 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVaT: Single Domain Generalization for Multimodal Visual-Tactile Learning
Jan 01, 2026Visual-tactile learning (VTL) enables embodied agents to perceive the physical world by integrating visual (VIS) and tactile (TAC) sensors. However, VTL still suffers from modality discrepancies between VIS and TAC images, as well as domain gaps caused by non-standardized tactile sensors and inconsistent data collection procedures. We formulate these challenges as a new task, termed single domain generalization for multimodal VTL (SDG-VTL). In this paper, we propose an OmniVaT framework that, for the first time, successfully addresses this task. On the one hand, OmniVaT integrates a multimodal fractional Fourier adapter (MFFA) to map VIS and TAC embeddings into a unified embedding-frequency space, thereby effectively mitigating the modality gap without multi-domain training data or careful cross-modal fusion strategies. On the other hand, it also incorporates a discrete tree generation (DTG) module that obtains diverse and reliable multimodal fractional representations through a hierarchical tree structure, thereby enhancing its adaptivity to fluctuating domain shifts in unseen domains. Extensive experiments demonstrate the superior cross-domain generalization performance of OmniVaT on the SDG-VTL task.
URWKV: Unified RWKV Model with Multi-state Perspective for Low-light Image Restoration
May 29, 2025Existing low-light image enhancement (LLIE) and joint LLIE and deblurring (LLIE-deblur) models have made strides in addressing predefined degradations, yet they are often constrained by dynamically coupled degradations. To address these challenges, we introduce a Unified Receptance Weighted Key Value (URWKV) model with multi-state perspective, enabling flexible and effective degradation restoration for low-light images. Specifically, we customize the core URWKV block to perceive and analyze complex degradations by leveraging multiple intra- and inter-stage states. First, inspired by the pupil mechanism in the human visual system, we propose Luminance-adaptive Normalization (LAN) that adjusts normalization parameters based on rich inter-stage states, allowing for adaptive, scene-aware luminance modulation. Second, we aggregate multiple intra-stage states through exponential moving average approach, effectively capturing subtle variations while mitigating information loss inherent in the single-state mechanism. To reduce the degradation effects commonly associated with conventional skip connections, we propose the State-aware Selective Fusion (SSF) module, which dynamically aligns and integrates multi-state features across encoder stages, selectively fusing contextual information. In comparison to state-of-the-art models, our URWKV model achieves superior performance on various benchmarks, while requiring significantly fewer parameters and computational resources.
SPQE: Structure-and-Perception-Based Quality Evaluation for Image Super-Resolution
May 07, 2022
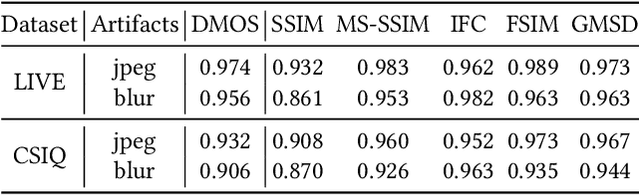

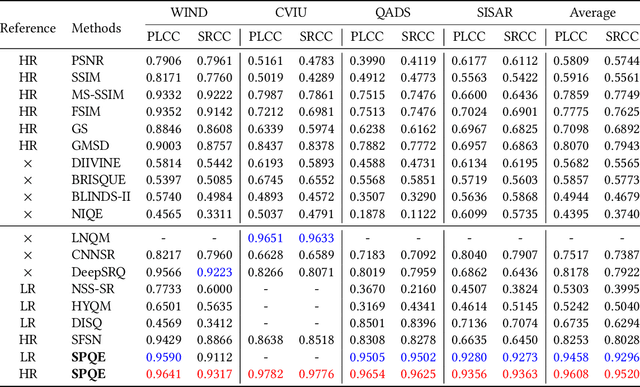
The image Super-Resolution (SR) technique has greatly improved the visual quality of images by enhancing their resolutions. It also calls for an efficient SR Image Quality Assessment (SR-IQA) to evaluate those algorithms or their generated images. In this paper, we focus on the SR-IQA under deep learning and propose a Structure-and-Perception-based Quality Evaluation (SPQE). In emerging deep-learning-based SR, a generated high-quality, visually pleasing image may have different structures from its corresponding low-quality image. In such case, how to balance the quality scores between no-reference perceptual quality and referenced structural similarity is a critical issue. To help ease this problem, we give a theoretical analysis on this tradeoff and further calculate adaptive weights for the two types of quality scores. We also propose two deep-learning-based regressors to model the no-reference and referenced scores. By combining the quality scores and their weights, we propose a unified SPQE metric for SR-IQA. Experimental results demonstrate that the proposed method outperforms the state-of-the-arts in different datasets.
