 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Adaptation into Assets: Cross-Domain Bridging for Online Vision-Language Navigation
May 22, 2026Navigating under non-stationary environment shifts poses a critical challenge for a Vision-and-Language Navigation (VLN) agent deployed in the wild. Yet, existing Test-Time Adaptation (TTA) methods for VLN largely treat online adaptation as transient, isolated updates, leading to catastrophic forgetting and negative transfer. To overcome these issues, we propose Inter-Domain BridgE with Historical Assets (IDEA), a novel TTA framework that transforms adaptation into the accumulation and composition of assets. Specifically, IDEA introduces soft prompts optimized via a Fisher-guided weighting scheme to capture the transferable knowledge. These optimized prompts are then augmented with domain coordinates to form a dynamic asset library. Leveraging this library, IDEA constructs a cross-domain bridge by projecting the target domain onto the convex hull of historical knowledge. These designs form a complementary loop: the evolving library underpins bridge construction, while the bridge provides superior initialization to accelerate asset optimization. Extensive experiments across REVERIE, R2R, and R2R-CE benchmarks demonstrate the consistent superiority of IDEA over existing methods, showcasing its ability to enable training-free adaptation via asset sharing.
LabUtopia: High-Fidelity Simulation and Hierarchical Benchmark for Scientific Embodied Agents
May 28, 2025

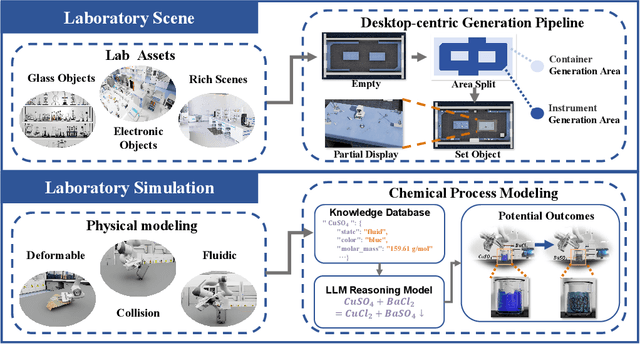
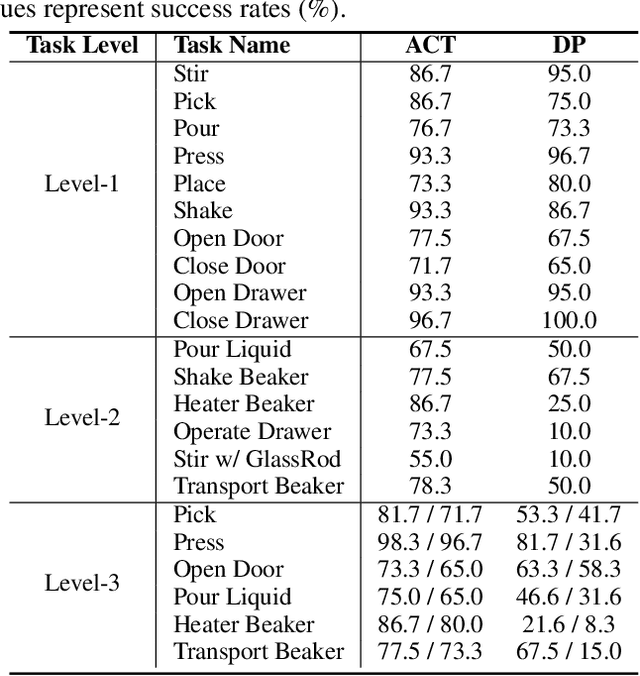
Scientific embodied agents play a crucial role in modern laboratories by automating complex experimental workflows. Compared to typical household environments, laboratory settings impose significantly higher demands on perception of physical-chemical transformations and long-horizon planning, making them an ideal testbed for advancing embodied intelligence. However, its development has been long hampered by the lack of suitable simulator and benchmarks. In this paper, we address this gap by introducing LabUtopia, a comprehensive simulation and benchmarking suite designed to facilitate the development of generalizable, reasoning-capable embodied agents in laboratory settings. Specifically, it integrates i) LabSim, a high-fidelity simulator supporting multi-physics and chemically meaningful interactions; ii) LabScene, a scalable procedural generator for diverse scientific scenes; and iii) LabBench, a hierarchical benchmark spanning five levels of complexity from atomic actions to long-horizon mobile manipulation. LabUtopia supports 30 distinct tasks and includes more than 200 scene and instrument assets, enabling large-scale training and principled evaluation in high-complexity environments. We demonstrate that LabUtopia offers a powerful platform for advancing the integration of perception, planning, and control in scientific-purpose agents and provides a rigorous testbed for exploring the practical capabilities and generalization limits of embodied intelligence in future research.
