 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenVE-3M: A Large-Scale High-Quality Dataset for Instruction-Guided Video Editing
Dec 16, 2025The quality and diversity of instruction-based image editing datasets are continuously increasing, yet large-scale, high-quality datasets for instruction-based video editing remain scarce. To address this gap, we introduce OpenVE-3M, an open-source, large-scale, and high-quality dataset for instruction-based video editing. It comprises two primary categories: spatially-aligned edits (Global Style, Background Change, Local Change, Local Remove, Local Add, and Subtitles Edit) and non-spatially-aligned edits (Camera Multi-Shot Edit and Creative Edit). All edit types are generated via a meticulously designed data pipeline with rigorous quality filtering. OpenVE-3M surpasses existing open-source datasets in terms of scale, diversity of edit types, instruction length, and overall quality. Furthermore, to address the lack of a unified benchmark in the field, we construct OpenVE-Bench, containing 431 video-edit pairs that cover a diverse range of editing tasks with three key metrics highly aligned with human judgment. We present OpenVE-Edit, a 5B model trained on our dataset that demonstrates remarkable efficiency and effectiveness by setting a new state-of-the-art on OpenVE-Bench, outperforming all prior open-source models including a 14B baseline. Project page is at https://lewandofskee.github.io/projects/OpenVE.
JoVA: Unified Multimodal Learning for Joint Video-Audio Generation
Dec 15, 2025In this paper, we present JoVA, a unified framework for joint video-audio generation. Despite recent encouraging advances, existing methods face two critical limitations. First, most existing approaches can only generate ambient sounds and lack the capability to produce human speech synchronized with lip movements. Second, recent attempts at unified human video-audio generation typically rely on explicit fusion or modality-specific alignment modules, which introduce additional architecture design and weaken the model simplicity of the original transformers. To address these issues, JoVA employs joint self-attention across video and audio tokens within each transformer layer, enabling direct and efficient cross-modal interaction without the need for additional alignment modules. Furthermore, to enable high-quality lip-speech synchronization, we introduce a simple yet effective mouth-area loss based on facial keypoint detection, which enhances supervision on the critical mouth region during training without compromising architectural simplicity. Extensive experiments on benchmarks demonstrate that JoVA outperforms or is competitive with both unified and audio-driven state-of-the-art methods in lip-sync accuracy, speech quality, and overall video-audio generation fidelity. Our results establish JoVA as an elegant framework for high-quality multimodal generation.
Discriminator-Free Direct Preference Optimization for Video Diffusion
Apr 11, 2025Direct Preference Optimization (DPO), which aligns models with human preferences through win/lose data pairs, has achieved remarkable success in language and image generation. However, applying DPO to video diffusion models faces critical challenges: (1) Data inefficiency. Generating thousands of videos per DPO iteration incurs prohibitive costs; (2) Evaluation uncertainty. Human annotations suffer from subjective bias, and automated discriminators fail to detect subtle temporal artifacts like flickering or motion incoherence. To address these, we propose a discriminator-free video DPO framework that: (1) Uses original real videos as win cases and their edited versions (e.g., reversed, shuffled, or noise-corrupted clips) as lose cases; (2) Trains video diffusion models to distinguish and avoid artifacts introduced by editing. This approach eliminates the need for costly synthetic video comparisons, provides unambiguous quality signals, and enables unlimited training data expansion through simple editing operations. We theoretically prove the framework's effectiveness even when real videos and model-generated videos follow different distributions. Experiments on CogVideoX demonstrate the efficiency of the proposed method.
