 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of CT Degradation for LDCT Nodule Classification using Radiomics
May 12, 2026Low-dose computed tomography (LDCT) is the standard modality for lung cancer screening, known for its low radiation dose but high noise levels. While existing literature focuses on denoising LDCT images, comparative research on simulating LDCT characteristics to directly use these images for model development is lacking. This study shifts the focus from denoising images to degrading available standard-dose CT (SDCT) data, generating synthetic images for data augmentation to train classifiers for screening-detected nodules. We compare three degradation methods: (1) a sinogram domain statistical noise insertion; (2) replicate a validated physics-based simulation using Pix2Pix; and (3) unpaired CycleGAN. The generated images were utilized to simulate LDCT screening scenario replacing 695 SDCT cases from the LIDC-IDRI dataset, from which radiomic features were extracted to train machine learning models for lung nodule classification. Regarding image quality, CycleGAN achieved the best Fréchet inception distance (0.1734) and kernel inception distance (0.0813; 0.1002) scores, indicating distributional alignment with the target low-dose domain. In the nodule classification task, results confirmed the necessity of domain adaptation since a baseline model trained on non-degraded SDCT data failed to generalize to the real LDCT set (AUC 0.789) with a low sensitivity (0.571). Degraded images generated using CycleGAN approach led to the most balanced performance on the classification task using Adam Booster classifier, achieving an AUC of 0.861, sensitivity of 0.743 and specificity of 0.858 in the independent test. Our findings confirm that generating synthetic LDCT data from standard-dose scans is a viable strategy for training robust nodule classifiers for screening detected nodules.
Adaptive Context Matters: Towards Provable Multi-Modality Guidance for Super-Resolution
May 11, 2026Super-resolution (SR) is a severely ill-posed problem with inherent ambiguity, as widely recognized in both empirical and theoretical studies. Although recent semantic-guided and multi-modal SR methods exploit large models or external priors to enhance semantic alignment, the fusion of heterogeneous modalities remains insufficiently understood in practice and theory. In this work, we provide the first theoretical modeling of multi-modal SR, revealing that prior methods are bottlenecked by sub-optimal modality utilization. Our analysis shows that the generalization risk bound can be improved by strengthening the alignment between modality weights and their effective contributions, while reducing representation complexity. This theoretical insight inspires us to propose the novel Multi-Modal Mixture-of-Experts Super-Resolution framework (M$^3$ESR) that employs generalization-oriented dynamic modality fusion for accurate risk control and modality contribution optimization. In detail, we propose a novel spatially dynamic modality weighting module and a temporally adaptive modality temperature scheduling mechanism, enabling flexible and adaptive spatial-temporal modality weighting for effective risk control. Extensive experiments demonstrate that our M$^3$ESR significantly boosts generalization and semantic consistency performances, which confirms our superiority.
From Noisy Historical Maps to Time-Series Oil Palm Mapping Without Annotation in Malaysia and Indonesia (2020-2024)
Apr 26, 2026Accurate monitoring of oil palm plantations is critical for balancing economic development with environmental conservation in Southeast Asia. However, existing plantation maps often suffer from low spatial resolution and a lack of recent temporal coverage, impeding effective surveillance of rapid land-use changes. In this study, we propose a deep learning framework to generate 10-meter resolution oil palm plantation maps for Indonesia and Malaysia from 2020 to 2024, utilizing Sentinel-2 imagery without requiring new manual annotations. To address the resolution mismatch between coarse 100-meter historical labels and 10-meter imagery, we employ a U-Net architecture optimized with Determinant-based Mutual Information (DMI). This approach effectively mitigates the influence of label noise. We validated our method against 2,058 manually verified points, achieving overall accuracies of 70.64%, 63.53%, and 60.06% for the years 2020, 2022, and 2024, respectively. Our comprehensive analysis reveals that oil palm coverage in the region peaked in 2022 before experiencing a decline in 2024. Furthermore, land cover transition analysis highlights a concerning trajectory of plantation expansion into flooded vegetation areas, despite a general stabilization in rotations with other crop types. These high-resolution maps provide essential data for monitoring sustainability commitments and deforestation dynamics in the region, and the generated datasets are made publicly available at https://doi.org/10.5281/zenodo.17768444.