Beyond Entropy: Region Confidence Proxy for Wild Test-Time Adaptation
May 27, 2025Wild Test-Time Adaptation (WTTA) is proposed to adapt a source model to unseen domains under extreme data scarcity and multiple shifts. Previous approaches mainly focused on sample selection strategies, while overlooking the fundamental problem on underlying optimization. Initially, we critically analyze the widely-adopted entropy minimization framework in WTTA and uncover its significant limitations in noisy optimization dynamics that substantially hinder adaptation efficiency. Through our analysis, we identify region confidence as a superior alternative to traditional entropy, however, its direct optimization remains computationally prohibitive for real-time applications. In this paper, we introduce a novel region-integrated method ReCAP that bypasses the lengthy process. Specifically, we propose a probabilistic region modeling scheme that flexibly captures semantic changes in embedding space. Subsequently, we develop a finite-to-infinite asymptotic approximation that transforms the intractable region confidence into a tractable and upper-bounded proxy. These innovations significantly unlock the overlooked potential dynamics in local region in a concise solution. Our extensive experiments demonstrate the consistent superiority of ReCAP over existing methods across various datasets and wild scenarios.
SEVA: Leveraging Single-Step Ensemble of Vicinal Augmentations for Test-Time Adaptation
May 07, 2025Test-Time adaptation (TTA) aims to enhance model robustness against distribution shifts through rapid model adaptation during inference. While existing TTA methods often rely on entropy-based unsupervised training and achieve promising results, the common practice of a single round of entropy training is typically unable to adequately utilize reliable samples, hindering adaptation efficiency. In this paper, we discover augmentation strategies can effectively unleash the potential of reliable samples, but the rapidly growing computational cost impedes their real-time application. To address this limitation, we propose a novel TTA approach named Single-step Ensemble of Vicinal Augmentations (SEVA), which can take advantage of data augmentations without increasing the computational burden. Specifically, instead of explicitly utilizing the augmentation strategy to generate new data, SEVA develops a theoretical framework to explore the impacts of multiple augmentations on model adaptation and proposes to optimize an upper bound of the entropy loss to integrate the effects of multiple rounds of augmentation training into a single step. Furthermore, we discover and verify that using the upper bound as the loss is more conducive to the selection mechanism, as it can effectively filter out harmful samples that confuse the model. Combining these two key advantages, the proposed efficient loss and a complementary selection strategy can simultaneously boost the potential of reliable samples and meet the stringent time requirements of TTA. The comprehensive experiments on various network architectures across challenging testing scenarios demonstrate impressive performances and the broad adaptability of SEVA. The code will be publicly available.
Robust and Transferable Backdoor Attacks Against Deep Image Compression With Selective Frequency Prior
Dec 02, 2024



Recent advancements in deep learning-based compression techniques have surpassed traditional methods. However, deep neural networks remain vulnerable to backdoor attacks, where pre-defined triggers induce malicious behaviors. This paper introduces a novel frequency-based trigger injection model for launching backdoor attacks with multiple triggers on learned image compression models. Inspired by the widely used DCT in compression codecs, triggers are embedded in the DCT domain. We design attack objectives tailored to diverse scenarios, including: 1) degrading compression quality in terms of bit-rate and reconstruction accuracy; 2) targeting task-driven measures like face recognition and semantic segmentation. To improve training efficiency, we propose a dynamic loss function that balances loss terms with fewer hyper-parameters, optimizing attack objectives effectively. For advanced scenarios, we evaluate the attack's resistance to defensive preprocessing and propose a two-stage training schedule with robust frequency selection to enhance resilience. To improve cross-model and cross-domain transferability for downstream tasks, we adjust the classification boundary in the attack loss during training. Experiments show that our trigger injection models, combined with minor modifications to encoder parameters, successfully inject multiple backdoors and their triggers into a single compression model, demonstrating strong performance and versatility. (*Due to the notification of arXiv "The Abstract field cannot be longer than 1,920 characters", the appeared Abstract is shortened. For the full Abstract, please download the Article.)
