 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Motion and Temporal Cues for Unsupervised Video Object Segmentation
Jan 14, 2025



In this paper, we address the challenges in unsupervised video object segmentation (UVOS) by proposing an efficient algorithm, termed MTNet, which concurrently exploits motion and temporal cues. Unlike previous methods that focus solely on integrating appearance with motion or on modeling temporal relations, our method combines both aspects by integrating them within a unified framework. MTNet is devised by effectively merging appearance and motion features during the feature extraction process within encoders, promoting a more complementary representation. To capture the intricate long-range contextual dynamics and information embedded within videos, a temporal transformer module is introduced, facilitating efficacious inter-frame interactions throughout a video clip. Furthermore, we employ a cascade of decoders all feature levels across all feature levels to optimally exploit the derived features, aiming to generate increasingly precise segmentation masks. As a result, MTNet provides a strong and compact framework that explores both temporal and cross-modality knowledge to robustly localize and track the primary object accurately in various challenging scenarios efficiently. Extensive experiments across diverse benchmarks conclusively show that our method not only attains state-of-the-art performance in unsupervised video object segmentation but also delivers competitive results in video salient object detection. These findings highlight the method's robust versatility and its adeptness in adapting to a range of segmentation tasks. Source code is available on https://github.com/hy0523/MTNet.
Hybrid-SORT: Weak Cues Matter for Online Multi-Object Tracking
Aug 01, 2023Multi-Object Tracking (MOT) aims to detect and associate all desired objects across frames. Most methods accomplish the task by explicitly or implicitly leveraging strong cues (i.e., spatial and appearance information), which exhibit powerful instance-level discrimination. However, when object occlusion and clustering occur, both spatial and appearance information will become ambiguous simultaneously due to the high overlap between objects. In this paper, we demonstrate that this long-standing challenge in MOT can be efficiently and effectively resolved by incorporating weak cues to compensate for strong cues. Along with velocity direction, we introduce the confidence state and height state as potential weak cues. With superior performance, our method still maintains Simple, Online and Real-Time (SORT) characteristics. Furthermore, our method shows strong generalization for diverse trackers and scenarios in a plug-and-play and training-free manner. Significant and consistent improvements are observed when applying our method to 5 different representative trackers. Further, by leveraging both strong and weak cues, our method Hybrid-SORT achieves superior performance on diverse benchmarks, including MOT17, MOT20, and especially DanceTrack where interaction and occlusion are frequent and severe. The code and models are available at https://github.com/ymzis69/HybirdSORT.
Few-Shot Segmentation via Rich Prototype Generation and Recurrent Prediction Enhancement
Oct 03, 2022

