 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Nash Equilibrium Seeking Algorithm in Aggregative Games for Heterogeneous Multi-Robot Systems
Sep 19, 2025This paper develops a distributed Nash Equilibrium seeking algorithm for heterogeneous multi-robot systems. The algorithm utilises distributed optimisation and output control to achieve the Nash equilibrium by leveraging information shared among neighbouring robots. Specifically, we propose a distributed optimisation algorithm that calculates the Nash equilibrium as a tailored reference for each robot and designs output control laws for heterogeneous multi-robot systems to track it in an aggregative game. We prove that our algorithm is guaranteed to converge and result in efficient outcomes. The effectiveness of our approach is demonstrated through numerical simulations and empirical testing with physical robots.
Diverse Priors for Deep Reinforcement Learning
Oct 23, 2023



In Reinforcement Learning (RL), agents aim at maximizing cumulative rewards in a given environment. During the learning process, RL agents face the dilemma of exploitation and exploration: leveraging existing knowledge to acquire rewards or seeking potentially higher ones. Using uncertainty as a guiding principle provides an active and effective approach to solving this dilemma and ensemble-based methods are one of the prominent avenues for quantifying uncertainty. Nevertheless, conventional ensemble-based uncertainty estimation lacks an explicit prior, deviating from Bayesian principles. Besides, this method requires diversity among members to generate less biased uncertainty estimation results. To address the above problems, previous research has incorporated random functions as priors. Building upon these foundational efforts, our work introduces an innovative approach with delicately designed prior NNs, which can incorporate maximal diversity in the initial value functions of RL. Our method has demonstrated superior performance compared with the random prior approaches in solving classic control problems and general exploration tasks, significantly improving sample efficiency.
Detailed 3D Human Body Reconstruction from Multi-view Images Combining Voxel Super-Resolution and Learned Implicit Representation
Dec 11, 2020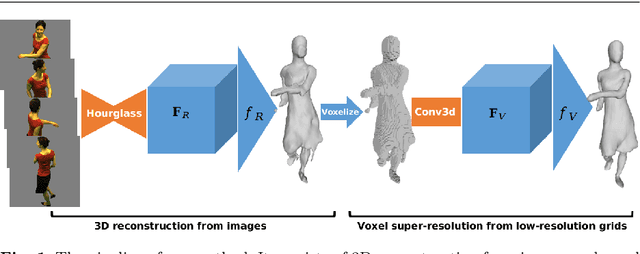



The task of reconstructing detailed 3D human body models from images is interesting but challenging in computer vision due to the high freedom of human bodies. In order to tackle the problem, we propose a coarse-to-fine method to reconstruct a detailed 3D human body from multi-view images combining voxel super-resolution based on learning the implicit representation. Firstly, the coarse 3D models are estimated by learning an implicit representation based on multi-scale features which are extracted by multi-stage hourglass networks from the multi-view images. Then, taking the low resolution voxel grids which are generated by the coarse 3D models as input, the voxel super-resolution based on an implicit representation is learned through a multi-stage 3D convolutional neural network. Finally, the refined detailed 3D human body models can be produced by the voxel super-resolution which can preserve the details and reduce the false reconstruction of the coarse 3D models. Benefiting from the implicit representation, the training process in our method is memory efficient and the detailed 3D human body produced by our method from multi-view images is the continuous decision boundary with high-resolution geometry. In addition, the coarse-to-fine method based on voxel super-resolution can remove false reconstructions and preserve the appearance details in the final reconstruction, simultaneously. In the experiments, our method quantitatively and qualitatively achieves the competitive 3D human body reconstructions from images with various poses and shapes on both the real and synthetic datasets.