DenseFusion-1M: Merging Vision Experts for Comprehensive Multimodal Perception
Jul 11, 2024



Existing Multimodal Large Language Models (MLLMs) increasingly emphasize complex understanding of various visual elements, including multiple objects, text information, and spatial relations. Their development for comprehensive visual perception hinges on the availability of high-quality image-text datasets that offer diverse visual elements and throughout image descriptions. However, the scarcity of such hyper-detailed datasets currently hinders progress within the MLLM community. The bottleneck stems from the limited perceptual capabilities of current caption engines, which fall short in providing complete and accurate annotations. To facilitate the cutting-edge research of MLLMs on comprehensive vision perception, we thereby propose Perceptual Fusion, using a low-budget but highly effective caption engine for complete and accurate image descriptions. Specifically, Perceptual Fusion integrates diverse perception experts as image priors to provide explicit information on visual elements and adopts an efficient MLLM as a centric pivot to mimic advanced MLLMs' perception abilities. We carefully select 1M highly representative images from uncurated LAION dataset and generate dense descriptions using our engine, dubbed DenseFusion-1M. Extensive experiments validate that our engine outperforms its counterparts, where the resulting dataset significantly improves the perception and cognition abilities of existing MLLMs across diverse vision-language benchmarks, especially with high-resolution images as inputs. The dataset and code are publicly available at https://github.com/baaivision/DenseFusion.
Coding for Intelligence from the Perspective of Category
Jul 02, 2024



Coding, which targets compressing and reconstructing data, and intelligence, often regarded at an abstract computational level as being centered around model learning and prediction, interweave recently to give birth to a series of significant progress. The recent trends demonstrate the potential homogeneity of these two fields, especially when deep-learning models aid these two categories for better probability modeling. For better understanding and describing from a unified perspective, inspired by the basic generally recognized principles in cognitive psychology, we formulate a novel problem of Coding for Intelligence from the category theory view. Based on the three axioms: existence of ideal coding, existence of practical coding, and compactness promoting generalization, we derive a general framework to understand existing methodologies, namely that, coding captures the intrinsic relationships of objects as much as possible, while ignoring information irrelevant to downstream tasks. This framework helps identify the challenges and essential elements in solving the specific derived Minimal Description Length (MDL) optimization problem from a broader range, providing opportunities to build a more intelligent system for handling multiple tasks/applications with coding ideas/tools. Centering on those elements, we systematically review recent processes of towards optimizing the MDL problem in more comprehensive ways from data, model, and task perspectives, and reveal their impacts on the potential CfI technical routes. After that, we also present new technique paths to fulfill CfI and provide potential solutions with preliminary experimental evidence. Last, further directions and remaining issues are discussed as well. The discussion shows our theory can reveal many phenomena and insights about large foundation models, which mutually corroborate with recent practices in feature learning.
Exploring Model Transferability through the Lens of Potential Energy
Aug 29, 2023



Transfer learning has become crucial in computer vision tasks due to the vast availability of pre-trained deep learning models. However, selecting the optimal pre-trained model from a diverse pool for a specific downstream task remains a challenge. Existing methods for measuring the transferability of pre-trained models rely on statistical correlations between encoded static features and task labels, but they overlook the impact of underlying representation dynamics during fine-tuning, leading to unreliable results, especially for self-supervised models. In this paper, we present an insightful physics-inspired approach named PED to address these challenges. We reframe the challenge of model selection through the lens of potential energy and directly model the interaction forces that influence fine-tuning dynamics. By capturing the motion of dynamic representations to decline the potential energy within a force-driven physical model, we can acquire an enhanced and more stable observation for estimating transferability. The experimental results on 10 downstream tasks and 12 self-supervised models demonstrate that our approach can seamlessly integrate into existing ranking techniques and enhance their performances, revealing its effectiveness for the model selection task and its potential for understanding the mechanism in transfer learning. Code will be available at https://github.com/lixiaotong97/PED.
