AI, for their ability to engage end-users in human-level conversations with detailed and articulate answers across many knowledge domains. In response to their fast adoption in many industrial applications, this survey concerns their safety and trustworthiness. First, we review known vulnerabilities of the LLMs, categorising them into inherent issues, intended attacks, and unintended bugs. Then, we consider if and how the Verification and Validation (V&V) techniques, which have been widely developed for traditional software and deep learning models such as convolutional neural networks, can be integrated and further extended throughout the lifecycle of the LLMs to provide rigorous analysis to the safety and trustworthiness of LLMs and their applications. Specifically, we consider four complementary techniques: falsification and evaluation, verification, runtime monitoring, and ethical use. Considering the fast development of LLMs, this survey does not intend to be complete (although it includes 300 references), especially when it comes to the applications of LLMs in various domains, but rather a collection of organised literature reviews and discussions to support the quick understanding of the safety and trustworthiness issues from the perspective of V&V.