 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA-Bench: Do Vision-Language Models Really Understand Visualized Text as Well as Pure Text?
Feb 04, 2026Vision-Language Models (VLMs) have achieved impressive performance in cross-modal understanding across textual and visual inputs, yet existing benchmarks predominantly focus on pure-text queries. In real-world scenarios, language also frequently appears as visualized text embedded in images, raising the question of whether current VLMs handle such input requests comparably. We introduce VISTA-Bench, a systematic benchmark from multimodal perception, reasoning, to unimodal understanding domains. It evaluates visualized text understanding by contrasting pure-text and visualized-text questions under controlled rendering conditions. Extensive evaluation of over 20 representative VLMs reveals a pronounced modality gap: models that perform well on pure-text queries often degrade substantially when equivalent semantic content is presented as visualized text. This gap is further amplified by increased perceptual difficulty, highlighting sensitivity to rendering variations despite unchanged semantics. Overall, VISTA-Bench provides a principled evaluation framework to diagnose this limitation and to guide progress toward more unified language representations across tokenized text and pixels. The source dataset is available at https://github.com/QingAnLiu/VISTA-Bench.
Towards Cross-Platform Generalization: Domain Adaptive 3D Detection with Augmentation and Pseudo-Labeling
Jan 13, 2026This technical report represents the award-winning solution to the Cross-platform 3D Object Detection task in the RoboSense2025 Challenge. Our approach is built upon PVRCNN++, an efficient 3D object detection framework that effectively integrates point-based and voxel-based features. On top of this foundation, we improve cross-platform generalization by narrowing domain gaps through tailored data augmentation and a self-training strategy with pseudo-labels. These enhancements enabled our approach to secure the 3rd place in the challenge, achieving a 3D AP of 62.67% for the Car category on the phase-1 target domain, and 58.76% and 49.81% for Car and Pedestrian categories respectively on the phase-2 target domain.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Parameter Aware Mamba Model for Multi-task Dense Prediction
Nov 18, 2025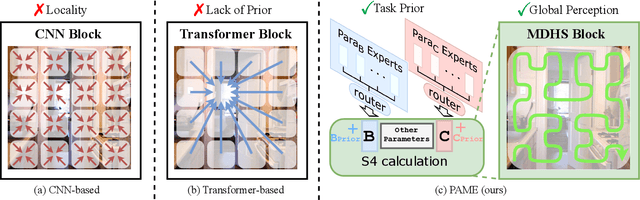
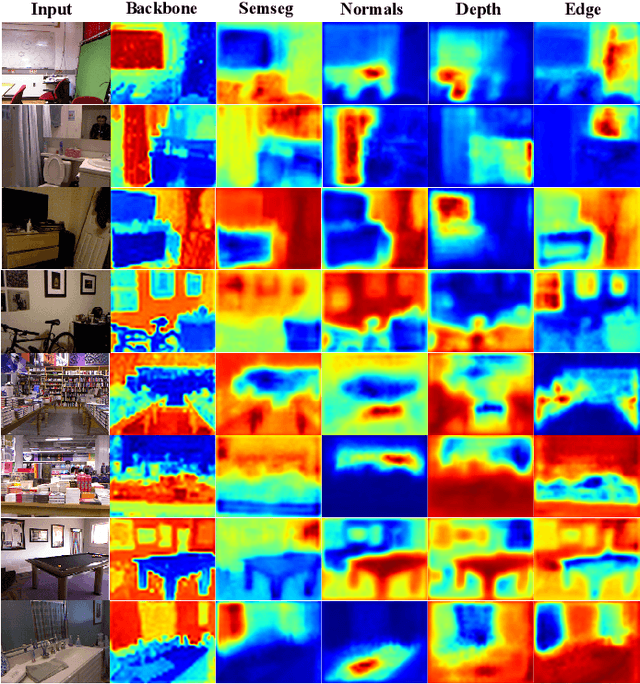
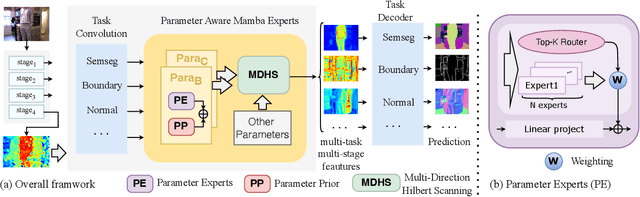
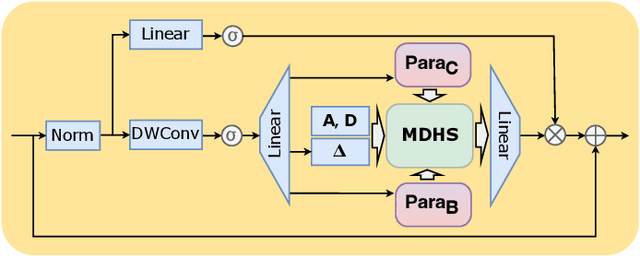
Understanding the inter-relations and interactions between tasks is crucial for multi-task dense prediction. Existing methods predominantly utilize convolutional layers and attention mechanisms to explore task-level interactions. In this work, we introduce a novel decoder-based framework, Parameter Aware Mamba Model (PAMM), specifically designed for dense prediction in multi-task learning setting. Distinct from approaches that employ Transformers to model holistic task relationships, PAMM leverages the rich, scalable parameters of state space models to enhance task interconnectivity. It features dual state space parameter experts that integrate and set task-specific parameter priors, capturing the intrinsic properties of each task. This approach not only facilitates precise multi-task interactions but also allows for the global integration of task priors through the structured state space sequence model (S4). Furthermore, we employ the Multi-Directional Hilbert Scanning method to construct multi-angle feature sequences, thereby enhancing the sequence model's perceptual capabilities for 2D data. Extensive experiments on the NYUD-v2 and PASCAL-Context benchmarks demonstrate the effectiveness of our proposed method. Our code is available at https://github.com/CQC-gogopro/PAMM.
VFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
Oct 29, 2025Visual effects (VFX) are crucial to the expressive power of digital media, yet their creation remains a major challenge for generative AI. Prevailing methods often rely on the one-LoRA-per-effect paradigm, which is resource-intensive and fundamentally incapable of generalizing to unseen effects, thus limiting scalability and creation. To address this challenge, we introduce VFXMaster, the first unified, reference-based framework for VFX video generation. It recasts effect generation as an in-context learning task, enabling it to reproduce diverse dynamic effects from a reference video onto target content. In addition, it demonstrates remarkable generalization to unseen effect categories. Specifically, we design an in-context conditioning strategy that prompts the model with a reference example. An in-context attention mask is designed to precisely decouple and inject the essential effect attributes, allowing a single unified model to master the effect imitation without information leakage. In addition, we propose an efficient one-shot effect adaptation mechanism to boost generalization capability on tough unseen effects from a single user-provided video rapidly. Extensive experiments demonstrate that our method effectively imitates various categories of effect information and exhibits outstanding generalization to out-of-domain effects. To foster future research, we will release our code, models, and a comprehensive dataset to the community.
Regularizing Subspace Redundancy of Low-Rank Adaptation
Jul 28, 2025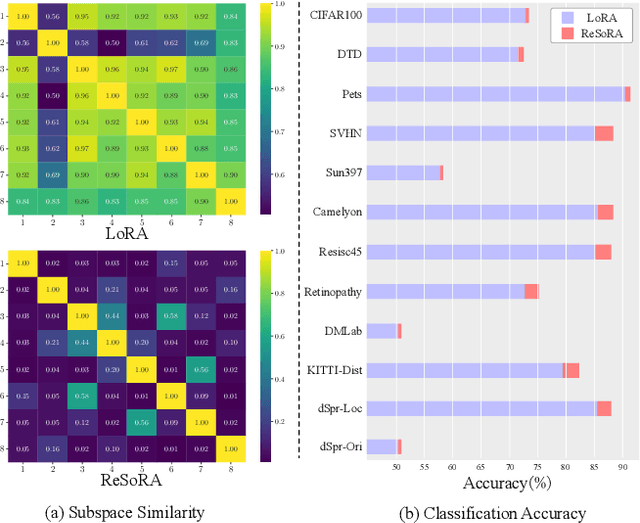
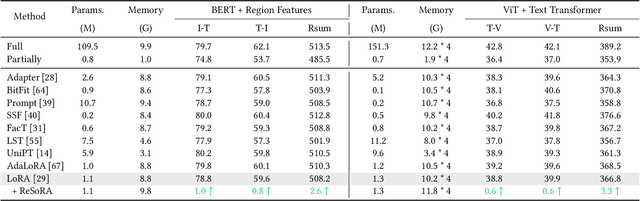
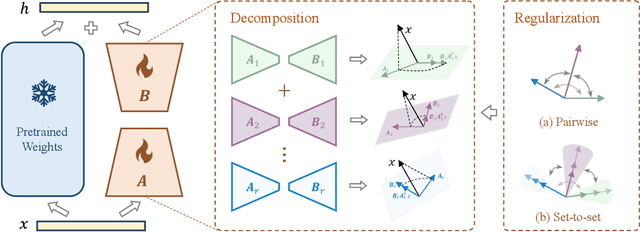
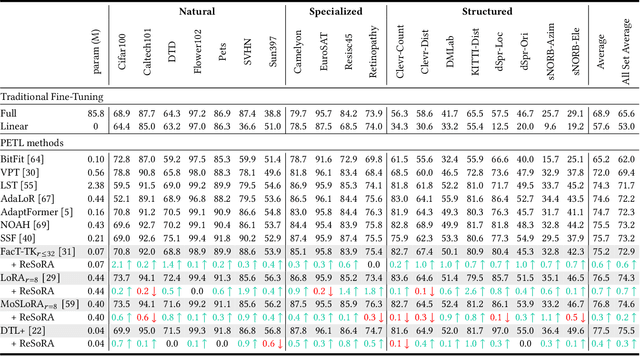
Low-Rank Adaptation (LoRA) and its variants have delivered strong capability in Parameter-Efficient Transfer Learning (PETL) by minimizing trainable parameters and benefiting from reparameterization. However, their projection matrices remain unrestricted during training, causing high representation redundancy and diminishing the effectiveness of feature adaptation in the resulting subspaces. While existing methods mitigate this by manually adjusting the rank or implicitly applying channel-wise masks, they lack flexibility and generalize poorly across various datasets and architectures. Hence, we propose ReSoRA, a method that explicitly models redundancy between mapping subspaces and adaptively Regularizes Subspace redundancy of Low-Rank Adaptation. Specifically, it theoretically decomposes the low-rank submatrices into multiple equivalent subspaces and systematically applies de-redundancy constraints to the feature distributions across different projections. Extensive experiments validate that our proposed method consistently facilitates existing state-of-the-art PETL methods across various backbones and datasets in vision-language retrieval and standard visual classification benchmarks. Besides, as a training supervision, ReSoRA can be seamlessly integrated into existing approaches in a plug-and-play manner, with no additional inference costs. Code is publicly available at: https://github.com/Lucenova/ReSoRA.