Modeling Uncertain Feature Representation for Domain Generalization
Jan 16, 2023Though deep neural networks have achieved impressive success on various vision tasks, obvious performance degradation still exists when models are tested in out-of-distribution scenarios. In addressing this limitation, we ponder that the feature statistics (mean and standard deviation), which carry the domain characteristics of the training data, can be properly manipulated to improve the generalization ability of deep learning models. Existing methods commonly consider feature statistics as deterministic values measured from the learned features and do not explicitly model the uncertain statistics discrepancy caused by potential domain shifts during testing. In this paper, we improve the network generalization ability by modeling domain shifts with uncertainty (DSU), i.e., characterizing the feature statistics as uncertain distributions during training. Specifically, we hypothesize that the feature statistic, after considering the potential uncertainties, follows a multivariate Gaussian distribution. During inference, we propose an instance-wise adaptation strategy that can adaptively deal with the unforeseeable shift and further enhance the generalization ability of the trained model with negligible additional cost. We also conduct theoretical analysis on the aspects of generalization error bound and the implicit regularization effect, showing the efficacy of our method. Extensive experiments demonstrate that our method consistently improves the network generalization ability on multiple vision tasks, including image classification, semantic segmentation, instance retrieval, and pose estimation. Our methods are simple yet effective and can be readily integrated into networks without additional trainable parameters or loss constraints. Code will be released in https://github.com/lixiaotong97/DSU.
Switchable Representation Learning Framework with Self-compatibility
Jun 16, 2022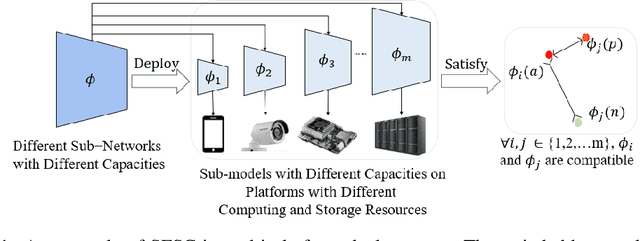

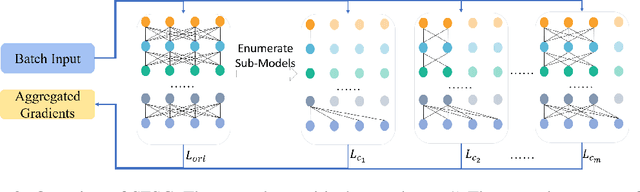
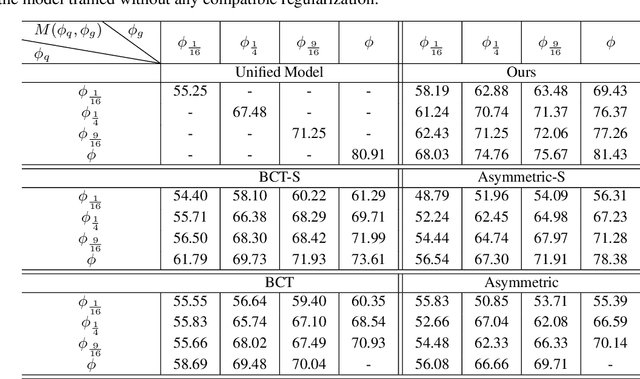
Real-world visual search systems involve deployments on multiple platforms with different computing and storage resources. Deploying a unified model that suits the minimal-constrain platforms leads to limited accuracy. It is expected to deploy models with different capacities adapting to the resource constraints, which requires features extracted by these models to be aligned in the metric space. The method to achieve feature alignments is called "compatible learning". Existing research mainly focuses on the one-to-one compatible paradigm, which is limited in learning compatibility among multiple models. We propose a Switchable representation learning Framework with Self-Compatibility (SFSC). SFSC generates a series of compatible sub-models with different capacities through one training process. The optimization of sub-models faces gradients conflict, and we mitigate it from the perspective of the magnitude and direction. We adjust the priorities of sub-models dynamically through uncertainty estimation to co-optimize sub-models properly. Besides, the gradients with conflicting directions are projected to avoid mutual interference. SFSC achieves state-of-art performance on the evaluated dataset.