 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
A Closer Look on Memorization in Tabular Diffusion Model: A Data-Centric Perspective
May 28, 2025Diffusion models have shown strong performance in generating high-quality tabular data, but they carry privacy risks by reproducing exact training samples. While prior work focuses on dataset-level augmentation to reduce memorization, little is known about which individual samples contribute most. We present the first data-centric study of memorization dynamics in tabular diffusion models. We quantify memorization for each real sample based on how many generated samples are flagged as replicas, using a relative distance ratio. Our empirical analysis reveals a heavy-tailed distribution of memorization counts: a small subset of samples contributes disproportionately to leakage, confirmed via sample-removal experiments. To understand this, we divide real samples into top- and non-top-memorized groups and analyze their training-time behaviors. We track when each sample is first memorized and monitor per-epoch memorization intensity (AUC). Memorized samples are memorized slightly earlier and show stronger signals in early training. Based on these insights, we propose DynamicCut, a two-stage, model-agnostic mitigation method: (a) rank samples by epoch-wise intensity, (b) prune a tunable top fraction, and (c) retrain on the filtered dataset. Across multiple tabular datasets and models, DynamicCut reduces memorization with minimal impact on data diversity and downstream performance. It also complements augmentation-based defenses. Furthermore, DynamicCut enables cross-model transferability: high-ranked samples identified from one model (e.g., a diffusion model) are also effective for reducing memorization when removed from others, such as GANs and VAEs.
SimAug: Enhancing Recommendation with Pretrained Language Models for Dense and Balanced Data Augmentation
May 03, 2025Deep Neural Networks (DNNs) are extensively used in collaborative filtering due to their impressive effectiveness. These systems depend on interaction data to learn user and item embeddings that are crucial for recommendations. However, the data often suffers from sparsity and imbalance issues: limited observations of user-item interactions can result in sub-optimal performance, and a predominance of interactions with popular items may introduce recommendation bias. To address these challenges, we employ Pretrained Language Models (PLMs) to enhance the interaction data with textual information, leading to a denser and more balanced dataset. Specifically, we propose a simple yet effective data augmentation method (SimAug) based on the textual similarity from PLMs, which can be seamlessly integrated to any systems as a lightweight, plug-and-play component in the pre-processing stage. Our experiments across nine datasets consistently demonstrate improvements in both utility and fairness when training with the augmented data generated by SimAug. The code is available at https://github.com/YuyingZhao/SimAug.
Towards Efficient Large Scale Spatial-Temporal Time Series Forecasting via Improved Inverted Transformers
Mar 13, 2025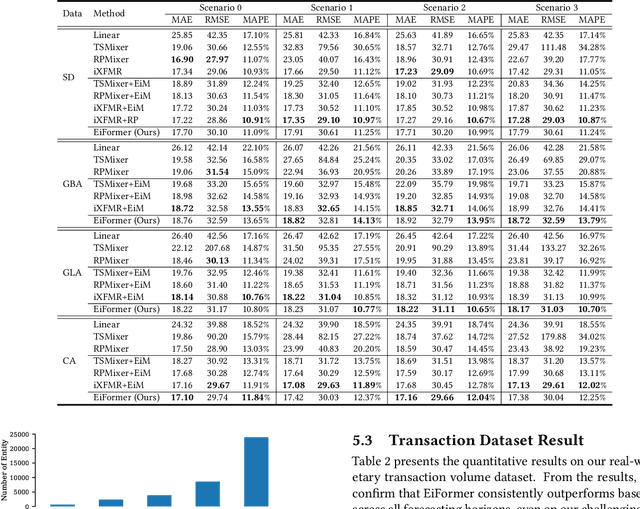
