 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA-Bench: Do Vision-Language Models Really Understand Visualized Text as Well as Pure Text?
Feb 04, 2026Vision-Language Models (VLMs) have achieved impressive performance in cross-modal understanding across textual and visual inputs, yet existing benchmarks predominantly focus on pure-text queries. In real-world scenarios, language also frequently appears as visualized text embedded in images, raising the question of whether current VLMs handle such input requests comparably. We introduce VISTA-Bench, a systematic benchmark from multimodal perception, reasoning, to unimodal understanding domains. It evaluates visualized text understanding by contrasting pure-text and visualized-text questions under controlled rendering conditions. Extensive evaluation of over 20 representative VLMs reveals a pronounced modality gap: models that perform well on pure-text queries often degrade substantially when equivalent semantic content is presented as visualized text. This gap is further amplified by increased perceptual difficulty, highlighting sensitivity to rendering variations despite unchanged semantics. Overall, VISTA-Bench provides a principled evaluation framework to diagnose this limitation and to guide progress toward more unified language representations across tokenized text and pixels. The source dataset is available at https://github.com/QingAnLiu/VISTA-Bench.
DynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation
Jan 29, 2026Manipulating dynamic objects remains an open challenge for Vision-Language-Action (VLA) models, which, despite strong generalization in static manipulation, struggle in dynamic scenarios requiring rapid perception, temporal anticipation, and continuous control. We present DynamicVLA, a framework for dynamic object manipulation that integrates temporal reasoning and closed-loop adaptation through three key designs: 1) a compact 0.4B VLA using a convolutional vision encoder for spatially efficient, structurally faithful encoding, enabling fast multimodal inference; 2) Continuous Inference, enabling overlapping reasoning and execution for lower latency and timely adaptation to object motion; and 3) Latent-aware Action Streaming, which bridges the perception-execution gap by enforcing temporally aligned action execution. To fill the missing foundation of dynamic manipulation data, we introduce the Dynamic Object Manipulation (DOM) benchmark, built from scratch with an auto data collection pipeline that efficiently gathers 200K synthetic episodes across 2.8K scenes and 206 objects, and enables fast collection of 2K real-world episodes without teleoperation. Extensive evaluations demonstrate remarkable improvements in response speed, perception, and generalization, positioning DynamicVLA as a unified framework for general dynamic object manipulation across embodiments.
The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding
Dec 22, 2025Deep representations across modalities are inherently intertwined. In this paper, we systematically analyze the spectral characteristics of various semantic and pixel encoders. Interestingly, our study uncovers a highly inspiring and rarely explored correspondence between an encoder's feature spectrum and its functional role: semantic encoders primarily capture low-frequency components that encode abstract meaning, whereas pixel encoders additionally retain high-frequency information that conveys fine-grained detail. This heuristic finding offers a unifying perspective that ties encoder behavior to its underlying spectral structure. We define it as the Prism Hypothesis, where each data modality can be viewed as a projection of the natural world onto a shared feature spectrum, just like the prism. Building on this insight, we propose Unified Autoencoding (UAE), a model that harmonizes semantic structure and pixel details via an innovative frequency-band modulator, enabling their seamless coexistence. Extensive experiments on ImageNet and MS-COCO benchmarks validate that our UAE effectively unifies semantic abstraction and pixel-level fidelity into a single latent space with state-of-the-art performance.
