 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Share: Selective Memory for Efficient Parallel Agentic Systems
Feb 05, 2026Agentic systems solve complex tasks by coordinating multiple agents that iteratively reason, invoke tools, and exchange intermediate results. To improve robustness and solution quality, recent approaches deploy multiple agent teams running in parallel to explore diverse reasoning trajectories. However, parallel execution comes at a significant computational cost: when different teams independently reason about similar sub-problems or execute analogous steps, they repeatedly perform substantial overlapping computation. To address these limitations, in this paper, we propose Learning to Share (LTS), a learned shared-memory mechanism for parallel agentic frameworks that enables selective cross-team information reuse while controlling context growth. LTS introduces a global memory bank accessible to all teams and a lightweight controller that decides whether intermediate agent steps should be added to memory or not. The controller is trained using stepwise reinforcement learning with usage-aware credit assignment, allowing it to identify information that is globally useful across parallel executions. Experiments on the AssistantBench and GAIA benchmarks show that LTS significantly reduces overall runtime while matching or improving task performance compared to memory-free parallel baselines, demonstrating that learned memory admission is an effective strategy for improving the efficiency of parallel agentic systems. Project page: https://joefioresi718.github.io/LTS_webpage/
GenMRP: A Generative Multi-Route Planning Framework for Efficient and Personalized Real-Time Industrial Navigation
Feb 04, 2026Existing industrial-scale navigation applications contend with massive road networks, typically employing two main categories of approaches for route planning. The first relies on precomputed road costs for optimal routing and heuristic algorithms for generating alternatives, while the second, generative methods, has recently gained significant attention. However, the former struggles with personalization and route diversity, while the latter fails to meet the efficiency requirements of large-scale real-time scenarios. To address these limitations, we propose GenMRP, a generative framework for multi-route planning. To ensure generation efficiency, GenMRP first introduces a skeleton-to-capillary approach that dynamically constructs a relevant sub-network significantly smaller than the full road network. Within this sub-network, routes are generated iteratively. The first iteration identifies the optimal route, while the subsequent ones generate alternatives that balance quality and diversity using the newly proposed correctional boosting approach. Each iteration incorporates road features, user historical sequences, and previously generated routes into a Link Cost Model to update road costs, followed by route generation using the Dijkstra algorithm. Extensive experiments show that GenMRP achieves state-of-the-art performance with high efficiency in both offline and online environments. To facilitate further research, we have publicly released the training and evaluation dataset. GenMRP has been fully deployed in a real-world navigation app, demonstrating its effectiveness and benefits.
RE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
Dynamic Mix Precision Routing for Efficient Multi-step LLM Interaction
Feb 02, 2026Large language models (LLM) achieve strong performance in long-horizon decision-making tasks through multi-step interaction and reasoning at test time. While practitioners commonly believe a higher task success rate necessitates the use of a larger and stronger LLM model, multi-step interaction with a large LLM incurs prohibitive inference cost. To address this problem, we explore the use of low-precision quantized LLM in the long-horizon decision-making process. Based on the observation of diverse sensitivities among interaction steps, we propose a dynamic mix-precision routing framework that adaptively selects between high-precision and low-precision LLMs at each decision step. The router is trained via a two-stage pipeline, consisting of KL-divergence-based supervised learning that identifies precision-sensitive steps, followed by Group-Relative Policy Optimization (GRPO) to further improve task success rates. Experiments on ALFWorld demonstrate that our approach achieves a great improvement on accuracy-cost trade-off over single-precision baselines and heuristic routing methods.
VisionTrim: Unified Vision Token Compression for Training-Free MLLM Acceleration
Jan 30, 2026Multimodal large language models (MLLMs) suffer from high computational costs due to excessive visual tokens, particularly in high-resolution and video-based scenarios. Existing token reduction methods typically focus on isolated pipeline components and often neglect textual alignment, leading to performance degradation. In this paper, we propose VisionTrim, a unified framework for training-free MLLM acceleration, integrating two effective plug-and-play modules: 1) the Dominant Vision Token Selection (DVTS) module, which preserves essential visual tokens via a global-local view, and 2) the Text-Guided Vision Complement (TGVC) module, which facilitates context-aware token merging guided by textual cues. Extensive experiments across diverse image and video multimodal benchmarks demonstrate the performance superiority of our VisionTrim, advancing practical MLLM deployment in real-world applications. The code is available at: https://github.com/hanxunyu/VisionTrim.
Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems
Dec 30, 2025The rapid advancement of autonomous systems, including self-driving vehicles and drones, has intensified the need to forge true Spatial Intelligence from multi-modal onboard sensor data. While foundation models excel in single-modal contexts, integrating their capabilities across diverse sensors like cameras and LiDAR to create a unified understanding remains a formidable challenge. This paper presents a comprehensive framework for multi-modal pre-training, identifying the core set of techniques driving progress toward this goal. We dissect the interplay between foundational sensor characteristics and learning strategies, evaluating the role of platform-specific datasets in enabling these advancements. Our central contribution is the formulation of a unified taxonomy for pre-training paradigms: ranging from single-modality baselines to sophisticated unified frameworks that learn holistic representations for advanced tasks like 3D object detection and semantic occupancy prediction. Furthermore, we investigate the integration of textual inputs and occupancy representations to facilitate open-world perception and planning. Finally, we identify critical bottlenecks, such as computational efficiency and model scalability, and propose a roadmap toward general-purpose multi-modal foundation models capable of achieving robust Spatial Intelligence for real-world deployment.
Vision-Language-Action Models for Autonomous Driving: Past, Present, and Future
Dec 18, 2025Autonomous driving has long relied on modular "Perception-Decision-Action" pipelines, where hand-crafted interfaces and rule-based components often break down in complex or long-tailed scenarios. Their cascaded design further propagates perception errors, degrading downstream planning and control. Vision-Action (VA) models address some limitations by learning direct mappings from visual inputs to actions, but they remain opaque, sensitive to distribution shifts, and lack structured reasoning or instruction-following capabilities. Recent progress in Large Language Models (LLMs) and multimodal learning has motivated the emergence of Vision-Language-Action (VLA) frameworks, which integrate perception with language-grounded decision making. By unifying visual understanding, linguistic reasoning, and actionable outputs, VLAs offer a pathway toward more interpretable, generalizable, and human-aligned driving policies. This work provides a structured characterization of the emerging VLA landscape for autonomous driving. We trace the evolution from early VA approaches to modern VLA frameworks and organize existing methods into two principal paradigms: End-to-End VLA, which integrates perception, reasoning, and planning within a single model, and Dual-System VLA, which separates slow deliberation (via VLMs) from fast, safety-critical execution (via planners). Within these paradigms, we further distinguish subclasses such as textual vs. numerical action generators and explicit vs. implicit guidance mechanisms. We also summarize representative datasets and benchmarks for evaluating VLA-based driving systems and highlight key challenges and open directions, including robustness, interpretability, and instruction fidelity. Overall, this work aims to establish a coherent foundation for advancing human-compatible autonomous driving systems.
GUIDE: Gaussian Unified Instance Detection for Enhanced Obstacle Perception in Autonomous Driving
Nov 17, 2025In the realm of autonomous driving, accurately detecting surrounding obstacles is crucial for effective decision-making. Traditional methods primarily rely on 3D bounding boxes to represent these obstacles, which often fail to capture the complexity of irregularly shaped, real-world objects. To overcome these limitations, we present GUIDE, a novel framework that utilizes 3D Gaussians for instance detection and occupancy prediction. Unlike conventional occupancy prediction methods, GUIDE also offers robust tracking capabilities. Our framework employs a sparse representation strategy, using Gaussian-to-Voxel Splatting to provide fine-grained, instance-level occupancy data without the computational demands associated with dense voxel grids. Experimental validation on the nuScenes dataset demonstrates GUIDE's performance, with an instance occupancy mAP of 21.61, marking a 50\% improvement over existing methods, alongside competitive tracking capabilities. GUIDE establishes a new benchmark in autonomous perception systems, effectively combining precision with computational efficiency to better address the complexities of real-world driving environments.
