 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2Act: Simple Spiking Actor
Mar 16, 2026Spiking neural networks (SNNs) and biologically-inspired learning mechanisms are attractive in mobile robotics, where the size and performance of onboard neural network policies are constrained by power and computational budgets. Existing SNN approaches, such as population coding, reward modulation, and hybrid artificial neural network (ANN)-SNN architectures, have shown promising results; however, they face challenges in complex, highly stochastic environments due to SNN sensitivity to hyperparameters and inconsistent gradient signals. To address these challenges, we propose simple spiking actor (S2Act), a computationally lightweight framework that deploys an RL policy using an SNN in three steps: (1) architect an actor-critic model based on an approximated network of rate-based spiking neurons, (2) train the network with gradients using compatible activation functions, and (3) transfer the trained weights into physical parameters of rate-based leaky integrate-and-fire (LIF) neurons for inference and deployment. By globally shaping LIF neuron parameters such that their rate-based responses approximate ReLU activations, S2Act effectively mitigates the vanishing gradient problem, while pre-constraining LIF response curves reduces reliance on complex SNN-specific hyperparameter tuning. We demonstrate our method in two multi-agent stochastic environments (capture-the-flag and parking) that capture the complexity of multi-robot interactions, and deploy our trained policies on physical TurtleBot platforms using Intel's Loihi neuromorphic hardware. Our experimental results show that S2Act outperforms relevant baselines in task performance and real-time inference in nearly all considered scenarios, highlighting its potential for rapid prototyping and efficient real-world deployment of SNN-based RL policies.
Understanding LLM Evaluator Behavior: A Structured Multi-Evaluator Framework for Merchant Risk Assessment
Feb 04, 2026Large Language Models (LLMs) are increasingly used as evaluators of reasoning quality, yet their reliability and bias in payments-risk settings remain poorly understood. We introduce a structured multi-evaluator framework for assessing LLM reasoning in Merchant Category Code (MCC)-based merchant risk assessment, combining a five-criterion rubric with Monte-Carlo scoring to evaluate rationale quality and evaluator stability. Five frontier LLMs generate and cross-evaluate MCC risk rationales under attributed and anonymized conditions. To establish a judge-independent reference, we introduce a consensus-deviation metric that eliminates circularity by comparing each judge's score to the mean of all other judges, yielding a theoretically grounded measure of self-evaluation and cross-model deviation. Results reveal substantial