 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDive into Ambiguity: A*-Inspired Multi-Agents Commonsense Obfuscation Attack on LLM Prompts
May 31, 2026Large language models (LLMs) excel in reasoning and knowledge-intensive tasks but remain vulnerable to prompt-level adversarial attacks that preserve intent while triggering commonsense hallucinations. This vulnerability is urgent, as LLMs are rapidly integrated into safety-critical domains where factual reliability is non-negotiable. Existing attack methods either lack efficiency or fail to capture the adaptive strategies of real-world adversaries. We propose an A*-inspired Factual Error Induction Framework, a framework for generating semantically aligned yet obfuscated prompts. At its core is a Hierarchical Rewrite Strategy guided by a dynamic semantic dispersion coefficient $γ$ that balances conservative edits early with aggressive obfuscations later, following a reverse simulated annealing schedule. To enhance interpretability, we further introduce Agentic Mechanism Labeling, which discovers and refines adversarial mechanisms, offering interpretable reverse optimization. Theoretically, we prove that prompt rewriting follows a contractive recurrence, leading to semantic collapse as $γ$ decreases. Empirically, across diverse LLMs, our method achieves higher attack success rates than exhaustive exploration while requiring fewer attempts, demonstrating both efficiency and effectiveness.
Safety-Constrained Reinforcement Learning with Post-Training Reachability Verification for Robot Navigation
May 13, 2026Safe navigation for mobile robots demands policies that remain reliable under the high-consequence perception uncertainty of cluttered environments. Yet most existing safe reinforcement learning (RL) methods assess safety through average cumulative cost. Such metrics can mask dangerous tail-risk behaviors. To address this, we propose a framework that trains risk-sensitive policies through Conditional Value-at-Risk (CVaR) constrained optimization on an off-policy TD3 backbone and evaluates their safety margins post-training through neural network reachability verification. During training, the policy is optimized under CVaR constraints on cumulative costs, promoting sensitivity to high-cost tail outcomes rather than average behavior alone. After training, we compute action reachable sets under bounded observation uncertainty using Taylor Model analysis, yielding a safety rate metric that quantifies the proportion of evaluated states at which the policy's reachable action set remains within prescribed safety margins. A key finding is that policies trained with CVaR constraints maintain larger safety margins from obstacles across evaluated states. This makes them significantly more amenable to formal reachability verification. Experiments across ten navigation scenarios and six baselines show that our method achieves a 98.3\% success rate, the highest safety verification rate among all compared methods, while revealing that average cost rankings and reachability-based safety rankings can diverge. This indicates that reachability verification captures risks which are missed by empirical cost metrics alone. We further validate our approach on a physical Clearpath Jackal robot, demonstrating successful sim-to-real transfer.
Grounded Continuation: A Linear-Time Runtime Verifier for LLM Conversations
May 13, 2026In long conversations, an LLM can produce a next utterance that sounds plausible but rests on premises the conversation has already abandoned. Context-manipulation attacks against deployed agents now actively exploit this gap. We close it with a runtime verifier that maintains an explicit dependency graph: an LLM classifies each turn into one of 8 update operations drawn from four formalisms (dynamic epistemic logic, abductive reasoning, awareness logic, argumentation), and a symbolic engine records which claims depend on which evidence. Checking whether a continuation is supported reduces to a graph walk; retraction propagates through the same graph to flag exactly the conclusions that lose support, with linear per-turn cost and a formal conflict-free guarantee. On LongMemEval-KU oracle (n=78), the verifier reaches 89.7% accuracy vs. 88.5% for the LLM-only baseline (+1.3pp) and 87.2% for a transcript-RAG baseline matched on retrieval budget (+2.6pp); wins among disagreements are correct abstentions where the baseline confabulates. On LoCoMo's 60 official QA items the verifier is competitive with retrieval-augmented baselines. Beyond external benchmarks, we construct two multi-agent scenarios and a 50-item grounding test: on the 15-item stale-premise subset, the verifier reaches 100% accuracy vs. 93.3% (+6.7pp). These instantiate a soundness-faithfulness decomposition: the structural check is sound by construction, and per-deployment LLM extraction faithfulness is the empirical question we measure across four LLM families. The retraction check plateaus at microseconds while history-replay grows linearly with conversation length.
