 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALERT: Zero-shot LLM Jailbreak Detection via Internal Discrepancy Amplification
Jan 07, 2026Despite rich safety alignment strategies, large language models (LLMs) remain highly susceptible to jailbreak attacks, which compromise safety guardrails and pose serious security risks. Existing detection methods mainly detect jailbreak status relying on jailbreak templates present in the training data. However, few studies address the more realistic and challenging zero-shot jailbreak detection setting, where no jailbreak templates are available during training. This setting better reflects real-world scenarios where new attacks continually emerge and evolve. To address this challenge, we propose a layer-wise, module-wise, and token-wise amplification framework that progressively magnifies internal feature discrepancies between benign and jailbreak prompts. We uncover safety-relevant layers, identify specific modules that inherently encode zero-shot discriminative signals, and localize informative safety tokens. Building upon these insights, we introduce ALERT (Amplification-based Jailbreak Detector), an efficient and effective zero-shot jailbreak detector that introduces two independent yet complementary classifiers on amplified representations. Extensive experiments on three safety benchmarks demonstrate that ALERT achieves consistently strong zero-shot detection performance. Specifically, (i) across all datasets and attack strategies, ALERT reliably ranks among the top two methods, and (ii) it outperforms the second-best baseline by at least 10% in average Accuracy and F1-score, and sometimes by up to 40%.
TransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Illuminating LLM Coding Agents: Visual Analytics for Deeper Understanding and Enhancement
Aug 18, 2025Coding agents powered by large language models (LLMs) have gained traction for automating code generation through iterative problem-solving with minimal human involvement. Despite the emergence of various frameworks, e.g., LangChain, AutoML, and AIDE, ML scientists still struggle to effectively review and adjust the agents' coding process. The current approach of manually inspecting individual outputs is inefficient, making it difficult to track code evolution, compare coding iterations, and identify improvement opportunities. To address this challenge, we introduce a visual analytics system designed to enhance the examination of coding agent behaviors. Focusing on the AIDE framework, our system supports comparative analysis across three levels: (1) Code-Level Analysis, which reveals how the agent debugs and refines its code over iterations; (2) Process-Level Analysis, which contrasts different solution-seeking processes explored by the agent; and (3) LLM-Level Analysis, which highlights variations in coding behavior across different LLMs. By integrating these perspectives, our system enables ML scientists to gain a structured understanding of agent behaviors, facilitating more effective debugging and prompt engineering. Through case studies using coding agents to tackle popular Kaggle competitions, we demonstrate how our system provides valuable insights into the iterative coding process.
URWKV: Unified RWKV Model with Multi-state Perspective for Low-light Image Restoration
May 29, 2025Existing low-light image enhancement (LLIE) and joint LLIE and deblurring (LLIE-deblur) models have made strides in addressing predefined degradations, yet they are often constrained by dynamically coupled degradations. To address these challenges, we introduce a Unified Receptance Weighted Key Value (URWKV) model with multi-state perspective, enabling flexible and effective degradation restoration for low-light images. Specifically, we customize the core URWKV block to perceive and analyze complex degradations by leveraging multiple intra- and inter-stage states. First, inspired by the pupil mechanism in the human visual system, we propose Luminance-adaptive Normalization (LAN) that adjusts normalization parameters based on rich inter-stage states, allowing for adaptive, scene-aware luminance modulation. Second, we aggregate multiple intra-stage states through exponential moving average approach, effectively capturing subtle variations while mitigating information loss inherent in the single-state mechanism. To reduce the degradation effects commonly associated with conventional skip connections, we propose the State-aware Selective Fusion (SSF) module, which dynamically aligns and integrates multi-state features across encoder stages, selectively fusing contextual information. In comparison to state-of-the-art models, our URWKV model achieves superior performance on various benchmarks, while requiring significantly fewer parameters and computational resources.