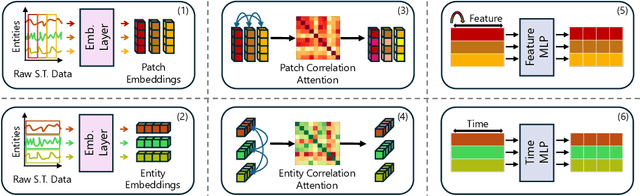
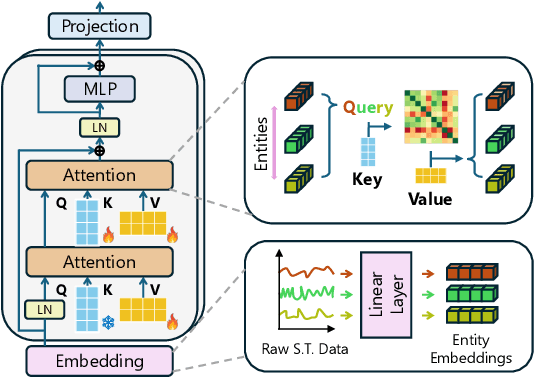
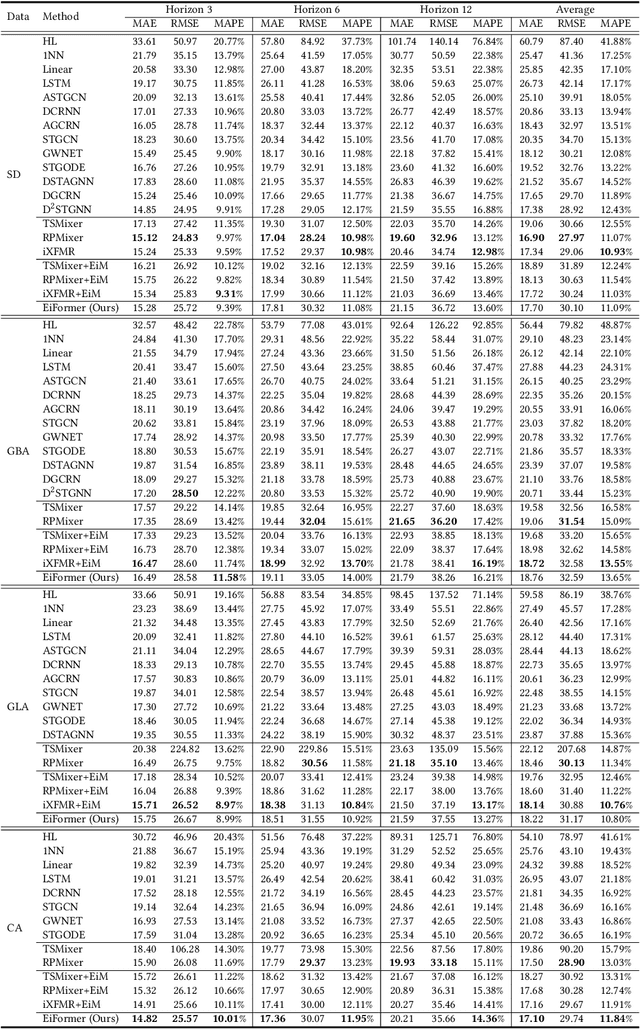
Time series forecasting at scale presents significant challenges for modern prediction systems, particularly when dealing with large sets of synchronized series, such as in a global payment network. In such systems, three key challenges must be overcome for accurate and scalable predictions: 1) emergence of new entities, 2) disappearance of existing entities, and 3) the large number of entities present in the data. The recently proposed Inverted Transformer (iTransformer) architecture has shown promising results by effectively handling variable entities. However, its practical application in large-scale settings is limited by quadratic time and space complexity ($O(N^2)$) with respect to the number of entities $N$. In this paper, we introduce EiFormer, an improved inverted transformer architecture that maintains the adaptive capabilities of iTransformer while reducing computational complexity to linear scale ($O(N)$). Our key innovation lies in restructuring the attention mechanism to eliminate redundant computations without sacrificing model expressiveness. Additionally, we incorporate a random projection mechanism that not only enhances efficiency but also improves prediction accuracy through better feature representation. Extensive experiments on the public LargeST benchmark dataset and a proprietary large-scale time series dataset demonstrate that EiFormer significantly outperforms existing methods in both computational efficiency and forecasting accuracy. Our approach enables practical deployment of transformer-based forecasting in industrial applications where handling time series at scale is essential.
A Compact Model for Large-Scale Time Series Forecasting
Feb 28, 2025



Spatio-temporal data, which commonly arise in real-world applications such as traffic monitoring, financial transactions, and ride-share demands, represent a special category of multivariate time series. They exhibit two distinct characteristics: high dimensionality and commensurability across spatial locations. These attributes call for computationally efficient modeling approaches and facilitate the use of univariate forecasting models in a channel-independent fashion. SparseTSF, a recently introduced competitive univariate forecasting model, harnesses periodicity to achieve compactness by concentrating on cross-period dynamics, thereby extending the Pareto frontier with respect to model size and predictive performance. Nonetheless, it underperforms on spatio-temporal data due to an inadequate capture of intra-period temporal dependencies. To address this shortcoming, we propose UltraSTF, which integrates a cross-period forecasting module with an ultra-compact shape bank component. Our model effectively detects recurring patterns in time series through the attention mechanism of the shape bank component, thereby strengthening its ability to learn intra-period dynamics. UltraSTF achieves state-of-the-art performance on the LargeST benchmark while employing fewer than 0.2% of the parameters required by the second-best approaches, thus further extending the Pareto frontier of existing methods.