A Data Efficiency Study of Synthetic Fog for Object Detection Using the Clear2Fog Pipeline
May 12, 2026Object detection in adverse weather is critical for the safety of autonomous vehicles; however, the scarcity of labelled, real-world foggy data remains a significant bottleneck. In this paper, we propose Clear2Fog (C2F), an end-to-end, physics-based pipeline that simulates fog on clear-weather datasets while ensuring sensor-level consistency across camera and LiDAR. By using monocular depth estimation and a novel atmospheric light estimation method, C2F overcomes structural artifacts and chromatic biases common in existing techniques. A human perceptual study confirms C2F's physical realism, with the generated images being preferred 92.95% of the time over an established method. Utilising a training set of 270,000 images from the Waymo Open Dataset, we conduct an extensive data efficiency study to investigate how environmental diversity influences model robustness. Our findings reveal that models trained on mixed-density fog datasets at 75% scale outperform those trained on fixed-density datasets at 100% scale. Furthermore, we investigate the sim-to-real transfer by fine-tuning pre-trained models on real-world foggy data. We demonstrate that a tenfold increase over the default fine-tuning learning rate successfully overcomes negative transfer from synthetic biases, resulting in a 1.67 mAP improvement over real-only baselines. The C2F pipeline provides a scalable framework for enhancing the reliability of autonomous systems in adverse weather and demonstrates the potential of diverse synthetic datasets for efficient model training.
PrefixGuard: From LLM-Agent Traces to Online Failure-Warning Monitors
May 07, 2026Large language model (LLM) agents now execute long, tool-using tasks where final outcome checks can arrive too late for intervention. Online warning requires lightweight prefix monitors over heterogeneous traces, but hand-authored event schemas are brittle and deployment-time LLM judging is costly. We introduce PrefixGuard, a trace-to-monitor framework with an offline StepView induction step followed by supervised monitor training. StepView induces deterministic typed-step adapters from raw trace samples, and the monitor learns an event abstraction and prefix-risk scorer from terminal outcomes. Across WebArena, $τ^2$-Bench, SkillsBench, and TerminalBench, the strongest PrefixGuard monitors reach 0.900/0.710/0.533/0.557 AUPRC. Using the strongest backend within each representation, they improve over raw-text controls by an average of +0.137 AUPRC. LLM judges remain substantially weaker under the same prefix-warning protocol. We also derive an observability ceiling on score-based area under the precision-recall curve (AUPRC) that separates monitor error from failures lacking evidence in the observed prefix. For finite-state audit, post-hoc deterministic finite automaton (DFA) extraction remains compact on WebArena and $τ^2$-Bench (29 and 20 states) but expands to 151 and 187 states on SkillsBench and TerminalBench. Finally, first-alert diagnostics show that strong ranking does not imply deployment utility: WebArena ranks well yet fails to support low-false-alarm alerts, whereas $τ^2$-Bench and TerminalBench retain more actionable early alerts. Together, these results position PrefixGuard as a practical monitor-synthesis recipe with explicit diagnostics for when prefix warnings translate into actionable interventions.
S2O: Enhancing Adversarial Training with Second-Order Statistics of Weights
Mar 01, 2026Adversarial training has emerged as a highly effective way to improve the robustness of deep neural networks (DNNs). It is typically conceptualized as a min-max optimization problem over model weights and adversarial perturbations, where the weights are optimized using gradient descent methods, such as SGD. In this paper, we propose a novel approach by treating model weights as random variables, which paves the way for enhancing adversarial training through \textbf{S}econd-Order \textbf{S}tatistics \textbf{O}ptimization (S$^2$O) over model weights. We challenge and relax a prevalent, yet often unrealistic, assumption in prior PAC-Bayesian frameworks: the statistical independence of weights. From this relaxation, we derive an improved PAC-Bayesian robust generalization bound. Our theoretical developments suggest that optimizing the second-order statistics of weights can substantially tighten this bound. We complement this theoretical insight by conducting an extensive set of experiments that demonstrate that S$^2$O not only enhances the robustness and generalization of neural networks when used in isolation, but also seamlessly augments other state-of-the-art adversarial training techniques. The code is available at https://github.com/Alexkael/S2O.
