 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Enhancing Distribution and Label Consistency for Graph Out-of-Distribution Generalization
Jan 07, 2025


To deal with distribution shifts in graph data, various graph out-of-distribution (OOD) generalization techniques have been recently proposed. These methods often employ a two-step strategy that first creates augmented environments and subsequently identifies invariant subgraphs to improve generalizability. Nevertheless, this approach could be suboptimal from the perspective of consistency. First, the process of augmenting environments by altering the graphs while preserving labels may lead to graphs that are not realistic or meaningfully related to the origin distribution, thus lacking distribution consistency. Second, the extracted subgraphs are obtained from directly modifying graphs, and may not necessarily maintain a consistent predictive relationship with their labels, thereby impacting label consistency. In response to these challenges, we introduce an innovative approach that aims to enhance these two types of consistency for graph OOD generalization. We propose a modifier to obtain both augmented and invariant graphs in a unified manner. With the augmented graphs, we enrich the training data without compromising the integrity of label-graph relationships. The label consistency enhancement in our framework further preserves the supervision information in the invariant graph. We conduct extensive experiments on real-world datasets to demonstrate the superiority of our framework over other state-of-the-art baselines.
Encoding Hierarchical Schema via Concept Flow for Multifaceted Ideology Detection
May 29, 2024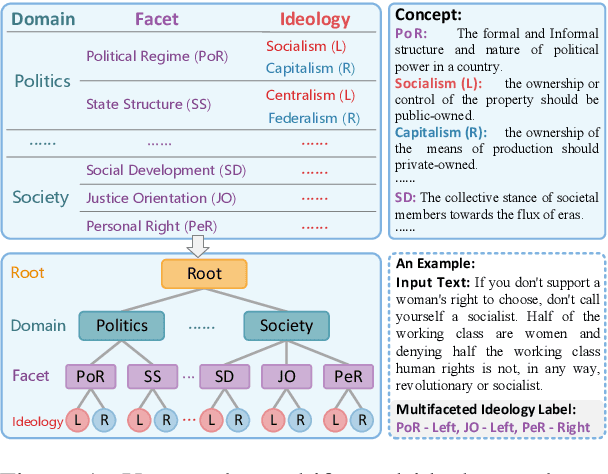
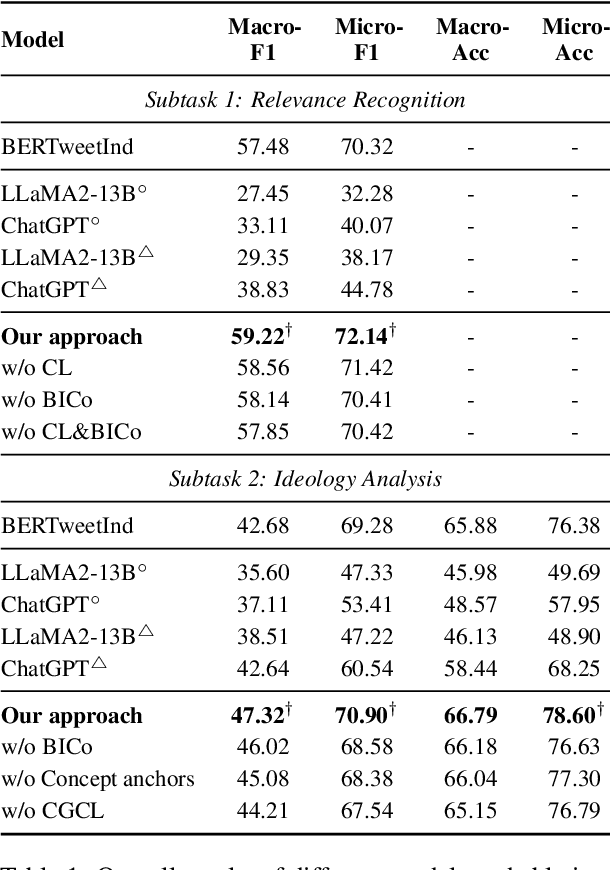
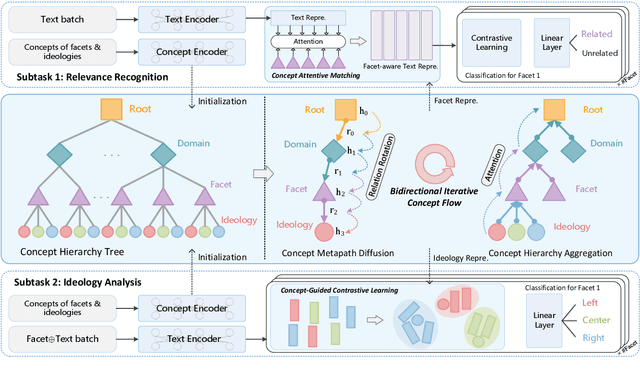