heterogeneity: GPT-5.1 and Claude 4.5 Sonnet show negative self-evaluation bias (-0.33, -0.31), while Gemini-2.5 Pro and Grok 4 display positive bias (+0.77, +0.71), with bias attenuating by 25.8 percent under anonymization. Evaluation by 26 payment-industry experts shows LLM judges assign scores averaging +0.46 points above human consensus, and that the negative bias of GPT-5.1 and Claude 4.5 Sonnet reflects closer alignment with human judgment. Ground-truth validation using payment-network data shows four models exhibit statistically significant alignment (Spearman rho = 0.56 to 0.77), confirming that the framework captures genuine quality. Overall, the framework provides a replicable basis for evaluating LLM-as-a-judge systems in payment-risk workflows and highlights the need for bias-aware protocols in operational financial settings.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
TransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Towards Efficient Large Scale Spatial-Temporal Time Series Forecasting via Improved Inverted Transformers
Mar 13, 2025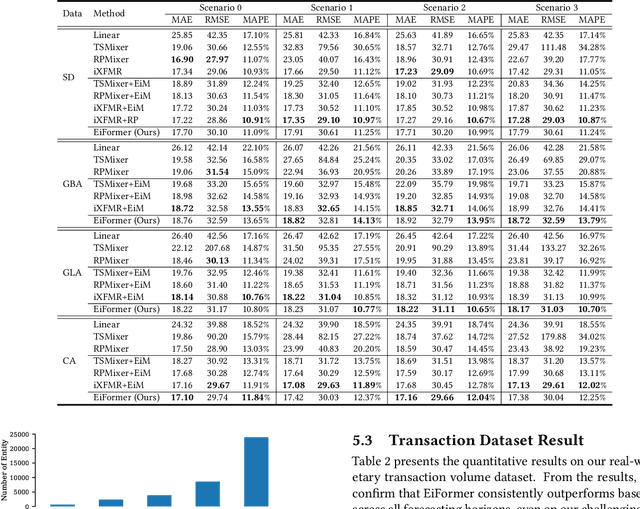
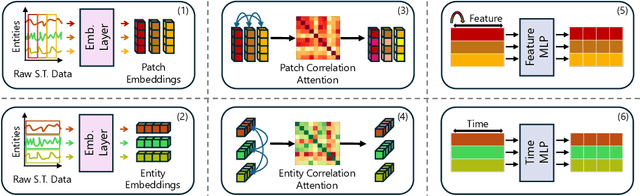
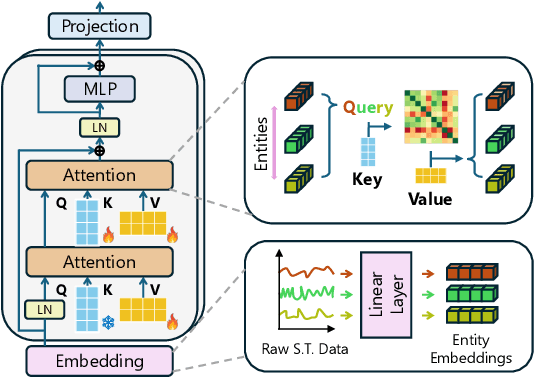
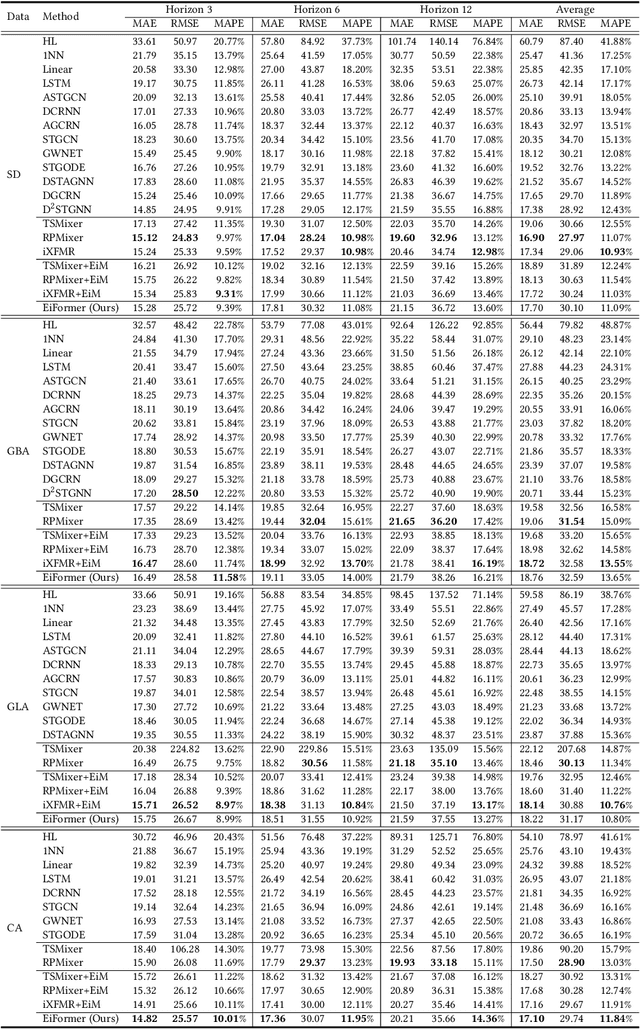
Time series forecasting at scale presents significant challenges for modern prediction systems, particularly when dealing with large sets of synchronized series, such as in a global payment network. In such systems, three key challenges must be overcome for accurate and scalable predictions: 1) emergence of new entities, 2) disappearance of existing entities, and 3) the large number of entities present in the data. The recently proposed Inverted Transformer (iTransformer) architecture has shown promising results by effectively handling variable entities. However, its practical application in large-scale settings is limited by quadratic time and space complexity ($O(N^2)$) with respect to the number of entities $N$. In this paper, we introduce EiFormer, an improved inverted transformer architecture that maintains the adaptive capabilities of iTransformer while reducing computational complexity to linear scale ($O(N)$). Our key innovation lies in restructuring the attention mechanism to eliminate redundant computations without sacrificing model expressiveness. Additionally, we incorporate a random projection mechanism that not only enhances efficiency but also improves prediction accuracy through better feature representation. Extensive experiments on the public LargeST benchmark dataset and a proprietary large-scale time series dataset demonstrate that EiFormer significantly outperforms existing methods in both computational efficiency and forecasting accuracy. Our approach enables practical deployment of transformer-based forecasting in industrial applications where handling time series at scale is essential.