Deep Video Coding with Dual-Path Generative Adversarial Network
Nov 29, 2021

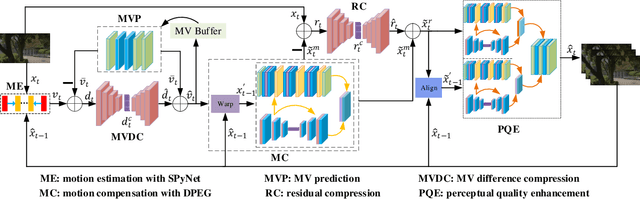
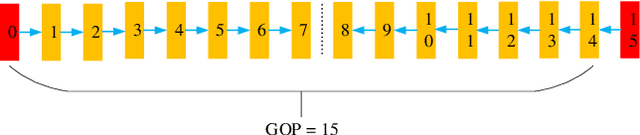
The deep-learning-based video coding has attracted substantial attention for its great potential to squeeze out the spatial-temporal redundancies of video sequences. This paper proposes an efficient codec namely dual-path generative adversarial network-based video codec (DGVC). First, we propose a dual-path enhancement with generative adversarial network (DPEG) to reconstruct the compressed video details. The DPEG consists of an $\alpha$-path of auto-encoder and convolutional long short-term memory (ConvLSTM), which facilitates the structure feature reconstruction with a large receptive field and multi-frame references, and a $\beta$-path of residual attention blocks, which facilitates the reconstruction of local texture features. Both paths are fused and co-trained by a generative-adversarial process. Second, we reuse the DPEG network in both motion compensation and quality enhancement modules, which are further combined with motion estimation and entropy coding modules in our DGVC framework. Third, we employ a joint training of deep video compression and enhancement to further improve the rate-distortion (RD) performance. Compared with x265 LDP very fast mode, our DGVC reduces the average bit-per-pixel (bpp) by 39.39%/54.92% at the same PSNR/MS-SSIM, which outperforms the state-of-the art deep video codecs by a considerable margin.
HDR-GAN: HDR Image Reconstruction from Multi-Exposed LDR Images with Large Motions
Jul 03, 2020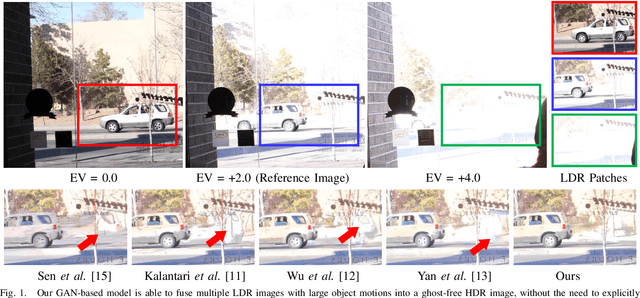
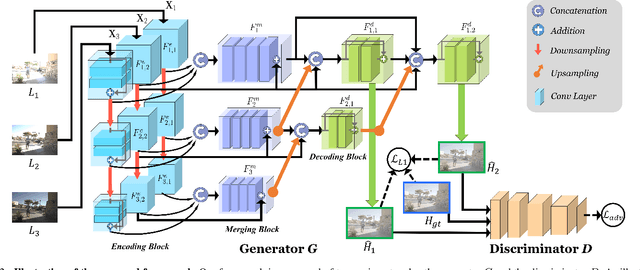

Synthesizing high dynamic range (HDR) images from multiple low-dynamic range (LDR) exposures in dynamic scenes is challenging. There are two major problems caused by the large motions of foreground objects. One is the severe misalignment among the LDR images. The other is the missing content due to the over-/under-saturated regions caused by the moving objects, which may not be easily compensated for by the multiple LDR exposures. Thus, it requires the HDR