 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsers Mispredict Their Own Preferences for AI Writing Assistance
Jan 08, 2026Proactive AI writing assistants need to predict when users want drafting help, yet we lack empirical understanding of what drives preferences. Through a factorial vignette study with 50 participants making 750 pairwise comparisons, we find compositional effort dominates decisions ($ρ= 0.597$) while urgency shows no predictive power ($ρ\approx 0$). More critically, users exhibit a striking perception-behavior gap: they rank urgency first in self-reports despite it being the weakest behavioral driver, representing a complete preference inversion. This misalignment has measurable consequences. Systems designed from users' stated preferences achieve only 57.7\% accuracy, underperforming even naive baselines, while systems using behavioral patterns reach significantly higher 61.3\% ($p < 0.05$). These findings demonstrate that relying on user introspection for system design actively misleads optimization, with direct implications for proactive natural language generation (NLG) systems.
TransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Empowering Time Series Forecasting with LLM-Agents
Aug 06, 2025Large Language Model (LLM) powered agents have emerged as effective planners for Automated Machine Learning (AutoML) systems. While most existing AutoML approaches focus on automating feature engineering and model architecture search, recent studies in time series forecasting suggest that lightweight models can often achieve state-of-the-art performance. This observation led us to explore improving data quality, rather than model architecture, as a potentially fruitful direction for AutoML on time series data. We propose DCATS, a Data-Centric Agent for Time Series. DCATS leverages metadata accompanying time series to clean data while optimizing forecasting performance. We evaluated DCATS using four time series forecasting models on a large-scale traffic volume forecasting dataset. Results demonstrate that DCATS achieves an average 6% error reduction across all tested models and time horizons, highlighting the potential of data-centric approaches in AutoML for time series forecasting.
Towards Efficient Large Scale Spatial-Temporal Time Series Forecasting via Improved Inverted Transformers
Mar 13, 2025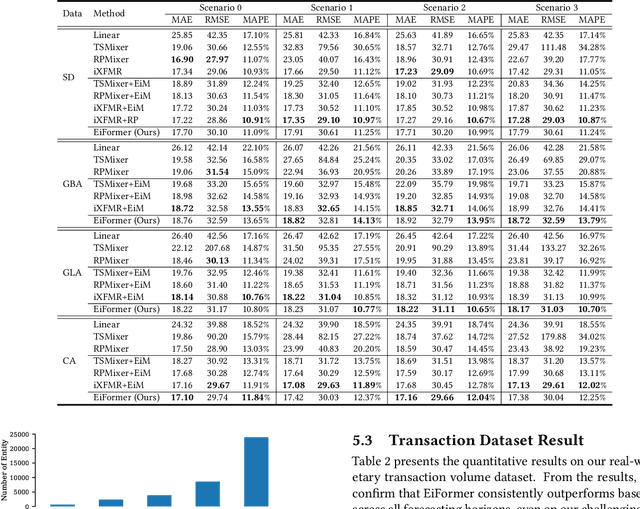
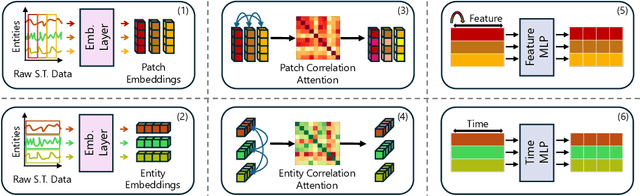
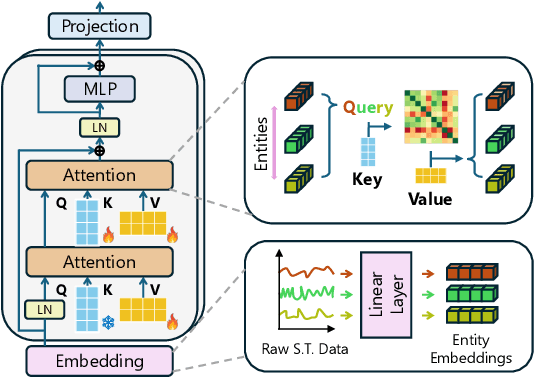
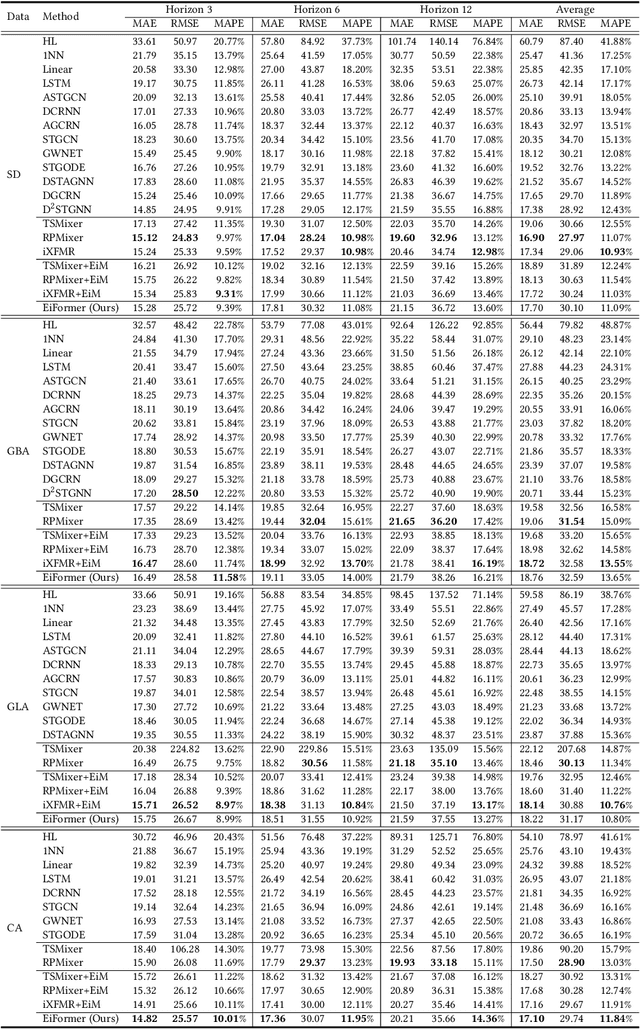