Enhancing Distribution and Label Consistency for Graph Out-of-Distribution Generalization
Jan 07, 2025


To deal with distribution shifts in graph data, various graph out-of-distribution (OOD) generalization techniques have been recently proposed. These methods often employ a two-step strategy that first creates augmented environments and subsequently identifies invariant subgraphs to improve generalizability. Nevertheless, this approach could be suboptimal from the perspective of consistency. First, the process of augmenting environments by altering the graphs while preserving labels may lead to graphs that are not realistic or meaningfully related to the origin distribution, thus lacking distribution consistency. Second, the extracted subgraphs are obtained from directly modifying graphs, and may not necessarily maintain a consistent predictive relationship with their labels, thereby impacting label consistency. In response to these challenges, we introduce an innovative approach that aims to enhance these two types of consistency for graph OOD generalization. We propose a modifier to obtain both augmented and invariant graphs in a unified manner. With the augmented graphs, we enrich the training data without compromising the integrity of label-graph relationships. The label consistency enhancement in our framework further preserves the supervision information in the invariant graph. We conduct extensive experiments on real-world datasets to demonstrate the superiority of our framework over other state-of-the-art baselines.
THeGCN: Temporal Heterophilic Graph Convolutional Network
Dec 21, 2024Graph Neural Networks (GNNs) have exhibited remarkable efficacy in diverse graph learning tasks, particularly on static homophilic graphs. Recent attention has pivoted towards more intricate structures, encompassing (1) static heterophilic graphs encountering the edge heterophily issue in the spatial domain and (2) event-based continuous graphs in the temporal domain. State-of-the-art (SOTA) has been concurrently addressing these two lines of work but tends to overlook the presence of heterophily in the temporal domain, constituting the temporal heterophily issue. Furthermore, we highlight that the edge heterophily issue and the temporal heterophily issue often co-exist in event-based continuous graphs, giving rise to the temporal edge heterophily challenge. To tackle this challenge, this paper first introduces the temporal edge heterophily measurement. Subsequently, we propose the Temporal Heterophilic Graph Convolutional Network (THeGCN), an innovative model that incorporates the low/high-pass graph signal filtering technique to accurately capture both edge (spatial) heterophily and temporal heterophily. Specifically, the THeGCN model consists of two key components: a sampler and an aggregator. The sampler selects events relevant to a node at a given moment. Then, the aggregator executes message-passing, encoding temporal information, node attributes, and edge attributes into node embeddings. Extensive experiments conducted on 5 real-world datasets validate the efficacy of THeGCN.
Understanding and Mitigating Memorization in Diffusion Models for Tabular Data
Dec 15, 2024Tabular data generation has attracted significant research interest in recent years, with the tabular diffusion models greatly improving the quality of synthetic data. However, while memorization, where models inadvertently replicate exact or near-identical training data, has been thoroughly investigated in image and text generation, its effects on tabular data remain largely unexplored. In this paper, we conduct the first comprehensive investigation of memorization phenomena in diffusion models for tabular data. Our empirical analysis reveals that memorization appears in tabular diffusion models and increases with larger training epochs. We further examine the influence of factors such as dataset sizes, feature dimensions, and different diffusion models on memorization. Additionally, we provide a theoretical explanation for why memorization occurs in tabular diffusion models. To address this issue, we propose TabCutMix, a simple yet effective data augmentation technique that exchanges randomly selected feature segments between random same-class training sample pairs. Building upon this, we introduce TabCutMixPlus, an enhanced method that clusters features based on feature correlations and ensures that features within the same cluster are exchanged together during augmentation. This clustering mechanism mitigates out-of-distribution (OOD) generation issues by maintaining feature coherence. Experimental results across various datasets and diffusion models demonstrate that TabCutMix effectively mitigates memorization while maintaining high-quality data generation.