Multifaceted ideology detection (MID) aims to detect the ideological leanings of texts towards multiple facets. Previous studies on ideology detection mainly focus on one generic facet and ignore label semantics and explanatory descriptions of ideologies, which are a kind of instructive information and reveal the specific concepts of ideologies. In this paper, we develop a novel concept semantics-enhanced framework for the MID task. Specifically, we propose a bidirectional iterative concept flow (BICo) method to encode multifaceted ideologies. BICo enables the concepts to flow across levels of the schema tree and enriches concept representations with multi-granularity semantics. Furthermore, we explore concept attentive matching and concept-guided contrastive learning strategies to guide the model to capture ideology features with the learned concept semantics. Extensive experiments on the benchmark dataset show that our approach achieves state-of-the-art performance in MID, including in the cross-topic scenario.
Masked Graph Transformer for Large-Scale Recommendation
May 07, 2024



Graph Transformers have garnered significant attention for learning graph-structured data, thanks to their superb ability to capture long-range dependencies among nodes. However, the quadratic space and time complexity hinders the scalability of Graph Transformers, particularly for large-scale recommendation. Here we propose an efficient Masked Graph Transformer, named MGFormer, capable of capturing all-pair interactions among nodes with a linear complexity. To achieve this, we treat all user/item nodes as independent tokens, enhance them with positional embeddings, and feed them into a kernelized attention module. Additionally, we incorporate learnable relative degree information to appropriately reweigh the attentions. Experimental results show the superior performance of our MGFormer, even with a single attention layer.
Can One Embedding Fit All? A Multi-Interest Learning Paradigm Towards Improving User Interest Diversity Fairness
Feb 21, 2024



Recommender systems (RSs) have gained widespread applications across various domains owing to the superior ability to capture users' interests. However, the complexity and nuanced nature of users' interests, which span a wide range of diversity, pose a significant challenge in delivering fair recommendations. In practice, user preferences vary significantly; some users show a clear preference toward certain item categories, while others have a broad interest in diverse ones. Even though it is expected that all users should receive high-quality recommendations, the effectiveness of RSs in catering to this disparate interest diversity remains under-explored. In this work, we investigate whether users with varied levels of interest diversity are treated fairly. Our empirical experiments reveal an inherent disparity: users with broader interests often receive lower-quality recommendations. To mitigate this, we propose a multi-interest framework that uses multiple (virtual) interest embeddings rather than single ones to represent users. Specifically, the framework consists of stacked multi-interest representation layers, which include an interest embedding generator that derives virtual interests from shared parameters, and a center embedding aggregator that facilitates multi-hop aggregation. Experiments demonstrate the effectiveness of the framework in achieving better trade-off between fairness and utility across various datasets and backbones.
Enhancing Transformers without Self-supervised Learning: A Loss Landscape Perspective in Sequential Recommendation
Aug 20, 2023



Transformer and its variants are a powerful class of architectures for sequential recommendation, owing to their ability of capturing a user's dynamic interests from their past interactions. Despite their success, Transformer-based models often require the optimization of a large number of parameters, making them difficult to train from sparse data in sequential recommendation. To address the problem of data sparsity, previous studies have utilized self-supervised learning to enhance Transformers, such as pre-training embeddings from item attributes or contrastive data augmentations. However, these approaches encounter several training issues, including initialization sensitivity, manual data augmentations, and large batch-size memory bottlenecks. In this work, we investigate Transformers from the perspective of loss geometry, aiming to enhance the models' data efficiency and generalization in sequential recommendation. We observe that Transformers (e.g., SASRec) can converge to extremely sharp local minima if not adequately regularized. Inspired by the recent Sharpness-Aware Minimization (SAM), we propose SAMRec, which significantly improves the accuracy and robustness of sequential recommendation. SAMRec performs comparably to state-of-the-art self-supervised Transformers, such as S$^3$Rec and CL4SRec, without the need for pre-training or strong data augmentations.
An Optimal Energy Efficient Design of Artificial Noise for Preventing Power Leakage based Side-Channel Attacks
Aug 19, 2022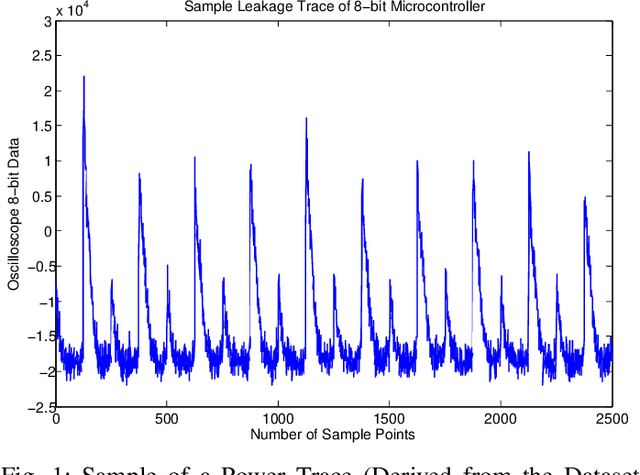