Time series forecasting at scale presents significant challenges for modern prediction systems, particularly when dealing with large sets of synchronized series, such as in a global payment network. In such systems, three key challenges must be overcome for accurate and scalable predictions: 1) emergence of new entities, 2) disappearance of existing entities, and 3) the large number of entities present in the data. The recently proposed Inverted Transformer (iTransformer) architecture has shown promising results by effectively handling variable entities. However, its practical application in large-scale settings is limited by quadratic time and space complexity ($O(N^2)$) with respect to the number of entities $N$. In this paper, we introduce EiFormer, an improved inverted transformer architecture that maintains the adaptive capabilities of iTransformer while reducing computational complexity to linear scale ($O(N)$). Our key innovation lies in restructuring the attention mechanism to eliminate redundant computations without sacrificing model expressiveness. Additionally, we incorporate a random projection mechanism that not only enhances efficiency but also improves prediction accuracy through better feature representation. Extensive experiments on the public LargeST benchmark dataset and a proprietary large-scale time series dataset demonstrate that EiFormer significantly outperforms existing methods in both computational efficiency and forecasting accuracy. Our approach enables practical deployment of transformer-based forecasting in industrial applications where handling time series at scale is essential.
A Compact Model for Large-Scale Time Series Forecasting
Feb 28, 2025



Spatio-temporal data, which commonly arise in real-world applications such as traffic monitoring, financial transactions, and ride-share demands, represent a special category of multivariate time series. They exhibit two distinct characteristics: high dimensionality and commensurability across spatial locations. These attributes call for computationally efficient modeling approaches and facilitate the use of univariate forecasting models in a channel-independent fashion. SparseTSF, a recently introduced competitive univariate forecasting model, harnesses periodicity to achieve compactness by concentrating on cross-period dynamics, thereby extending the Pareto frontier with respect to model size and predictive performance. Nonetheless, it underperforms on spatio-temporal data due to an inadequate capture of intra-period temporal dependencies. To address this shortcoming, we propose UltraSTF, which integrates a cross-period forecasting module with an ultra-compact shape bank component. Our model effectively detects recurring patterns in time series through the attention mechanism of the shape bank component, thereby strengthening its ability to learn intra-period dynamics. UltraSTF achieves state-of-the-art performance on the LargeST benchmark while employing fewer than 0.2% of the parameters required by the second-best approaches, thus further extending the Pareto frontier of existing methods.