MOOSS: Mask-Enhanced Temporal Contrastive Learning for Smooth State Evolution in Visual Reinforcement Learning
Sep 02, 2024



In visual Reinforcement Learning (RL), learning from pixel-based observations poses significant challenges on sample efficiency, primarily due to the complexity of extracting informative state representations from high-dimensional data. Previous methods such as contrastive-based approaches have made strides in improving sample efficiency but fall short in modeling the nuanced evolution of states. To address this, we introduce MOOSS, a novel framework that leverages a temporal contrastive objective with the help of graph-based spatial-temporal masking to explicitly model state evolution in visual RL. Specifically, we propose a self-supervised dual-component strategy that integrates (1) a graph construction of pixel-based observations for spatial-temporal masking, coupled with (2) a multi-level contrastive learning mechanism that enriches state representations by emphasizing temporal continuity and change of states. MOOSS advances the understanding of state dynamics by disrupting and learning from spatial-temporal correlations, which facilitates policy learning. Our comprehensive evaluation on multiple continuous and discrete control benchmarks shows that MOOSS outperforms previous state-of-the-art visual RL methods in terms of sample efficiency, demonstrating the effectiveness of our method. Our code is released at https://github.com/jsun57/MOOSS.
Revealing the Power of Spatial-Temporal Masked Autoencoders in Multivariate Time Series Forecasting
Sep 26, 2023Multivariate time series (MTS) forecasting involves predicting future time series data based on historical observations. Existing research primarily emphasizes the development of complex spatial-temporal models that capture spatial dependencies and temporal correlations among time series variables explicitly. However, recent advances have been impeded by challenges relating to data scarcity and model robustness. To address these issues, we propose Spatial-Temporal Masked Autoencoders (STMAE), an MTS forecasting framework that leverages masked autoencoders to enhance the performance of spatial-temporal baseline models. STMAE consists of two learning stages. In the pretraining stage, an encoder-decoder architecture is employed. The encoder processes the partially visible MTS data produced by a novel dual-masking strategy, including biased random walk-based spatial masking and patch-based temporal masking. Subsequently, the decoders aim to reconstruct the masked counterparts from both spatial and temporal perspectives. The pretraining stage establishes a challenging pretext task, compelling the encoder to learn robust spatial-temporal patterns. In the fine-tuning stage, the pretrained encoder is retained, and the original decoder from existing spatial-temporal models is appended for forecasting. Extensive experiments are conducted on multiple MTS benchmarks. The promising results demonstrate that integrating STMAE into various spatial-temporal models can largely enhance their MTS forecasting capability.
Towards Globally Consistent Stochastic Human Motion Prediction via Motion Diffusion
May 21, 2023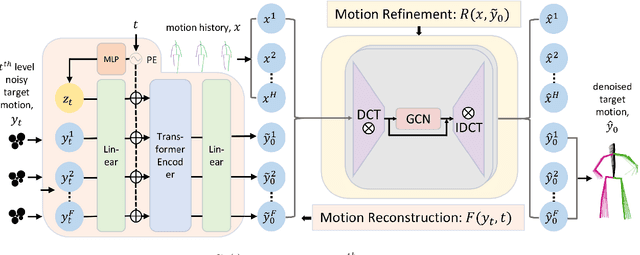
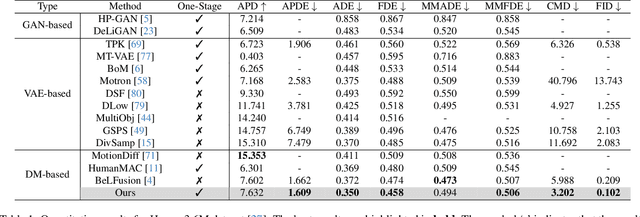
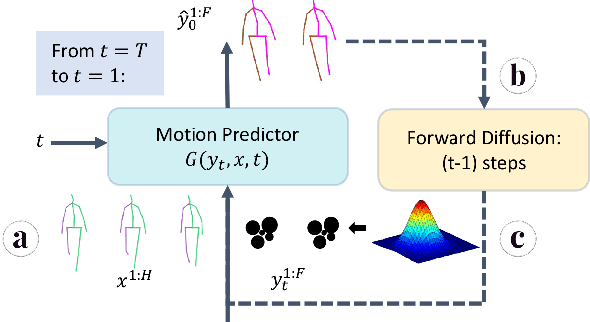

Stochastic human motion prediction aims to predict multiple possible upcoming pose sequences based on past human motion trajectories. Prior works focused heavily on generating diverse motion samples, leading to inconsistent, abnormal predictions from the immediate past observations. To address this issue, in this work, we propose DiffMotion, a diffusion-based stochastic human motion prediction framework that considers both the kinematic structure of the human body and the globally temporally consistent nature of motion. Specifically, DiffMotion consists of two modules: 1) a transformer-based network for generating an initial motion reconstruction from corrupted motion, and 2) a multi-stage graph convolutional network to iteratively refine the generated motion based on past observations. Facilitated by the proposed direct target prediction objective and the variance scheduler, our method is capable of predicting accurate, realistic and consistent motion with an appropriate level of diversity. Our results on benchmark datasets demonstrate that DiffMotion outperforms previous methods by large margins in terms of accuracy and fidelity while demonstrating superior robustness.