Taming Knowledge Conflicts in Language Models
Mar 14, 2025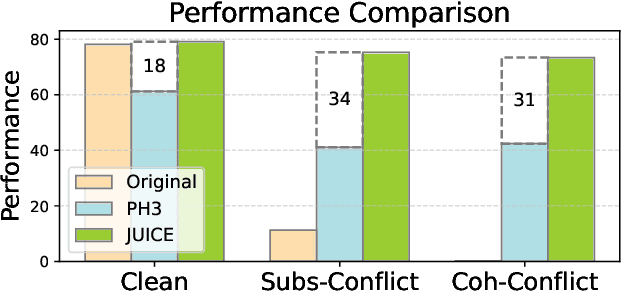
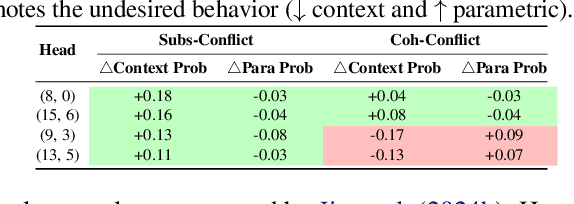
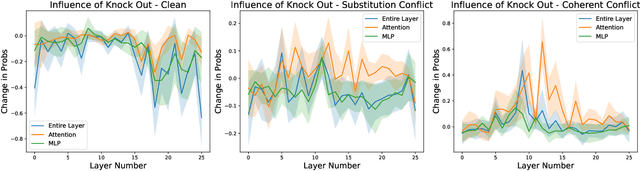

Language Models (LMs) often encounter knowledge conflicts when parametric memory contradicts contextual knowledge. Previous works attribute this conflict to the interplay between "memory heads" and "context heads", attention heads assumed to promote either memory or context exclusively. In this study, we go beyond this fundamental assumption by uncovering a critical phenomenon we term the "superposition of contextual information and parametric memory", where highly influential attention heads could simultaneously contribute to both memory and context. Building upon this insight, we propose Just Run Twice (JUICE), a test-time attention intervention method that steers LMs toward either parametric beliefs or contextual knowledge without requiring fine-tuning. JUICE identifies a set of reliable attention heads and leverages a dual-run approach to mitigate the superposition effects. Extensive experiments across 11 datasets and 6 model architectures demonstrate that JUICE sets the new state-of-the-art performance and robust generalization, achieving significant and consistent improvement across different domains under various conflict types. Finally, we theoretically analyze knowledge conflict and the superposition of contextual information and parametric memory in attention heads, which further elucidates the effectiveness of JUICE in these settings.
THeGCN: Temporal Heterophilic Graph Convolutional Network
Dec 21, 2024Graph Neural Networks (GNNs) have exhibited remarkable efficacy in diverse graph learning tasks, particularly on static homophilic graphs. Recent attention has pivoted towards more intricate structures, encompassing (1) static heterophilic graphs encountering the edge heterophily issue in the spatial domain and (2) event-based continuous graphs in the temporal domain. State-of-the-art (SOTA) has been concurrently addressing these two lines of work but tends to overlook the presence of heterophily in the temporal domain, constituting the temporal heterophily issue. Furthermore, we highlight that the edge heterophily issue and the temporal heterophily issue often co-exist in event-based continuous graphs, giving rise to the temporal edge heterophily challenge. To tackle this challenge, this paper first introduces the temporal edge heterophily measurement. Subsequently, we propose the Temporal Heterophilic Graph Convolutional Network (THeGCN), an innovative model that incorporates the low/high-pass graph signal filtering technique to accurately capture both edge (spatial) heterophily and temporal heterophily. Specifically, the THeGCN model consists of two key components: a sampler and an aggregator. The sampler selects events relevant to a node at a given moment. Then, the aggregator executes message-passing, encoding temporal information, node attributes, and edge attributes into node embeddings. Extensive experiments conducted on 5 real-world datasets validate the efficacy of THeGCN.