From Pixels to Words -- Towards Native Vision-Language Primitives at Scale
Oct 16, 2025The edifice of native Vision-Language Models (VLMs) has emerged as a rising contender to typical modular VLMs, shaped by evolving model architectures and training paradigms. Yet, two lingering clouds cast shadows over its widespread exploration and promotion: (-) What fundamental constraints set native VLMs apart from modular ones, and to what extent can these barriers be overcome? (-) How to make research in native VLMs more accessible and democratized, thereby accelerating progress in the field. In this paper, we clarify these challenges and outline guiding principles for constructing native VLMs. Specifically, one native VLM primitive should: (i) effectively align pixel and word representations within a shared semantic space; (ii) seamlessly integrate the strengths of formerly separate vision and language modules; (iii) inherently embody various cross-modal properties that support unified vision-language encoding, aligning, and reasoning. Hence, we launch NEO, a novel family of native VLMs built from first principles, capable of rivaling top-tier modular counterparts across diverse real-world scenarios. With only 390M image-text examples, NEO efficiently develops visual perception from scratch while mitigating vision-language conflicts inside a dense and monolithic model crafted from our elaborate primitives. We position NEO as a cornerstone for scalable and powerful native VLMs, paired with a rich set of reusable components that foster a cost-effective and extensible ecosystem. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.
Regularizing Subspace Redundancy of Low-Rank Adaptation
Jul 28, 2025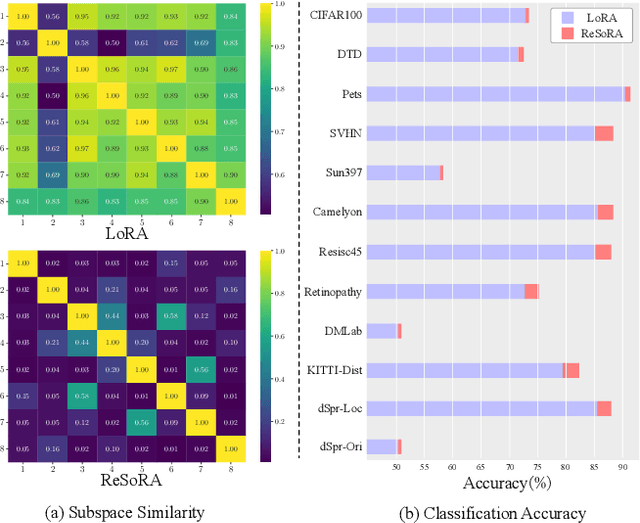
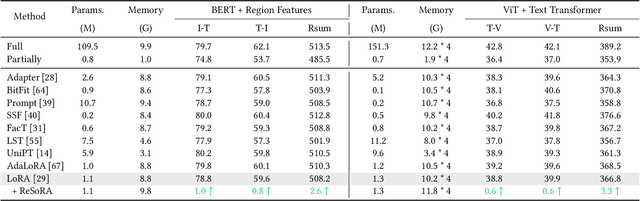
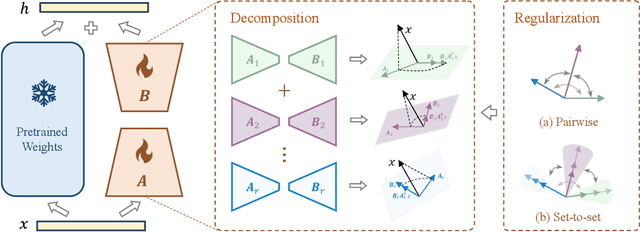
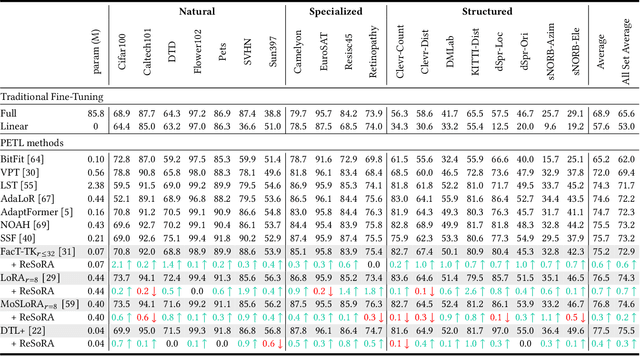
Low-Rank Adaptation (LoRA) and its variants have delivered strong capability in Parameter-Efficient Transfer Learning (PETL) by minimizing trainable parameters and benefiting from reparameterization. However, their projection matrices remain unrestricted during training, causing high representation redundancy and diminishing the effectiveness of feature adaptation in the resulting subspaces. While existing methods mitigate this by manually adjusting the rank or implicitly applying channel-wise masks, they lack flexibility and generalize poorly across various datasets and architectures. Hence, we propose ReSoRA, a method that explicitly models redundancy between mapping subspaces and adaptively Regularizes Subspace redundancy of Low-Rank Adaptation. Specifically, it theoretically decomposes the low-rank submatrices into multiple equivalent subspaces and systematically applies de-redundancy constraints to the feature distributions across different projections. Extensive experiments validate that our proposed method consistently facilitates existing state-of-the-art PETL methods across various backbones and datasets in vision-language retrieval and standard visual classification benchmarks. Besides, as a training supervision, ReSoRA can be seamlessly integrated into existing approaches in a plug-and-play manner, with no additional inference costs. Code is publicly available at: https://github.com/Lucenova/ReSoRA.