Human-aligned Chess with a Bit of Search
Oct 04, 2024
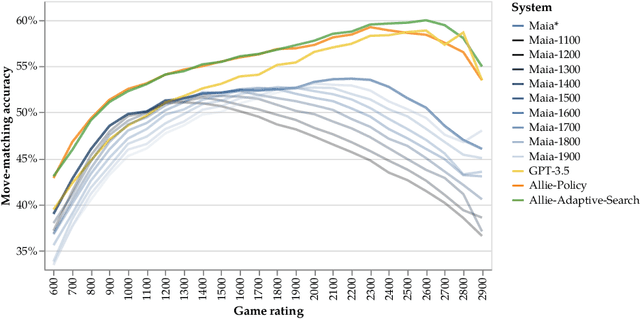

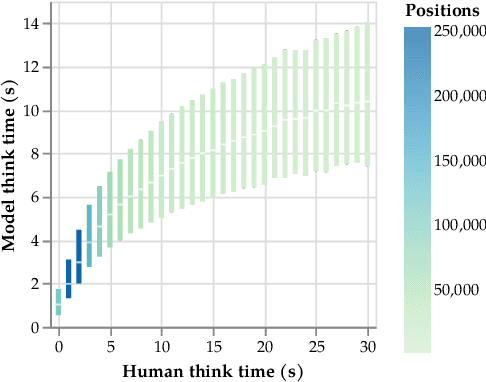
Chess has long been a testbed for AI's quest to match human intelligence, and in recent years, chess AI systems have surpassed the strongest humans at the game. However, these systems are not human-aligned; they are unable to match the skill levels of all human partners or model human-like behaviors beyond piece movement. In this paper, we introduce Allie, a chess-playing AI designed to bridge the gap between artificial and human intelligence in this classic game. Allie is trained on log sequences of real chess games to model the behaviors of human chess players across the skill spectrum, including non-move behaviors such as pondering times and resignations In offline evaluations, we find that Allie exhibits humanlike behavior: it outperforms the existing state-of-the-art in human chess move prediction and "ponders" at critical positions. The model learns to reliably assign reward at each game state, which can be used at inference as a reward function in a novel time-adaptive Monte-Carlo tree search (MCTS) procedure, where the amount of search depends on how long humans would think in the same positions. Adaptive search enables remarkable skill calibration; in a large-scale online evaluation against players with ratings from 1000 to 2600 Elo, our adaptive search method leads to a skill gap of only 49 Elo on average, substantially outperforming search-free and standard MCTS baselines. Against grandmaster-level (2500 Elo) opponents, Allie with adaptive search exhibits the strength of a fellow grandmaster, all while learning exclusively from humans.
Matrix Profile for Anomaly Detection on Multidimensional Time Series
Sep 14, 2024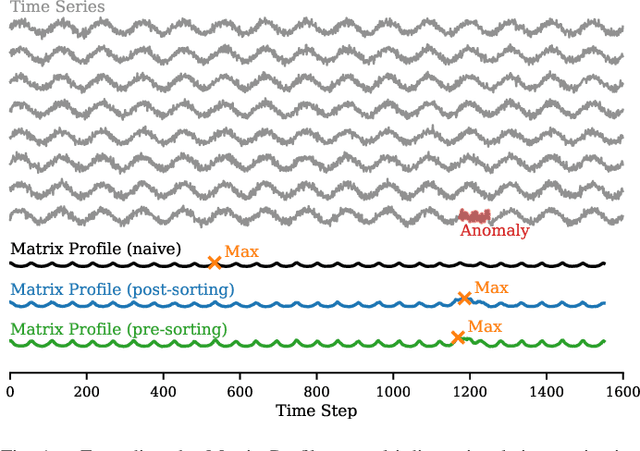
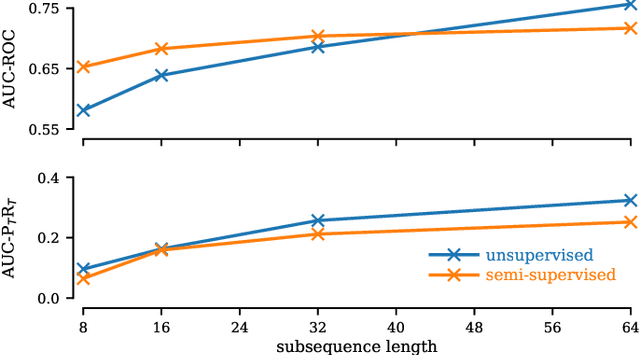
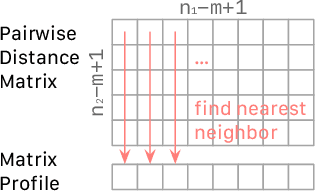
The Matrix Profile (MP), a versatile tool for time series data mining, has been shown effective in time series anomaly detection (TSAD). This paper delves into the problem of anomaly detection in multidimensional time series, a common occurrence in real-world applications. For instance, in a manufacturing factory, multiple sensors installed across the site collect time-varying data for analysis. The Matrix Profile, named for its role in profiling the matrix storing pairwise distance between subsequences of univariate time series, becomes complex in multidimensional scenarios. If the input univariate time series has n subsequences, the pairwise distance matrix is a n x n matrix. In a multidimensional time series with d dimensions, the pairwise distance information must be stored in a n x n x d tensor. In this paper, we first analyze different strategies for condensing this tensor into a profile vector. We then investigate the potential of extending the MP to efficiently find k-nearest neighbors for anomaly detection. Finally, we benchmark the multidimensional MP against 19 baseline methods on 119 multidimensional TSAD datasets. The experiments covers three learning setups: unsupervised, supervised, and semi-supervised. MP is the only method that consistently delivers high performance across all setups.