Matrix Profile for Anomaly Detection on Multidimensional Time Series
Sep 14, 2024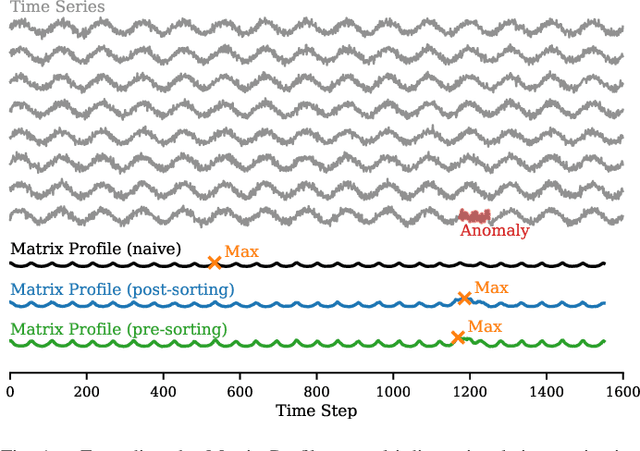
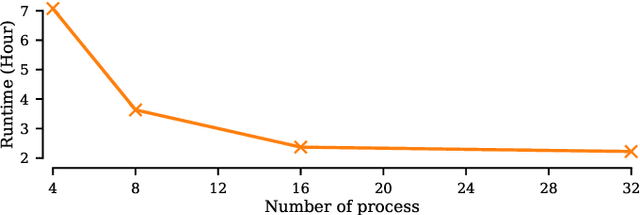
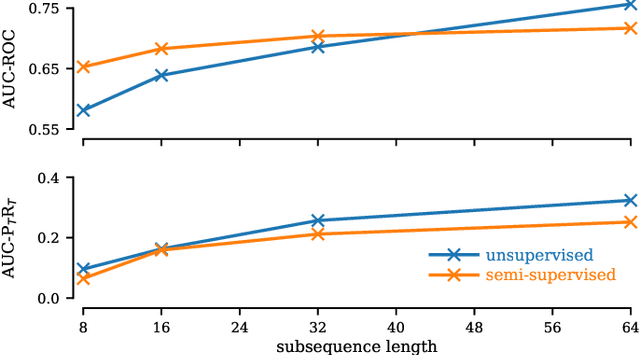
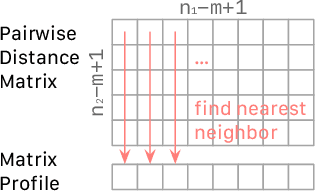
The Matrix Profile (MP), a versatile tool for time series data mining, has been shown effective in time series anomaly detection (TSAD). This paper delves into the problem of anomaly detection in multidimensional time series, a common occurrence in real-world applications. For instance, in a manufacturing factory, multiple sensors installed across the site collect time-varying data for analysis. The Matrix Profile, named for its role in profiling the matrix storing pairwise distance between subsequences of univariate time series, becomes complex in multidimensional scenarios. If the input univariate time series has n subsequences, the pairwise distance matrix is a n x n matrix. In a multidimensional time series with d dimensions, the pairwise distance information must be stored in a n x n x d tensor. In this paper, we first analyze different strategies for condensing this tensor into a profile vector. We then investigate the potential of extending the MP to efficiently find k-nearest neighbors for anomaly detection. Finally, we benchmark the multidimensional MP against 19 baseline methods on 119 multidimensional TSAD datasets. The experiments covers three learning setups: unsupervised, supervised, and semi-supervised. MP is the only method that consistently delivers high performance across all setups.
GAIM: Attacking Graph Neural Networks via Adversarial Influence Maximization
Aug 20, 2024Recent studies show that well-devised perturbations on graph structures or node features can mislead trained Graph Neural Network (GNN) models. However, these methods often overlook practical assumptions, over-rely on heuristics, or separate vital attack components. In response, we present GAIM, an integrated adversarial attack method conducted on a node feature basis while considering the strict black-box setting. Specifically, we define an adversarial influence function to theoretically assess the adversarial impact of node perturbations, thereby reframing the GNN attack problem into the adversarial influence maximization problem. In our approach, we unify the selection of the target node and the construction of feature perturbations into a single optimization problem, ensuring a unique and consistent feature perturbation for each target node. We leverage a surrogate model to transform this problem into a solvable linear programming task, streamlining the optimization process. Moreover, we extend our method to accommodate label-oriented attacks, broadening its applicability. Thorough evaluations on five benchmark datasets across three popular models underscore the effectiveness of our method in both untargeted and label-oriented targeted attacks. Through comprehensive analysis and ablation studies, we demonstrate the practical value and efficacy inherent to our design choices.