End-to-End Vision Tokenizer Tuning
May 15, 2025Existing vision tokenization isolates the optimization of vision tokenizers from downstream training, implicitly assuming the visual tokens can generalize well across various tasks, e.g., image generation and visual question answering. The vision tokenizer optimized for low-level reconstruction is agnostic to downstream tasks requiring varied representations and semantics. This decoupled paradigm introduces a critical misalignment: The loss of the vision tokenization can be the representation bottleneck for target tasks. For example, errors in tokenizing text in a given image lead to poor results when recognizing or generating them. To address this, we propose ETT, an end-to-end vision tokenizer tuning approach that enables joint optimization between vision tokenization and target autoregressive tasks. Unlike prior autoregressive models that use only discrete indices from a frozen vision tokenizer, ETT leverages the visual embeddings of the tokenizer codebook, and optimizes the vision tokenizers end-to-end with both reconstruction and caption objectives. ETT can be seamlessly integrated into existing training pipelines with minimal architecture modifications. Our ETT is simple to implement and integrate, without the need to adjust the original codebooks or architectures of the employed large language models. Extensive experiments demonstrate that our proposed end-to-end vision tokenizer tuning unlocks significant performance gains, i.e., 2-6% for multimodal understanding and visual generation tasks compared to frozen tokenizer baselines, while preserving the original reconstruction capability. We hope this very simple and strong method can empower multimodal foundation models besides image generation and understanding.
EVEv2: Improved Baselines for Encoder-Free Vision-Language Models
Feb 10, 2025



Existing encoder-free vision-language models (VLMs) are rapidly narrowing the performance gap with their encoder-based counterparts, highlighting the promising potential for unified multimodal systems with structural simplicity and efficient deployment. We systematically clarify the performance gap between VLMs using pre-trained vision encoders, discrete tokenizers, and minimalist visual layers from scratch, deeply excavating the under-examined characteristics of encoder-free VLMs. We develop efficient strategies for encoder-free VLMs that rival mainstream encoder-based ones. After an in-depth investigation, we launch EVEv2.0, a new and improved family of encoder-free VLMs. We show that: (i) Properly decomposing and hierarchically associating vision and language within a unified model reduces interference between modalities. (ii) A well-designed training strategy enables effective optimization for encoder-free VLMs. Through extensive evaluation, our EVEv2.0 represents a thorough study for developing a decoder-only architecture across modalities, demonstrating superior data efficiency and strong vision-reasoning capability. Code is publicly available at: https://github.com/baaivision/EVE.