TIFG: Text-Informed Feature Generation with Large Language Models
Jun 17, 2024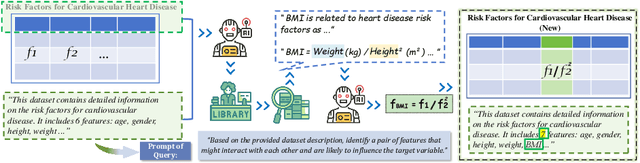
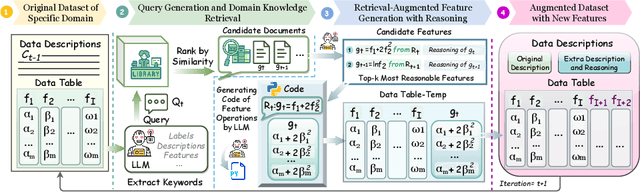

Textual information of data is of vital importance for data mining and feature engineering. However, existing methods focus on learning the data structures and overlook the textual information along with the data. Consequently, they waste this valuable resource and miss out on the deeper data relationships embedded within the texts. In this paper, we introduce Text-Informed Feature Generation (TIFG), a novel LLM-based text-informed feature generation framework. TIFG utilizes the textual information to generate features by retrieving possible relevant features within external knowledge with Retrieval Augmented Generation (RAG) technology. In this approach, the TIFG can generate new explainable features to enrich the feature space and further mine feature relationships. We design the TIFG to be an automated framework that continuously optimizes the feature generation process, adapts to new data inputs, and improves downstream task performance over iterations. A broad range of experiments in various downstream tasks showcases that our approach can generate high-quality and meaningful features, and is significantly superior to existing methods.
Discrete-state Continuous-time Diffusion for Graph Generation
May 19, 2024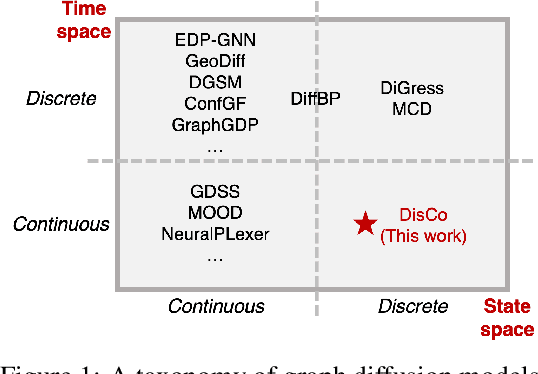
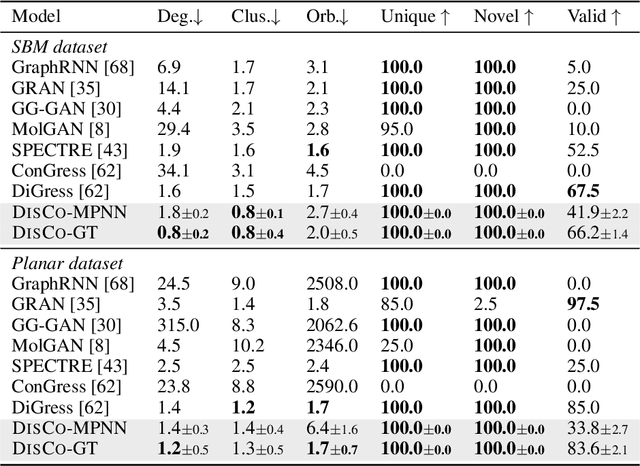

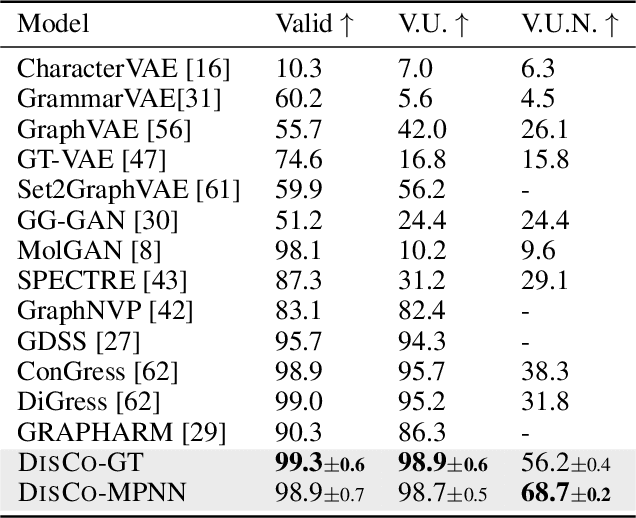
Graph is a prevalent discrete data structure, whose generation has wide applications such as drug discovery and circuit design. Diffusion generative models, as an emerging research focus, have been applied to graph generation tasks. Overall, according to the space of states and time steps, diffusion generative models can be categorized into discrete-/continuous-state discrete-/continuous-time fashions. In this paper, we formulate the graph diffusion generation in a discrete-state continuous-time setting, which has never been studied in previous graph diffusion models. The rationale of such a formulation is to preserve the discrete nature of graph-structured data and meanwhile provide flexible sampling trade-offs between sample quality and efficiency. Analysis shows that our training objective is closely related to generation quality, and our proposed generation framework enjoys ideal invariant/equivariant properties concerning the permutation of node ordering. Our proposed model shows competitive empirical performance against state-of-the-art graph generation solutions on various benchmarks and, at the same time, can flexibly trade off the generation quality and efficiency in the sampling phase.
EgoPAT3Dv2: Predicting 3D Action Target from 2D Egocentric Vision for Human-Robot Interaction