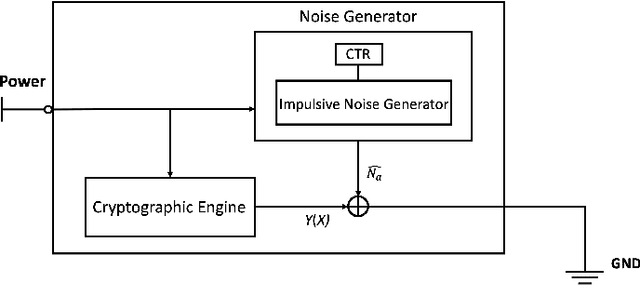
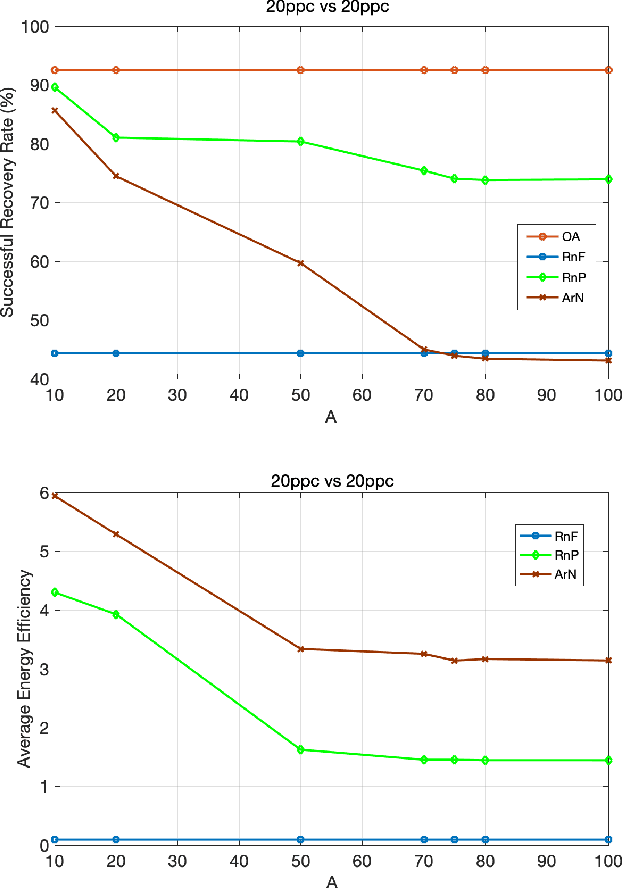
Side-channel attacks (SCAs), which infer secret information (for example secret keys) by exploiting information that leaks from the implementation (such as power consumption), have been shown to be a non-negligible threat to modern cryptographic implementations and devices in recent years. Hence, how to prevent side-channel attacks on cryptographic devices has become an important problem. One of the widely used countermeasures to against power SCAs is the injection of random noise sequences into the raw leakage traces. However, the indiscriminate injection of random noise can lead to significant increases in energy consumption in device, and ways must be found to reduce the amount of energy in noise generation while keeping the side-channel invisible. In this paper, we propose an optimal energy-efficient design for artificial noise generation to prevent side-channel attacks. This approach exploits the sparsity among the leakage traces. We model the side-channel as a communication channel, which allows us to use channel capacity to measure the mutual information between the secret and the leakage traces. For a given energy budget in the noise generation, we obtain the optimal design of the artificial noise injection by solving the side-channel's channel capacity minimization problem. The experimental results also validate the effectiveness of our proposed scheme.