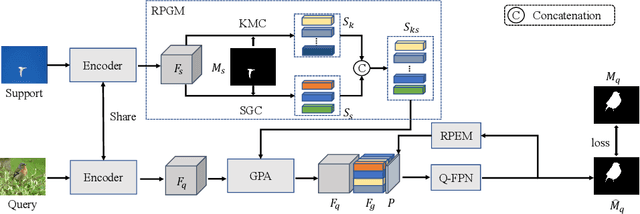

Prototype learning and decoder construction are the keys for few-shot segmentation. However, existing methods use only a single prototype generation mode, which can not cope with the intractable problem of objects with various scales. Moreover, the one-way forward propagation adopted by previous methods may cause information dilution from registered features during the decoding process. In this research, we propose a rich prototype generation module (RPGM) and a recurrent prediction enhancement module (RPEM) to reinforce the prototype learning paradigm and build a unified memory-augmented decoder for few-shot segmentation, respectively. Specifically, the RPGM combines superpixel and K-means clustering to generate rich prototype features with complementary scale relationships and adapt the scale gap between support and query images. The RPEM utilizes the recurrent mechanism to design a round-way propagation decoder. In this way, registered features can provide object-aware information continuously. Experiments show that our method consistently outperforms other competitors on two popular benchmarks PASCAL-${{5}^{i}}$ and COCO-${{20}^{i}}$.
HAT: Hierarchical Aggregation Transformers for Person Re-identification
Jul 14, 2021
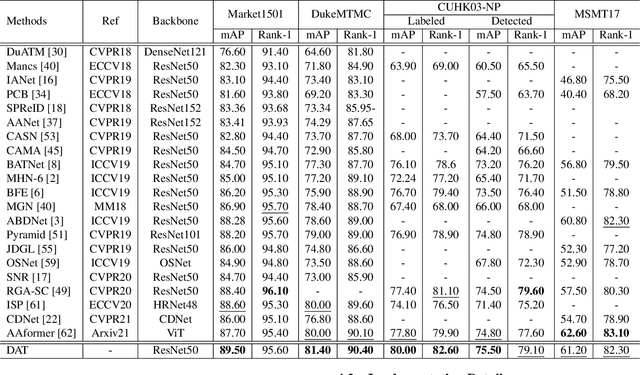
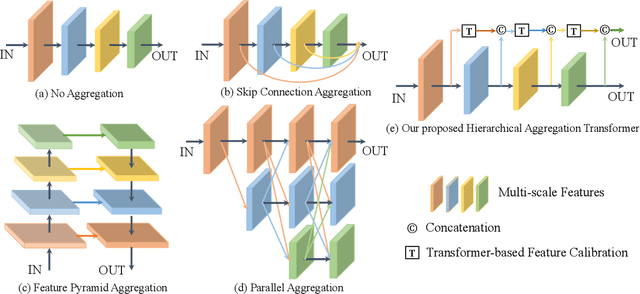

Recently, with the advance of deep Convolutional Neural Networks (CNNs), person Re-Identification (Re-ID) has witnessed great success in various applications. However, with limited receptive fields of CNNs, it is still challenging to extract discriminative representations in a global view for persons under non-overlapped cameras. Meanwhile, Transformers demonstrate strong abilities of modeling long-range dependencies for spatial and sequential data. In this work, we take advantages of both CNNs and Transformers, and propose a novel learning framework named Hierarchical Aggregation Transformer (HAT) for image-based person Re-ID with high performance. To achieve this goal, we first propose a Deeply Supervised Aggregation (DSA) to recurrently aggregate hierarchical features from CNN backbones. With multi-granularity supervisions, the DSA can enhance multi-scale features for person retrieval, which is very different from previous methods. Then, we introduce a Transformer-based Feature Calibration (TFC) to integrate low-level detail information as the global prior for high-level semantic information. The proposed TFC is inserted to each level of hierarchical features, resulting in great performance improvements. To our best knowledge, this work is the first to take advantages of both CNNs and Transformers for image-based person Re-ID. Comprehensive experiments on four large-scale Re-ID benchmarks demonstrate that our method shows better results than several state-of-the-art methods. The code is released at https://github.com/AI-Zhpp/HAT.
Coherent Loss: A Generic Framework for Stable Video Segmentation
Oct 25, 2020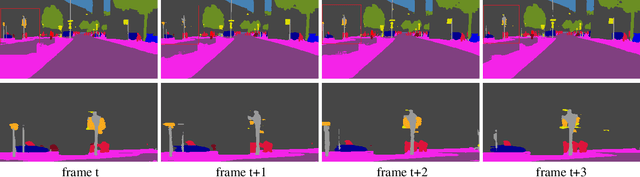