AffineQuant: Affine Transformation Quantization for Large Language Models
Mar 19, 2024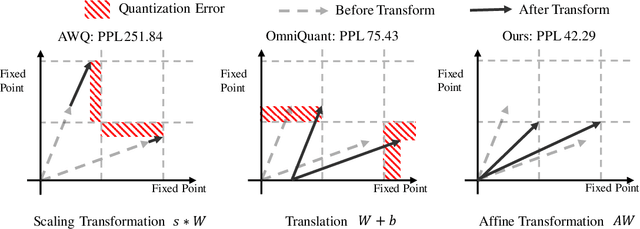
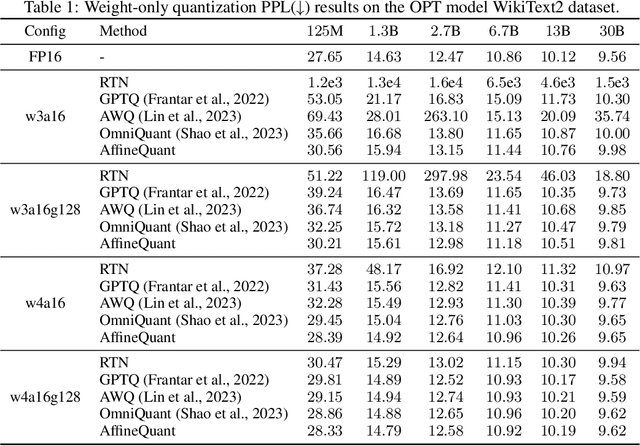
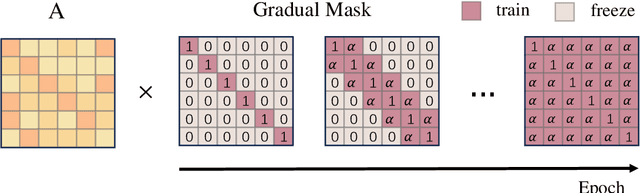
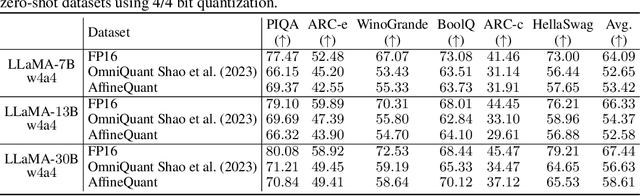
The significant resource requirements associated with Large-scale Language Models (LLMs) have generated considerable interest in the development of techniques aimed at compressing and accelerating neural networks. Among these techniques, Post-Training Quantization (PTQ) has emerged as a subject of considerable interest due to its noteworthy compression efficiency and cost-effectiveness in the context of training. Existing PTQ methods for LLMs limit the optimization scope to scaling transformations between pre- and post-quantization weights. In this paper, we advocate for the direct optimization using equivalent Affine transformations in PTQ (AffineQuant). This approach extends the optimization scope and thus significantly minimizing quantization errors. Additionally, by employing the corresponding inverse matrix, we can ensure equivalence between the pre- and post-quantization outputs of PTQ, thereby maintaining its efficiency and generalization capabilities. To ensure the invertibility of the transformation during optimization, we further introduce a gradual mask optimization method. This method initially focuses on optimizing the diagonal elements and gradually extends to the other elements. Such an approach aligns with the Levy-Desplanques theorem, theoretically ensuring invertibility of the transformation. As a result, significant performance improvements are evident across different LLMs on diverse datasets. To illustrate, we attain a C4 perplexity of 15.76 (2.26 lower vs 18.02 in OmniQuant) on the LLaMA2-7B model of W4A4 quantization without overhead. On zero-shot tasks, AffineQuant achieves an average of 58.61 accuracy (1.98 lower vs 56.63 in OmniQuant) when using 4/4-bit quantization for LLaMA-30B, which setting a new state-of-the-art benchmark for PTQ in LLMs.
DiffusionGPT: LLM-Driven Text-to-Image Generation System
Jan 18, 2024Diffusion models have opened up new avenues for the field of image generation, resulting in the proliferation of high-quality models shared on open-source platforms. However, a major challenge persists in current text-to-image systems are often unable to handle diverse inputs, or are limited to single model results. Current unified attempts often fall into two orthogonal aspects: i) parse Diverse Prompts in input stage; ii) activate expert model to output. To combine the best of both worlds, we propose DiffusionGPT, which leverages Large Language Models (LLM) to offer a unified generation system capable of seamlessly accommodating various types of prompts and integrating domain-expert models. DiffusionGPT constructs domain-specific Trees for various generative models based on prior knowledge. When provided with an input, the LLM parses the prompt and employs the Trees-of-Thought to guide the selection of an appropriate model, thereby relaxing input constraints and ensuring exceptional performance across diverse domains. Moreover, we introduce Advantage Databases, where the Tree-of-Thought is enriched with human feedback, aligning the model selection process with human preferences. Through extensive experiments and comparisons, we demonstrate the effectiveness of DiffusionGPT, showcasing its potential for pushing the boundaries of image synthesis in diverse domains.