A novel joint points and silhouette-based method to estimate 3D human pose and shape
Dec 11, 2020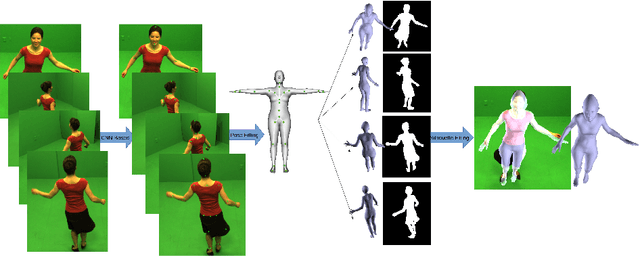
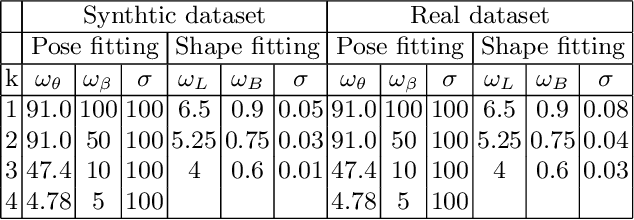
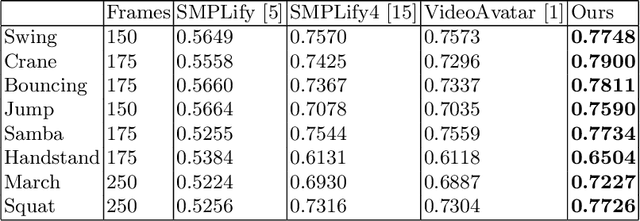
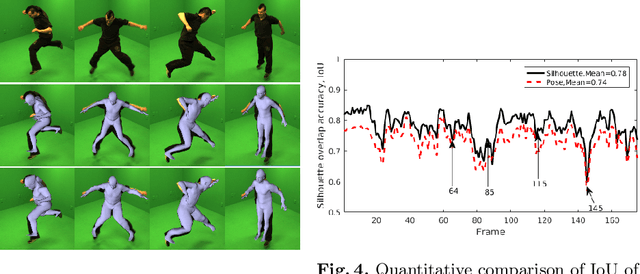
This paper presents a novel method for 3D human pose and shape estimation from images with sparse views, using joint points and silhouettes, based on a parametric model. Firstly, the parametric model is fitted to the joint points estimated by deep learning-based human pose estimation. Then, we extract the correspondence between the parametric model of pose fitting and silhouettes on 2D and 3D space. A novel energy function based on the correspondence is built and minimized to fit parametric model to the silhouettes. Our approach uses sufficient shape information because the energy function of silhouettes is built from both 2D and 3D space. This also means that our method only needs images from sparse views, which balances data used and the required prior information. Results on synthetic data and real data demonstrate the competitive performance of our approach on pose and shape estimation of the human body.
Modeling Cross-view Interaction Consistency for Paired Egocentric Interaction Recognition
Mar 24, 2020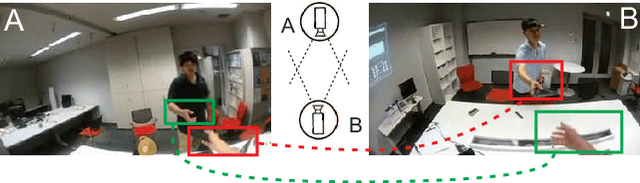
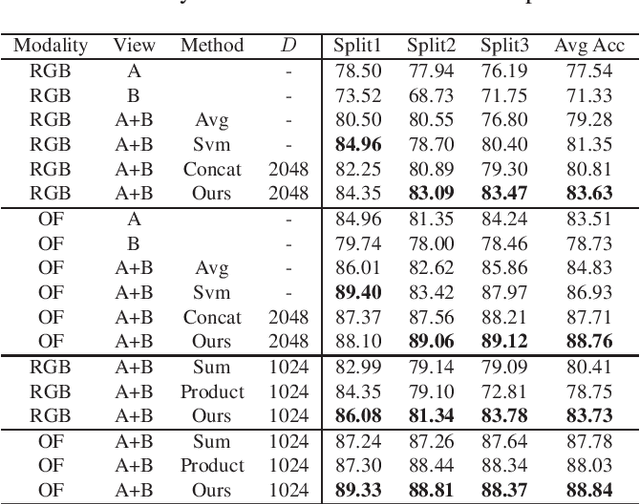
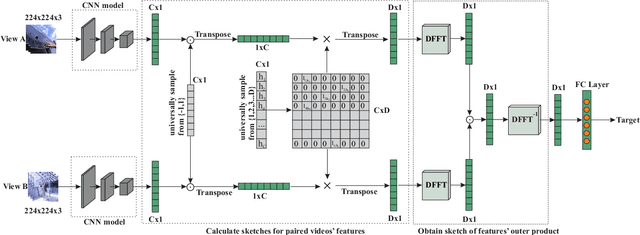
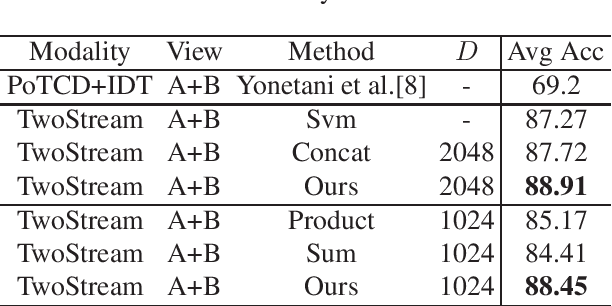
With the development of Augmented Reality (AR), egocentric action recognition (EAR) plays important role in accurately understanding demands from the user. However, EAR is designed to help recognize human-machine interaction in single egocentric view, thus difficult to capture interactions between two face-to-face AR users. Paired egocentric interaction recognition (PEIR) is the task to collaboratively recognize the interactions between two persons with the videos in their corresponding views. Unfortunately, existing PEIR methods always directly use linear decision function to fuse the features extracted from two corresponding egocentric videos, which ignore consistency of interaction in paired egocentric videos. The consistency of interactions in paired videos, and features extracted from them are correlated to each other. On top of that, we propose to build the relevance between two views using biliear pooling, which capture the consistency of two views in