VibeFlow: Versatile Video Chroma-Lux Editing through Self-Supervised Learning
Apr 15, 2026Video chroma-lux editing, which aims to modify illumination and color while preserving structural and temporal fidelity, remains a significant challenge. Existing methods typically rely on expensive supervised training with synthetic paired data. This paper proposes VibeFlow, a novel self-supervised framework that unleashes the intrinsic physical understanding of pre-trained video generation models. Instead of learning color and light transitions from scratch, we introduce a disentangled data perturbation pipeline that enforces the model to adaptively recombine structure from source videos and color-illumination cues from reference images, enabling robust disentanglement in a self-supervised manner. Furthermore, to rectify discretization errors inherent in flow-based models, we introduce Residual Velocity Fields alongside a Structural Distortion Consistency Regularization, ensuring rigorous structural preservation and temporal coherence. Our framework eliminates the need for costly training resources and generalizes in a zero-shot manner to diverse applications, including video relighting, recoloring, low-light enhancement, day-night translation, and object-specific color editing. Extensive experiments demonstrate that VibeFlow achieves impressive visual quality with significantly reduced computational overhead. Our project is publicly available at https://lyf1212.github.io/VibeFlow-webpage.
Explaining Synergistic Effects in Social Recommendations
Jan 26, 2026In social recommenders, the inherent nonlinearity and opacity of synergistic effects across multiple social networks hinders users from understanding how diverse information is leveraged for recommendations, consequently diminishing explainability. However, existing explainers can only identify the topological information in social networks that significantly influences recommendations, failing to further explain the synergistic effects among this information. Inspired by existing findings that synergistic effects enhance mutual information between inputs and predictions to generate information gain, we extend this discovery to graph data. We quantify graph information gain to identify subgraphs embodying synergistic effects. Based on the theoretical insights, we propose SemExplainer, which explains synergistic effects by identifying subgraphs that embody them. SemExplainer first extracts explanatory subgraphs from multi-view social networks to generate preliminary importance explanations for recommendations. A conditional entropy optimization strategy to maximize information gain is developed, thereby further identifying subgraphs that embody synergistic effects from explanatory subgraphs. Finally, SemExplainer searches for paths from users to recommended items within the synergistic subgraphs to generate explanations for the recommendations. Extensive experiments on three datasets demonstrate the superiority of SemExplainer over baseline methods, providing superior explanations of synergistic effects.
Bridging Semantic Understanding and Popularity Bias with LLMs
Jan 15, 2026Semantic understanding of popularity bias is a crucial yet underexplored challenge in recommender systems, where popular items are often favored at the expense of niche content. Most existing debiasing methods treat the semantic understanding of popularity bias as a matter of diversity enhancement or long-tail coverage, neglecting the deeper semantic layer that embodies the causal origins of the bias itself. Consequently, such shallow interpretations limit both their debiasing effectiveness and recommendation accuracy. In this paper, we propose FairLRM, a novel framework that bridges the gap in the semantic understanding of popularity bias with Recommendation via Large Language Model (RecLLM). FairLRM decomposes popularity bias into item-side and user-side components, using structured instruction-based prompts to enhance the model's comprehension of both global item distributions and individual user preferences. Unlike traditional methods that rely on surface-level features such as "diversity" or "debiasing", FairLRM improves the model's ability to semantically interpret and address the underlying bias. Through empirical evaluation, we show that FairLRM significantly enhances both fairness and recommendation accuracy, providing a more semantically aware and trustworthy approach to enhance the semantic understanding of popularity bias. The implementation is available at https://github.com/LuoRenqiang/FairLRM.
Language-based Image Colorization: A Benchmark and Beyond
Mar 19, 2025Image colorization aims to bring colors back to grayscale images. Automatic image colorization methods, which requires no additional guidance, struggle to generate high-quality images due to color ambiguity, and provides limited user controllability. Thanks to the emergency of cross-modality datasets and models, language-based colorization methods are proposed to fully utilize the efficiency and flexibly of text descriptions to guide colorization. In view of the lack of a comprehensive review of language-based colorization literature, we conduct a thorough analysis and benchmarking. We first briefly summarize existing automatic colorization methods. Then, we focus on language-based methods and point out their core challenge on cross-modal alignment. We further divide these methods into two categories: one attempts to train a cross-modality network from scratch, while the other utilizes the pre-trained cross-modality model to establish the textual-visual correspondence. Based on the analyzed limitations of existing language-based methods, we propose a simple yet effective method based on distilled diffusion model. Extensive experiments demonstrate that our simple baseline can produces better results than previous complex methods with 14 times speed up. To the best of our knowledge, this is the first comprehensive review and benchmark on language-based image colorization field, providing meaningful insights for the community. The code is available at https://github.com/lyf1212/Color-Turbo.