KARST: Multi-Kernel Kronecker Adaptation with Re-Scaling Transmission for Visual Classification
Feb 10, 2025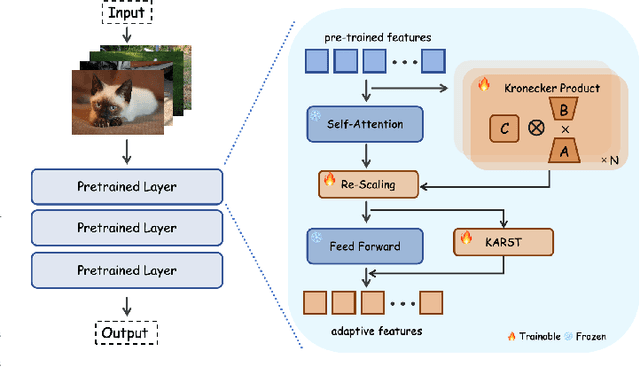
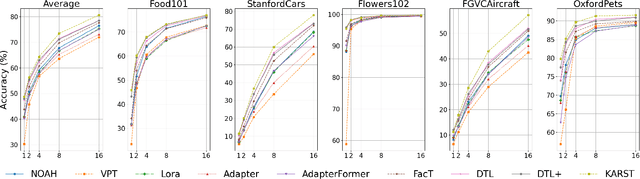
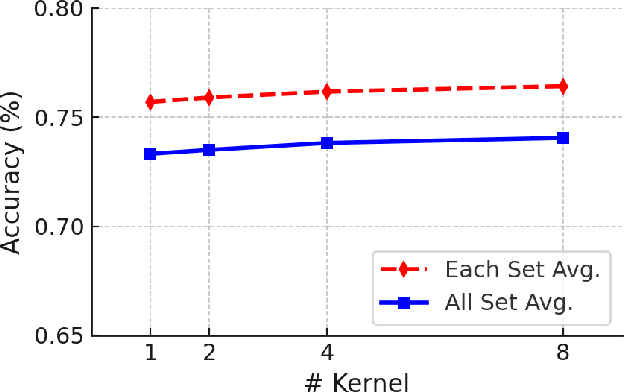
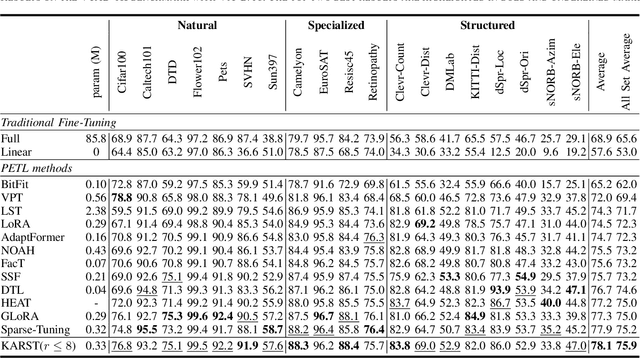
Fine-tuning pre-trained vision models for specific tasks is a common practice in computer vision. However, this process becomes more expensive as models grow larger. Recently, parameter-efficient fine-tuning (PEFT) methods have emerged as a popular solution to improve training efficiency and reduce storage needs by tuning additional low-rank modules within pre-trained backbones. Despite their advantages, they struggle with limited representation capabilities and misalignment with pre-trained intermediate features. To address these issues, we introduce an innovative Multi-Kernel Kronecker Adaptation with Re-Scaling Transmission (KARST) for various recognition tasks. Specifically, its multi-kernel design extends Kronecker projections horizontally and separates adaptation matrices into multiple complementary spaces, reducing parameter dependency and creating more compact subspaces. Besides, it incorporates extra learnable re-scaling factors to better align with pre-trained feature distributions, allowing for more flexible and balanced feature aggregation. Extensive experiments validate that our KARST outperforms other PEFT counterparts with a negligible inference cost due to its re-parameterization characteristics. Code is publicly available at: https://github.com/Lucenova/KARST.