Learning Universal Features for Generalizable Image Forgery Localization
Apr 10, 2025In recent years, advanced image editing and generation methods have rapidly evolved, making detecting and locating forged image content increasingly challenging. Most existing image forgery detection methods rely on identifying the edited traces left in the image. However, because the traces of different forgeries are distinct, these methods can identify familiar forgeries included in the training data but struggle to handle unseen ones. In response, we present an approach for Generalizable Image Forgery Localization (GIFL). Once trained, our model can detect both seen and unseen forgeries, providing a more practical and efficient solution to counter false information in the era of generative AI. Our method focuses on learning general features from the pristine content rather than traces of specific forgeries, which are relatively consistent across different types of forgeries and therefore can be used as universal features to locate unseen forgeries. Additionally, as existing image forgery datasets are still dominated by traditional hand-crafted forgeries, we construct a new dataset consisting of images edited by various popular deep generative image editing methods to further encourage research in detecting images manipulated by deep generative models. Extensive experimental results show that the proposed approach outperforms state-of-the-art methods in the detection of unseen forgeries and also demonstrates competitive results for seen forgeries. The code and dataset are available at https://github.com/ZhaoHengrun/GIFL.
The Devil is in Temporal Token: High Quality Video Reasoning Segmentation
Jan 15, 2025



Existing methods for Video Reasoning Segmentation rely heavily on a single special token to represent the object in the keyframe or the entire video, inadequately capturing spatial complexity and inter-frame motion. To overcome these challenges, we propose VRS-HQ, an end-to-end video reasoning segmentation approach that leverages Multimodal Large Language Models (MLLMs) to inject rich spatiotemporal features into hierarchical tokens.Our key innovations include a Temporal Dynamic Aggregation (TDA) and a Token-driven Keyframe Selection (TKS). Specifically, we design frame-level <SEG> and temporal-level <TAK> tokens that utilize MLLM's autoregressive learning to effectively capture both local and global information. Subsequently, we apply a similarity-based weighted fusion and frame selection strategy, then utilize SAM2 to perform keyframe segmentation and propagation. To enhance keyframe localization accuracy, the TKS filters keyframes based on SAM2's occlusion scores during inference. VRS-HQ achieves state-of-the-art performance on ReVOS, surpassing VISA by 5.9%/12.5%/9.1% in J&F scores across the three subsets. These results highlight the strong temporal reasoning and segmentation capabilities of our method. Code and model weights will be released at VRS-HQ.