PTDiffusion: Free Lunch for Generating Optical Illusion Hidden Pictures with Phase-Transferred Diffusion Model
Mar 08, 2025Optical illusion hidden picture is an interesting visual perceptual phenomenon where an image is cleverly integrated into another picture in a way that is not immediately obvious to the viewer. Established on the off-the-shelf text-to-image (T2I) diffusion model, we propose a novel training-free text-guided image-to-image (I2I) translation framework dubbed as \textbf{P}hase-\textbf{T}ransferred \textbf{Diffusion} Model (PTDiffusion) for hidden art syntheses. PTDiffusion embeds an input reference image into arbitrary scenes as described by the text prompts, while exhibiting hidden visual cues of the reference image. At the heart of our method is a plug-and-play phase transfer mechanism that dynamically and progressively transplants diffusion features' phase spectrum from the denoising process to reconstruct the reference image into the one to sample the generated illusion image, realizing harmonious fusion of the reference structural information and the textual semantic information. Furthermore, we propose asynchronous phase transfer to enable flexible control to the degree of hidden content discernability. Our method bypasses any model training and fine-tuning, all while substantially outperforming related methods in image quality, text fidelity, visual discernibility, and contextual naturalness for illusion picture synthesis, as demonstrated by extensive qualitative and quantitative experiments.
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
Nov 12, 2024
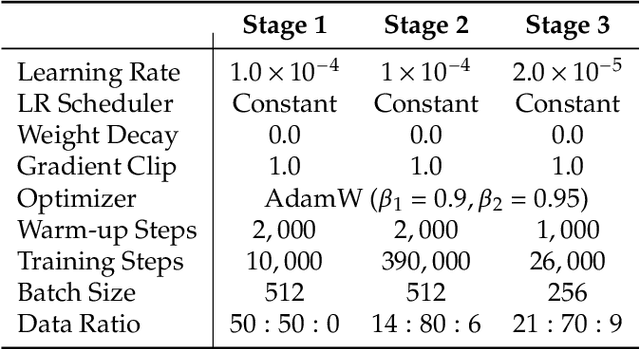

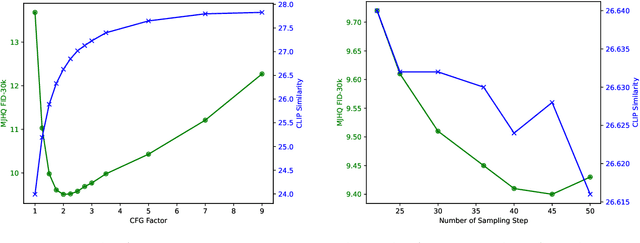
We present JanusFlow, a powerful framework that unifies image understanding and generation in a single model. JanusFlow introduces a minimalist architecture that integrates autoregressive language models with rectified flow, a state-of-the-art method in generative modeling. Our key finding demonstrates that rectified flow can be straightforwardly trained within the large language model framework, eliminating the need for complex architectural modifications. To further improve the performance of our unified model, we adopt two key strategies: (i) decoupling the understanding and generation encoders, and (ii) aligning their representations during unified training. Extensive experiments show that JanusFlow achieves comparable or superior performance to specialized models in their respective domains, while significantly outperforming existing unified approaches across standard benchmarks. This work represents a step toward more efficient and versatile vision-language models.
Idempotent Unsupervised Representation Learning for Skeleton-Based Action Recognition
Oct 27, 2024Generative models, as a powerful technique for generation, also gradually become a critical tool for recognition tasks. However, in skeleton-based action recognition, the features obtained from existing pre-trained generative methods contain redundant information unrelated to recognition, which contradicts the nature of the skeleton's spatially sparse and temporally consistent properties, leading to undesirable performance. To address this challenge, we make efforts to bridge the gap in theory and methodology and propose a novel skeleton-based idempotent generative model (IGM) for unsupervised representation learning. More specifically, we first theoretically demonstrate the equivalence between generative models and maximum entropy coding, which demonstrates a potential route that makes the features of generative models more compact by introducing contrastive learning. To this end, we introduce the idempotency constraint to form a stronger consistency regularization in the feature space, to push the features only to maintain the critical information of motion semantics for the recognition task. Our extensive experiments on benchmark datasets, NTU RGB+D and PKUMMD, demonstrate the effectiveness of our proposed method. On the NTU 60 xsub dataset, we observe a performance improvement from 84.6$\%$ to 86.2$\%$. Furthermore, in zero-shot adaptation scenarios, our model demonstrates significant efficacy by achieving promising results in cases that were previously unrecognizable. Our project is available at \url{https://github.com/LanglandsLin/IGM}.