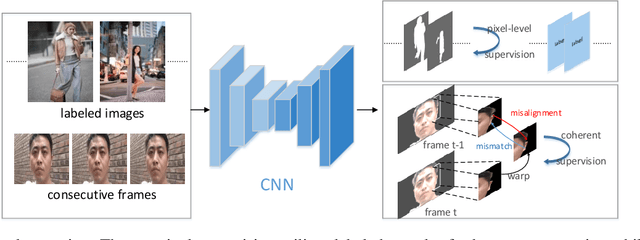
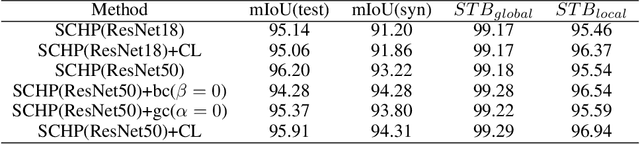
Video segmentation approaches are of great importance for numerous vision tasks especially in video manipulation for entertainment. Due to the challenges associated with acquiring high-quality per-frame segmentation annotations and large video datasets with different environments at scale, learning approaches shows overall higher accuracy on test dataset but lack strict temporal constraints to self-correct jittering artifacts in most practical applications. We investigate how this jittering artifact degrades the visual quality of video segmentation results and proposed a metric of temporal stability to numerically evaluate it. In particular, we propose a Coherent Loss with a generic framework to enhance the performance of a neural network against jittering artifacts, which combines with high accuracy and high consistency. Equipped with our method, existing video object/semantic segmentation approaches achieve a significant improvement in term of more satisfactory visual quality on video human dataset, which we provide for further research in this field, and also on DAVIS and Cityscape.
Learning regression and verification networks for long-term visual tracking
Sep 12, 2018
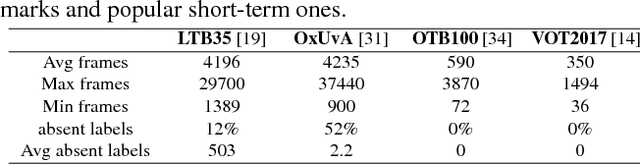
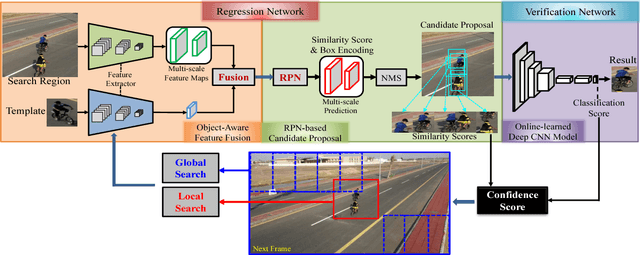
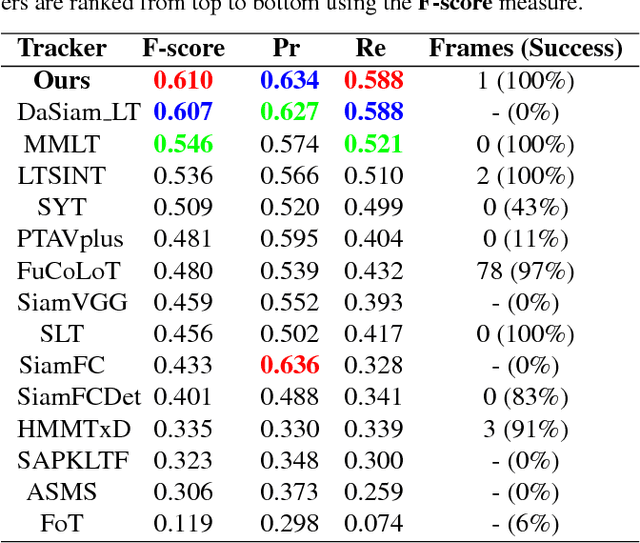
In the long-term single object tracking task, the target moves out of view frequently. It is difficult to determine the presence of the target and re-search the target in the entire image. In this paper, we circumvent this issue by introducing a collaborative framework that exploits both matching mechanism and discriminative features to account for target identification and image-wide re-detection. Within the proposed collaborative framework, we develop a matching based regression module and a classification based verification module for long-term visual tracking. In the regression module, we present a regressor that conducts matching learning and copes with drastic appearance changes. In the verification module, we propose a classifier that filters out distractions efficiently. Compared to previous long-term trackers, the proposed tracker is able to track the target object more robustly in long-term sequences. Extensive experiments show that our algorithm achieves state-of-the-art results on several datasets.