DDSA: Dual-Domain Strategic Attack for Spatial-Temporal Efficiency in Adversarial Robustness Testing
Jan 18, 2026Image transmission and processing systems in resource-critical applications face significant challenges from adversarial perturbations that compromise mission-specific object classification. Current robustness testing methods require excessive computational resources through exhaustive frame-by-frame processing and full-image perturbations, proving impractical for large-scale deployments where massive image streams demand immediate processing. This paper presents DDSA (Dual-Domain Strategic Attack), a resource-efficient adversarial robustness testing framework that optimizes testing through temporal selectivity and spatial precision. We introduce a scenario-aware trigger function that identifies critical frames requiring robustness evaluation based on class priority and model uncertainty, and employ explainable AI techniques to locate influential pixel regions for targeted perturbation. Our dual-domain approach achieves substantial temporal-spatial resource conservation while maintaining attack effectiveness. The framework enables practical deployment of comprehensive adversarial robustness testing in resource-constrained real-time applications where computational efficiency directly impacts mission success.
Towards A Unified PAC-Bayesian Framework for Norm-based Generalization Bounds
Jan 13, 2026Understanding the generalization behavior of deep neural networks remains a fundamental challenge in modern statistical learning theory. Among existing approaches, PAC-Bayesian norm-based bounds have demonstrated particular promise due to their data-dependent nature and their ability to capture algorithmic and geometric properties of learned models. However, most existing results rely on isotropic Gaussian posteriors, heavy use of spectral-norm concentration for weight perturbations, and largely architecture-agnostic analyses, which together limit both the tightness and practical relevance of the resulting bounds. To address these limitations, in this work, we propose a unified framework for PAC-Bayesian norm-based generalization by reformulating the derivation of generalization bounds as a stochastic optimization problem over anisotropic Gaussian posteriors. The key to our approach is a sensitivity matrix that quantifies the network outputs with respect to structured weight perturbations, enabling the explicit incorporation of heterogeneous parameter sensitivities and architectural structures. By imposing different structural assumptions on this sensitivity matrix, we derive a family of generalization bounds that recover several existing PAC-Bayesian results as special cases, while yielding bounds that are comparable to or tighter than state-of-the-art approaches. Such a unified framework provides a principled and flexible way for geometry-/structure-aware and interpretable generalization analysis in deep learning.
Lying with Truths: Open-Channel Multi-Agent Collusion for Belief Manipulation via Generative Montage
Jan 04, 2026As large language models (LLMs) transition to autonomous agents synthesizing real-time information, their reasoning capabilities introduce an unexpected attack surface. This paper introduces a novel threat where colluding agents steer victim beliefs using only truthful evidence fragments distributed through public channels, without relying on covert communications, backdoors, or falsified documents. By exploiting LLMs' overthinking tendency, we formalize the first cognitive collusion attack and propose Generative Montage: a Writer-Editor-Director framework that constructs deceptive narratives through adversarial debate and coordinated posting of evidence fragments, causing victims to internalize and propagate fabricated conclusions. To study this risk, we develop CoPHEME, a dataset derived from real-world rumor events, and simulate attacks across diverse LLM families. Our results show pervasive vulnerability across 14 LLM families: attack success rates reach 74.4% for proprietary models and 70.6% for open-weights models. Counterintuitively, stronger reasoning capabilities increase susceptibility, with reasoning-specialized models showing higher attack success than base models or prompts. Furthermore, these false beliefs then cascade to downstream judges, achieving over 60% deception rates, highlighting a socio-technical vulnerability in how LLM-based agents interact with dynamic information environments. Our implementation and data are available at: https://github.com/CharlesJW222/Lying_with_Truth/tree/main.