feature-level. Specifically, each neuron in the feature maps from one view connects to the neurons from another view, which guarantee the compact consistency between two views. Then all possible paired neurons are used for PEIR for the inside consistent information of them. To be efficient, we use compact bilinear pooling with Count Sketch to avoid directly computing outer product in bilinear. Experimental results on dataset PEV shows the superiority of the proposed methods on the task PEIR.
SPARK: Spatial-aware Online Incremental Attack Against Visual Tracking
Nov 26, 2019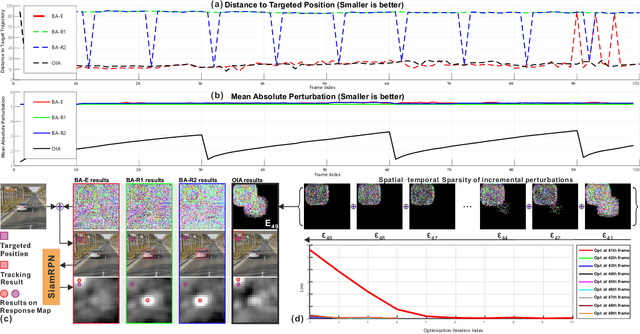

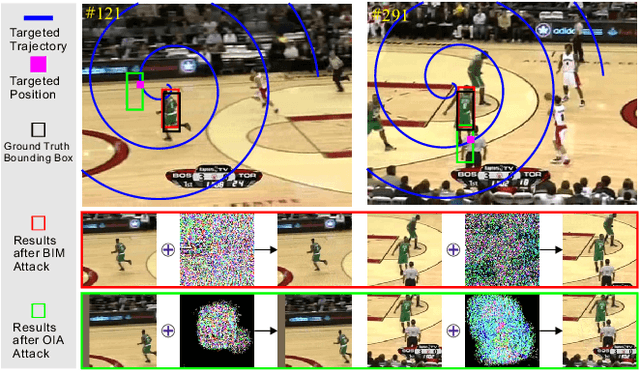

Adversarial attacks of deep neural networks have been intensively studied on image, audio, natural language, patch, and pixel classification tasks. Nevertheless, as a typical while important real-world application, the adversarial attacks of online video object tracking that traces an object's moving trajectory instead of its category are rarely explored. In this paper, we identify a new task for the adversarial attack to visual tracking: online generating imperceptible perturbations that mislead trackers along an incorrect~(Untargeted Attack, UA) or specified trajectory~(Targeted Attack, TA). To this end, we first propose a \textit{spatial-aware} basic attack by adapting existing attack methods, i.e., FGSM, BIM, and C\&W, and comprehensively analyze the attacking performance. We identify that online object tracking poses two new challenges: 1) it is difficult to generate imperceptible perturbations that can transfer across frames, and 2) real-time trackers require the attack to satisfy a certain level of efficiency. To address these challenges, we further propose the \textit{SPatial-Aware online incRemental attacK~(SPARK)} that performs spatial-temporal sparse incremental perturbations online and makes the adversarial attack less perceptible. In addition, as an optimization-based method, SPARK quickly converges to very small losses within several iterations by considering historical incremental perturbations, making it much more efficient than the basic attacks. The in-depth evaluation on state-of-the-art trackers (i.e., SiamRPN with Alex, MobileNetv2, and ResNet-50) on OTB100, VOT2018, UAV123, and LaSOT demonstrates the effectiveness and transferability of SPARK in misleading the trackers under both UA and TA with minor perturbations.