generation model to be able to properly fuse the LDR images and restore the missing details without introducing artifacts. To address these two problems, we propose in this paper a novel GAN-based model, HDR-GAN, for synthesizing HDR images from multi-exposed LDR images. To our best knowledge, this work is the first GAN-based approach for fusing multi-exposed LDR images for HDR reconstruction. By incorporating adversarial learning, our method is able to produce faithful information in the regions with missing content. In addition, we also propose a novel generator network, with a reference-based residual merging block for aligning large object motions in the feature domain, and a deep HDR supervision scheme for eliminating artifacts of the reconstructed HDR images. Experimental results demonstrate that our model achieves state-of-the-art reconstruction performance over the prior HDR methods on diverse scenes.
Over-crowdedness Alert! Forecasting the Future Crowd Distribution
Jun 09, 2020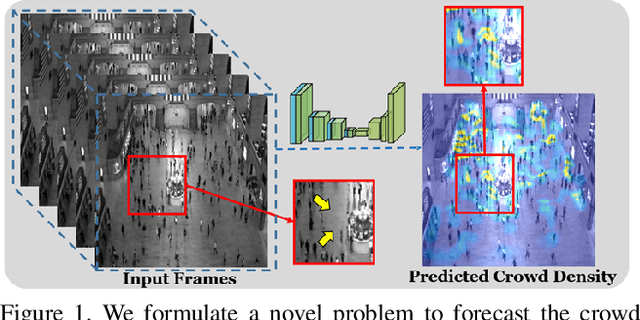
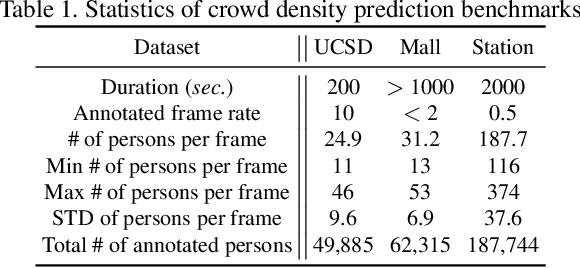
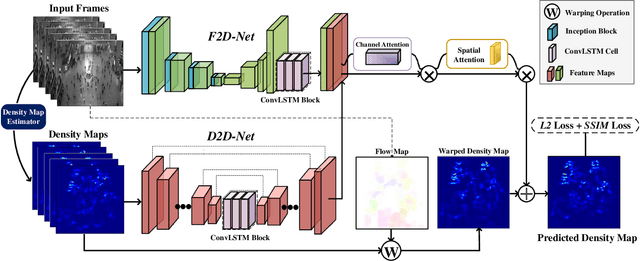

In recent years, vision-based crowd analysis has been studied extensively due to its practical applications in real world. In this paper, we formulate a novel crowd analysis problem, in which we aim to predict the crowd distribution in the near future given sequential frames of a crowd video without any identity annotations. Studying this research problem will benefit applications concerned with forecasting crowd dynamics. To solve this problem, we propose a global-residual two-stream recurrent network, which leverages the consecutive crowd video frames as inputs and their corresponding density maps as auxiliary information to predict the future crowd distribution. Moreover, to strengthen the capability of our network, we synthesize scene-specific crowd density maps using simulated data for pretraining. Finally, we demonstrate that our framework is able to predict the crowd distribution for different crowd scenarios and we delve into applications including predicting future crowd count, forecasting high-density region, etc.