Mar 08, 2024



A robot's ability to anticipate the 3D action target location of a hand's movement from egocentric videos can greatly improve safety and efficiency in human-robot interaction (HRI). While previous research predominantly focused on semantic action classification or 2D target region prediction, we argue that predicting the action target's 3D coordinate could pave the way for more versatile downstream robotics tasks, especially given the increasing prevalence of headset devices. This study expands EgoPAT3D, the sole dataset dedicated to egocentric 3D action target prediction. We augment both its size and diversity, enhancing its potential for generalization. Moreover, we substantially enhance the baseline algorithm by introducing a large pre-trained model and human prior knowledge. Remarkably, our novel algorithm can now achieve superior prediction outcomes using solely RGB images, eliminating the previous need for 3D point clouds and IMU input. Furthermore, we deploy our enhanced baseline algorithm on a real-world robotic platform to illustrate its practical utility in straightforward HRI tasks. The demonstrations showcase the real-world applicability of our advancements and may inspire more HRI use cases involving egocentric vision. All code and data are open-sourced and can be found on the project website.
TransFlower: An Explainable Transformer-Based Model with Flow-to-Flow Attention for Commuting Flow Prediction
Feb 23, 2024Understanding the link between urban planning and commuting flows is crucial for guiding urban development and policymaking. This research, bridging computer science and urban studies, addresses the challenge of integrating these fields with their distinct focuses. Traditional urban studies methods, like the gravity and radiation models, often underperform in complex scenarios due to their limited handling of multiple variables and reliance on overly simplistic and unrealistic assumptions, such as spatial isotropy. While deep learning models offer improved accuracy, their black-box nature poses a trade-off between performance and explainability -- both vital for analyzing complex societal phenomena like commuting flows. To address this, we introduce TransFlower, an explainable, transformer-based model employing flow-to-flow attention to predict urban commuting patterns. It features a geospatial encoder with an anisotropy-aware relative location encoder for nuanced flow representation. Following this, the transformer-based flow predictor enhances this by leveraging attention mechanisms to efficiently capture flow interactions. Our model outperforms existing methods by up to 30.8% Common Part of Commuters, offering insights into mobility dynamics crucial for urban planning and policy decisions.