Autoregressive Video Generation without Vector Quantization
Dec 18, 2024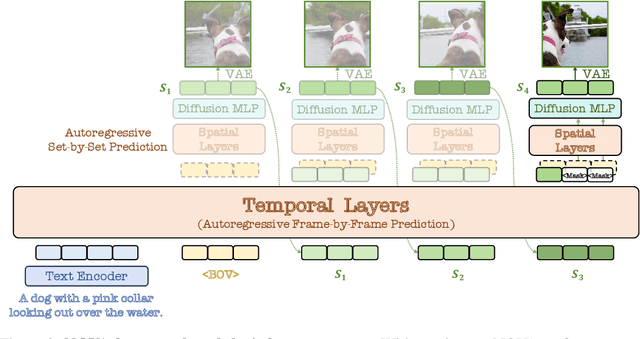
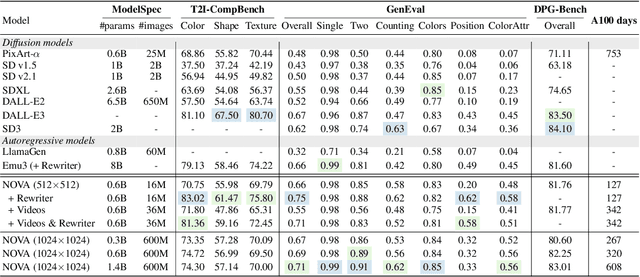
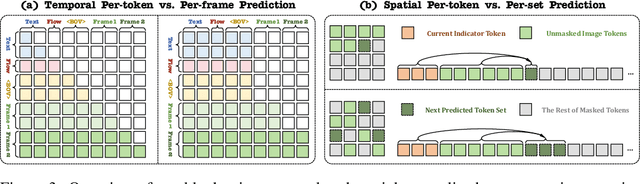
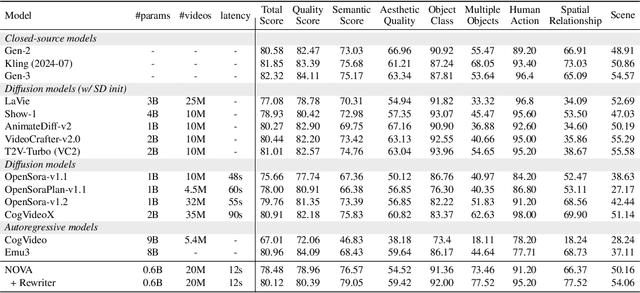
This paper presents a novel approach that enables autoregressive video generation with high efficiency. We propose to reformulate the video generation problem as a non-quantized autoregressive modeling of temporal frame-by-frame prediction and spatial set-by-set prediction. Unlike raster-scan prediction in prior autoregressive models or joint distribution modeling of fixed-length tokens in diffusion models, our approach maintains the causal property of GPT-style models for flexible in-context capabilities, while leveraging bidirectional modeling within individual frames for efficiency. With the proposed approach, we train a novel video autoregressive model without vector quantization, termed NOVA. Our results demonstrate that NOVA surpasses prior autoregressive video models in data efficiency, inference speed, visual fidelity, and video fluency, even with a much smaller model capacity, i.e., 0.6B parameters. NOVA also outperforms state-of-the-art image diffusion models in text-to-image generation tasks, with a significantly lower training cost. Additionally, NOVA generalizes well across extended video durations and enables diverse zero-shot applications in one unified model. Code and models are publicly available at https://github.com/baaivision/NOVA.
MoTrans: Customized Motion Transfer with Text-driven Video Diffusion Models
Dec 02, 2024



Existing pretrained text-to-video (T2V) models have demonstrated impressive abilities in generating realistic videos with basic motion or camera movement. However, these models exhibit significant limitations when generating intricate, human-centric motions. Current efforts primarily focus on fine-tuning models on a small set of videos containing a specific motion. They often fail to effectively decouple motion and the appearance in the limited reference videos, thereby weakening the modeling capability of motion patterns. To this end, we propose MoTrans, a customized motion transfer method enabling video generation of similar motion in new context. Specifically, we introduce a multimodal large language model (MLLM)-based recaptioner to expand the initial prompt to focus more on appearance and an appearance injection module to adapt appearance prior from video frames to the motion modeling process. These complementary multimodal representations from recaptioned prompt and video frames promote the modeling of appearance and facilitate the decoupling of appearance and motion. In addition, we devise a motion-specific embedding for further enhancing the modeling of the specific motion. Experimental results demonstrate that our method effectively learns specific motion pattern from singular or multiple reference videos, performing favorably against existing methods in customized video generation.