Towards Accurate Human Motion Prediction via Iterative Refinement
May 08, 2023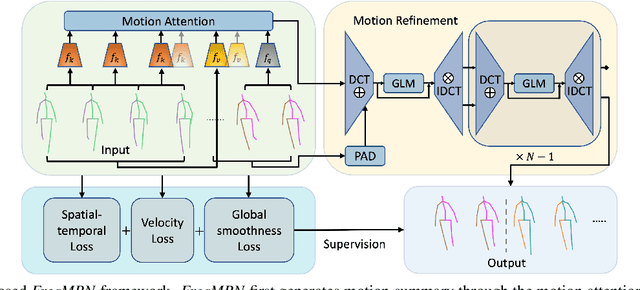
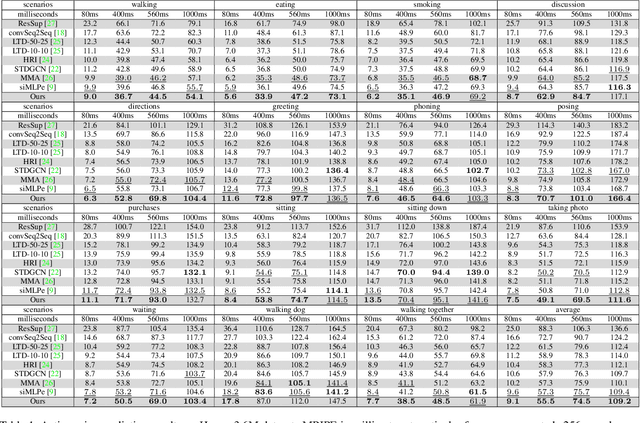
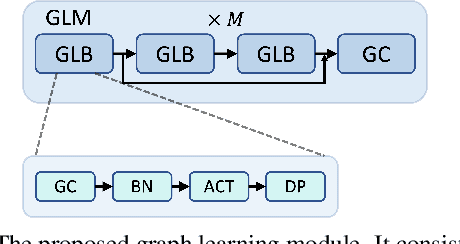

Human motion prediction aims to forecast an upcoming pose sequence given a past human motion trajectory. To address the problem, in this work we propose FreqMRN, a human motion prediction framework that takes into account both the kinematic structure of the human body and the temporal smoothness nature of motion. Specifically, FreqMRN first generates a fixed-size motion history summary using a motion attention module, which helps avoid inaccurate motion predictions due to excessively long motion inputs. Then, supervised by the proposed spatial-temporal-aware, velocity-aware and global-smoothness-aware losses, FreqMRN iteratively refines the predicted motion though the proposed motion refinement module, which converts motion representations back and forth between pose space and frequency space. We evaluate FreqMRN on several standard benchmark datasets, including Human3.6M, AMASS and 3DPW. Experimental results demonstrate that FreqMRN outperforms previous methods by large margins for both short-term and long-term predictions, while demonstrating superior robustness.
Dynamic Graph Node Classification via Time Augmentation
Dec 07, 2022



Node classification for graph-structured data aims to classify nodes whose labels are unknown. While studies on static graphs are prevalent, few studies have focused on dynamic graph node classification. Node classification on dynamic graphs is challenging for two reasons. First, the model needs to capture both structural and temporal information, particularly on dynamic graphs with a long history and require large receptive fields. Second, model scalability becomes a significant concern as the size of the dynamic graph increases. To address these problems, we propose the Time Augmented Dynamic Graph Neural Network (TADGNN) framework. TADGNN consists of two modules: 1) a time augmentation module that captures the temporal evolution of nodes across time structurally, creating a time-augmented spatio-temporal graph, and 2) an information propagation module that learns the dynamic representations for each node across time using the constructed time-augmented graph. We perform node classification experiments on four dynamic graph benchmarks. Experimental results demonstrate that TADGNN framework outperforms several static and dynamic state-of-the-art (SOTA) GNN models while demonstrating superior scalability. We also conduct theoretical and empirical analyses to validate the efficiency of the proposed method. Our code is available at https://sites.google.com/view/tadgnn.