An Empirical Study of Reasoning Steps in Thinking Code LLMs
Nov 08, 2025Thinking Large Language Models (LLMs) generate explicit intermediate reasoning traces before final answers, potentially improving transparency, interpretability, and solution accuracy for code generation. However, the quality of these reasoning chains remains underexplored. We present a comprehensive empirical study examining the reasoning process and quality of thinking LLMs for code generation. We evaluate six state-of-the-art reasoning LLMs (DeepSeek-R1, OpenAI-o3-mini, Claude-3.7-Sonnet-Thinking, Gemini-2.0-Flash-Thinking, Gemini-2.5-Flash, and Qwen-QwQ) across 100 code generation tasks of varying difficulty from BigCodeBench. We quantify reasoning-chain structure through step counts and verbosity, conduct controlled step-budget adjustments, and perform a 21-participant human evaluation across three dimensions: efficiency, logical correctness, and completeness. Our step-count interventions reveal that targeted step increases can improve resolution rates for certain models/tasks, while modest reductions often preserve success on standard tasks, rarely on hard ones. Through systematic analysis, we develop a reasoning-problematic taxonomy, identifying completeness as the dominant failure mode. Task complexity significantly impacts reasoning quality; hard problems are substantially more prone to incompleteness than standard tasks. Our stability analysis demonstrates that thinking LLMs maintain consistent logical structures across computational effort levels and can self-correct previous errors. This study provides new insights into the strengths and limitations of current thinking LLMs in software engineering.
Beyond Redundancy: Diverse and Specialized Multi-Expert Sparse Autoencoder
Nov 07, 2025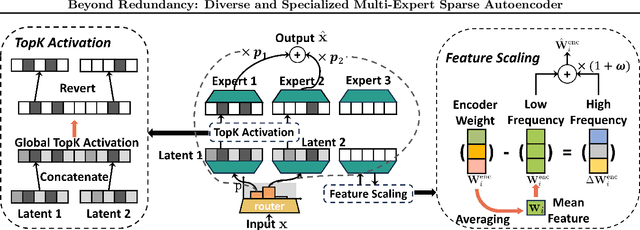
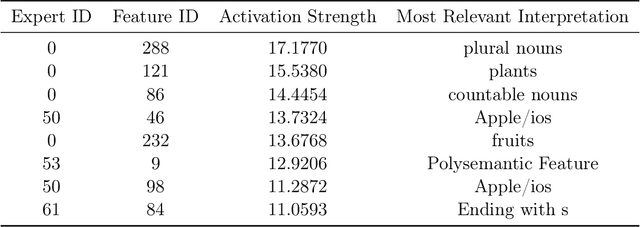
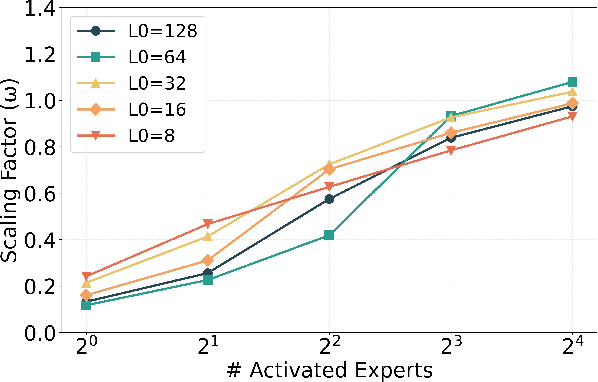
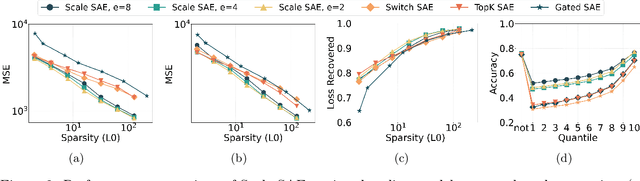
Sparse autoencoders (SAEs) have emerged as a powerful tool for interpreting large language models (LLMs) by decomposing token activations into combinations of human-understandable features. While SAEs provide crucial insights into LLM explanations, their practical adoption faces a fundamental challenge: better interpretability demands that SAEs' hidden layers have high dimensionality to satisfy sparsity constraints, resulting in prohibitive training and inference costs. Recent Mixture of Experts (MoE) approaches attempt to address this by partitioning SAEs into narrower expert networks with gated activation, thereby reducing computation. In a well-designed MoE, each expert should focus on learning a distinct set of features. However, we identify a \textit{critical limitation} in MoE-SAE: Experts often fail to specialize, which means they frequently learn overlapping or identical features. To deal with it, we propose two key innovations: (1) Multiple Expert Activation that simultaneously engages semantically weighted expert subsets to encourage specialization, and (2) Feature Scaling that enhances diversity through adaptive high-frequency scaling. Experiments demonstrate a 24\% lower reconstruction error and a 99\% reduction in feature redundancy compared to existing MoE-SAE methods. This work bridges the interpretability-efficiency gap in LLM analysis, allowing transparent model inspection without compromising computational feasibility.