Rethinking Multi-Agent Intelligence Through the Lens of Small-World Networks
Dec 19, 2025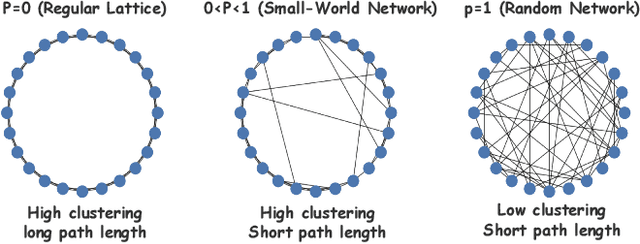
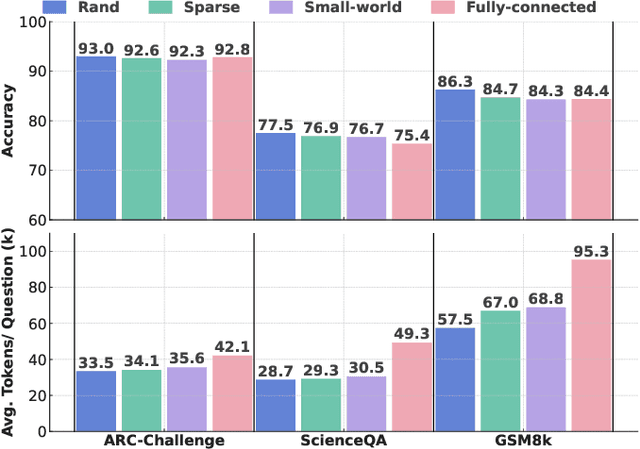
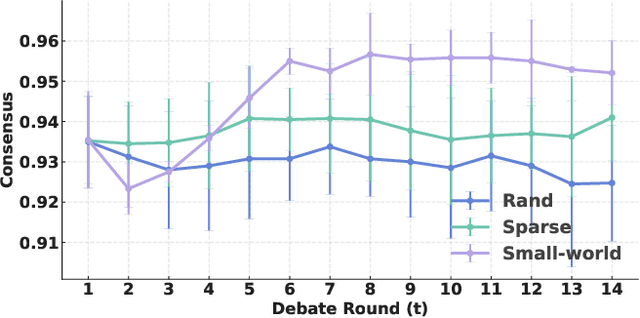
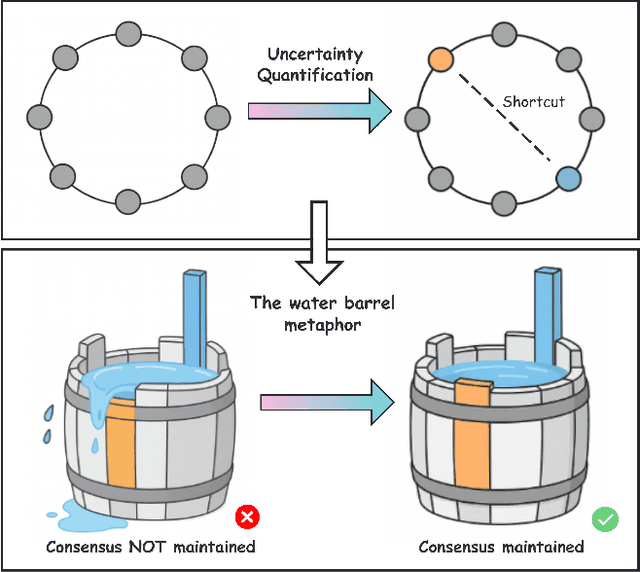
Large language models (LLMs) have enabled multi-agent systems (MAS) in which multiple agents argue, critique, and coordinate to solve complex tasks, making communication topology a first-class design choice. Yet most existing LLM-based MAS either adopt fully connected graphs, simple sparse rings, or ad-hoc dynamic selection, with little structural guidance. In this work, we revisit classic theory on small-world (SW) networks and ask: what changes if we treat SW connectivity as a design prior for MAS? We first bridge insights from neuroscience and complex networks to MAS, highlighting how SW structures balance local clustering and long-range integration. Using multi-agent debate (MAD) as a controlled testbed, experiment results show that SW connectivity yields nearly the same accuracy and token cost, while substantially stabilizing consensus trajectories. Building on this, we introduce an uncertainty-guided rewiring scheme for scaling MAS, where long-range shortcuts are added between epistemically divergent agents using LLM-oriented uncertainty signals (e.g., semantic entropy). This yields controllable SW structures that adapt to task difficulty and agent heterogeneity. Finally, we discuss broader implications of SW priors for MAS design, framing them as stabilizers of reasoning, enhancers of robustness, scalable coordinators, and inductive biases for emergent cognitive roles.