 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient VVC Intra Prediction Based on Deep Feature Fusion and Probability Estimation
May 07, 2022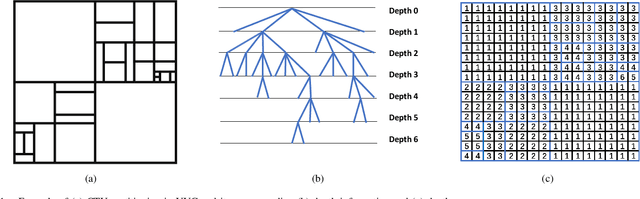
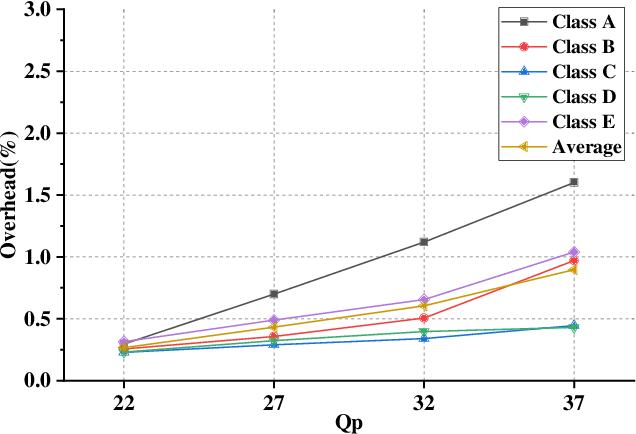
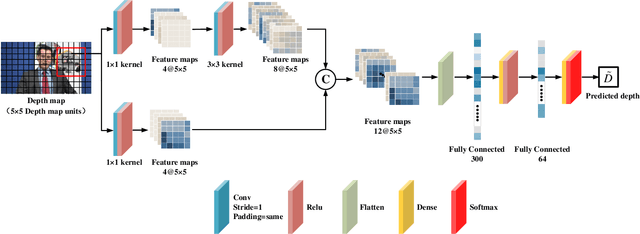
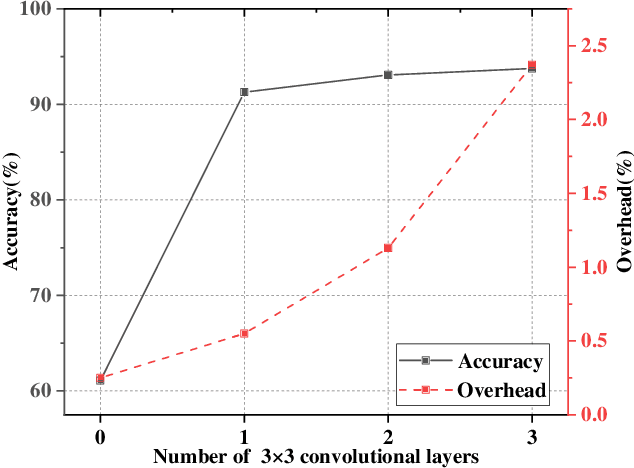
The ever-growing multimedia traffic has underscored the importance of effective multimedia codecs. Among them, the up-to-date lossy video coding standard, Versatile Video Coding (VVC), has been attracting attentions of video coding community. However, the gain of VVC is achieved at the cost of significant encoding complexity, which brings the need to realize fast encoder with comparable Rate Distortion (RD) performance. In this paper, we propose to optimize the VVC complexity at intra-frame prediction, with a two-stage framework of deep feature fusion and probability estimation. At the first stage, we employ the deep convolutional network to extract the spatialtemporal neighboring coding features. Then we fuse all reference features obtained by different convolutional kernels to determine an optimal intra coding depth. At the second stage, we employ a probability-based model and the spatial-temporal coherence to select the candidate partition modes within the optimal coding depth. Finally, these selected depths and partitions are executed whilst unnecessary computations are excluded. Experimental results on standard database demonstrate the superiority of proposed method, especially for High Definition (HD) and Ultra-HD (UHD) video sequences.
Deep Video Coding with Dual-Path Generative Adversarial Network
Nov 29, 2021

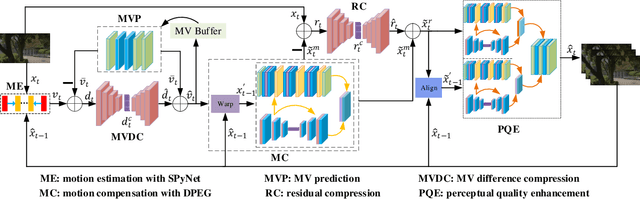
The deep-learning-based video coding has attracted substantial attention for its great potential to squeeze out the spatial-temporal redundancies of video sequences. This paper proposes an efficient codec namely dual-path generative adversarial network-based video codec (DGVC). First, we propose a dual-path enhancement with generative adversarial network (DPEG) to reconstruct the compressed video details. The DPEG consists of an $\alpha$-path of auto-encoder and convolutional long short-term memory (ConvLSTM), which facilitates the structure feature reconstruction with a large receptive field and multi-frame references, and a $\beta$-path of residual attention blocks, which facilitates the reconstruction of local texture features. Both paths are fused and co-trained by a generative-adversarial process. Second, we reuse the DPEG network in both motion compensation and quality enhancement modules, which are further combined with motion estimation and entropy coding modules in our DGVC framework. Third, we employ a joint training of deep video compression and enhancement to further improve the rate-distortion (RD) performance. Compared with x265 LDP very fast mode, our DGVC reduces the average bit-per-pixel (bpp) by 39.39%/54.92% at the same PSNR/MS-SSIM, which outperforms the state-of-the art deep video codecs by a considerable margin.