A Systematic Evaluation of Generated Time Series and Their Effects in Self-Supervised Pretraining
Aug 15, 2024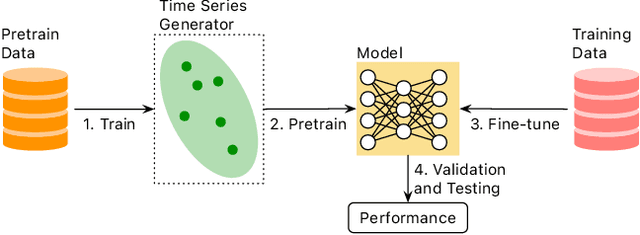



Self-supervised Pretrained Models (PTMs) have demonstrated remarkable performance in computer vision and natural language processing tasks. These successes have prompted researchers to design PTMs for time series data. In our experiments, most self-supervised time series PTMs were surpassed by simple supervised models. We hypothesize this undesired phenomenon may be caused by data scarcity. In response, we test six time series generation methods, use the generated data in pretraining in lieu of the real data, and examine the effects on classification performance. Our results indicate that replacing a real-data pretraining set with a greater volume of only generated samples produces noticeable improvement.
Masked Graph Transformer for Large-Scale Recommendation
May 07, 2024



Graph Transformers have garnered significant attention for learning graph-structured data, thanks to their superb ability to capture long-range dependencies among nodes. However, the quadratic space and time complexity hinders the scalability of Graph Transformers, particularly for large-scale recommendation. Here we propose an efficient Masked Graph Transformer, named MGFormer, capable of capturing all-pair interactions among nodes with a linear complexity. To achieve this, we treat all user/item nodes as independent tokens, enhance them with positional embeddings, and feed them into a kernelized attention module. Additionally, we incorporate learnable relative degree information to appropriately reweigh the attentions. Experimental results show the superior performance of our MGFormer, even with a single attention layer.
Random Projection Layers for Multidimensional Time Series Forecasting
Feb 29, 2024



All-Multi-Layer Perceptron (all-MLP) mixer models have been shown to be effective for time series forecasting problems. However, when such a model is applied to high-dimensional time series (e.g., the time series in a spatial-temporal dataset), its performance is likely to degrade due to overfitting issues. In this paper, we propose an all-MLP time series forecasting architecture, referred to as RPMixer. Our method leverages the ensemble-like behavior of deep neural networks, where each individual block within the network acts like a base learner in an ensemble model, especially when identity mapping residual connections are incorporated. By integrating random projection layers into our model, we increase the diversity among the blocks' outputs, thereby enhancing the overall performance of RPMixer. Extensive experiments conducted on large-scale spatial-temporal forecasting benchmark datasets demonstrate that our proposed method outperforms alternative methods, including both spatial-temporal graph models and general forecasting models.