AVS-Mamba: Exploring Temporal and Multi-modal Mamba for Audio-Visual Segmentation
Jan 14, 2025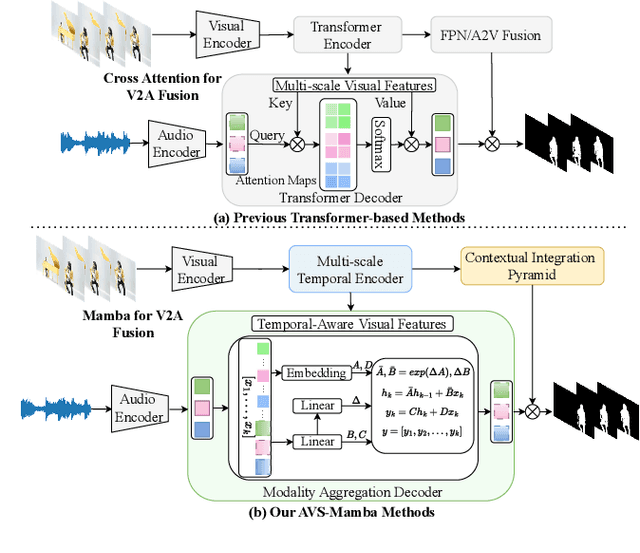

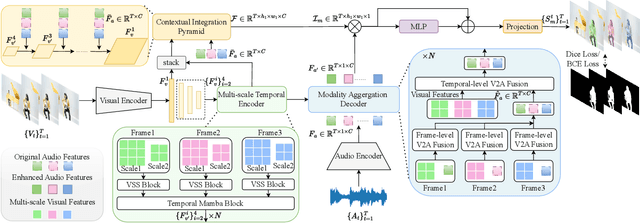
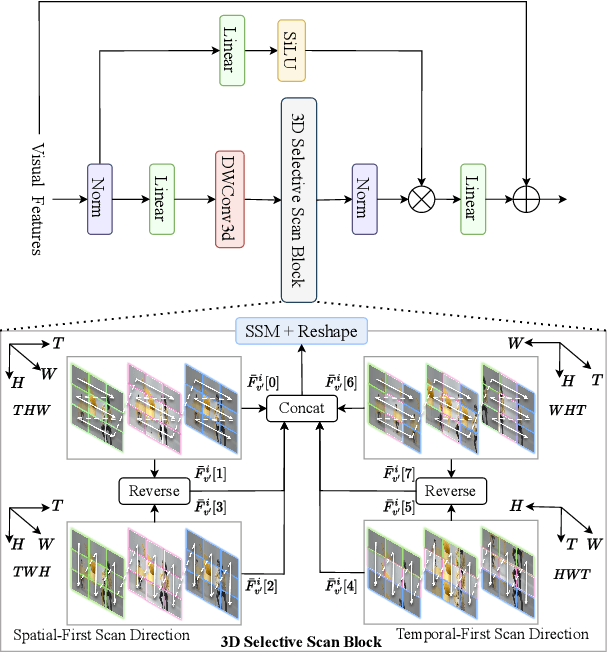
The essence of audio-visual segmentation (AVS) lies in locating and delineating sound-emitting objects within a video stream. While Transformer-based methods have shown promise, their handling of long-range dependencies struggles due to quadratic computational costs, presenting a bottleneck in complex scenarios. To overcome this limitation and facilitate complex multi-modal comprehension with linear complexity, we introduce AVS-Mamba, a selective state space model to address the AVS task. Our framework incorporates two key components for video understanding and cross-modal learning: Temporal Mamba Block for sequential video processing and Vision-to-Audio Fusion Block for advanced audio-vision integration. Building on this, we develop the Multi-scale Temporal Encoder, aimed at enhancing the learning of visual features across scales, facilitating the perception of intra- and inter-frame information. To perform multi-modal fusion, we propose the Modality Aggregation Decoder, leveraging the Vision-to-Audio Fusion Block to integrate visual features into audio features across both frame and temporal levels. Further, we adopt the Contextual Integration Pyramid to perform audio-to-vision spatial-temporal context collaboration. Through these innovative contributions, our approach achieves new state-of-the-art results on the AVSBench-object and AVSBench-semantic datasets. Our source code and model weights are available at AVS-Mamba.
Learning Motion and Temporal Cues for Unsupervised Video Object Segmentation
Jan 14, 2025



In this paper, we address the challenges in unsupervised video object segmentation (UVOS) by proposing an efficient algorithm, termed MTNet, which concurrently exploits motion and temporal cues. Unlike previous methods that focus solely on integrating appearance with motion or on modeling temporal relations, our method combines both aspects by integrating them within a unified framework. MTNet is devised by effectively merging appearance and motion features during the feature extraction process within encoders, promoting a more complementary representation. To capture the intricate long-range contextual dynamics and information embedded within videos, a temporal transformer module is introduced, facilitating efficacious inter-frame interactions throughout a video clip. Furthermore, we employ a cascade of decoders all feature levels across all feature levels to optimally exploit the derived features, aiming to generate increasingly precise segmentation masks. As a result, MTNet provides a strong and compact framework that explores both temporal and cross-modality knowledge to robustly localize and track the primary object accurately in various challenging scenarios efficiently. Extensive experiments across diverse benchmarks conclusively show that our method not only attains state-of-the-art performance in unsupervised video object segmentation but also delivers competitive results in video salient object detection. These findings highlight the method's robust versatility and its adeptness in adapting to a range of segmentation tasks. Source code is available on https://github.com/hy0523/MTNet.