MeMaHand: Exploiting Mesh-Mano Interaction for Single Image Two-Hand Reconstruction
Apr 17, 2023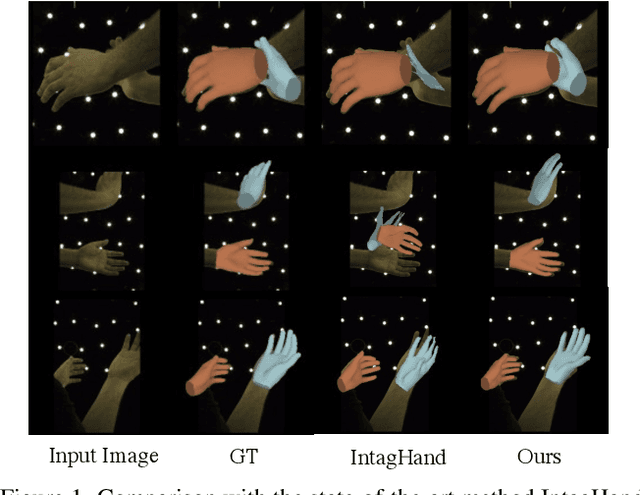

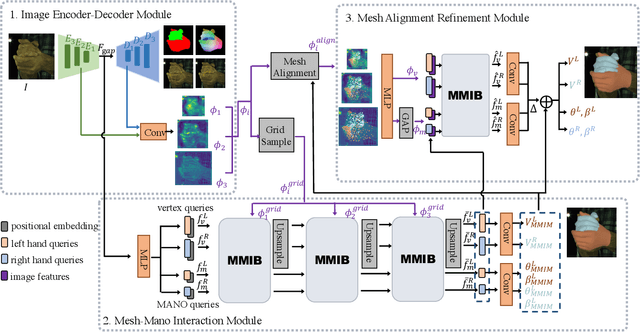

Existing methods proposed for hand reconstruction tasks usually parameterize a generic 3D hand model or predict hand mesh positions directly. The parametric representations consisting of hand shapes and rotational poses are more stable, while the non-parametric methods can predict more accurate mesh positions. In this paper, we propose to reconstruct meshes and estimate MANO parameters of two hands from a single RGB image simultaneously to utilize the merits of two kinds of hand representations. To fulfill this target, we propose novel Mesh-Mano interaction blocks (MMIBs), which take mesh vertices positions and MANO parameters as two kinds of query tokens. MMIB consists of one graph residual block to aggregate local information and two transformer encoders to model long-range dependencies. The transformer encoders are equipped with different asymmetric attention masks to model the intra-hand and inter-hand attention, respectively. Moreover, we introduce the mesh alignment refinement module to further enhance the mesh-image alignment. Extensive experiments on the InterHand2.6M benchmark demonstrate promising results over the state-of-the-art hand reconstruction methods.
Solving Oscillation Problem in Post-Training Quantization Through a Theoretical Perspective
Apr 04, 2023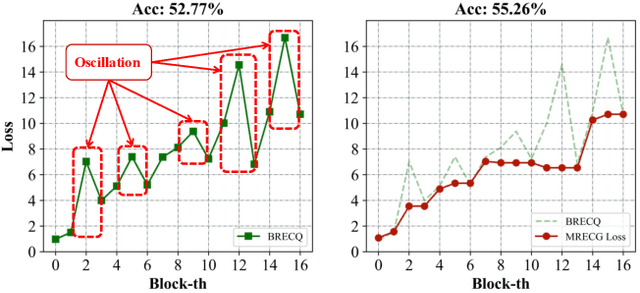
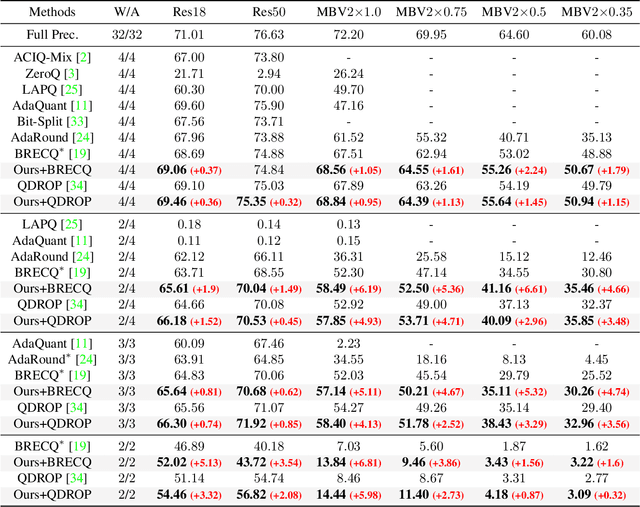
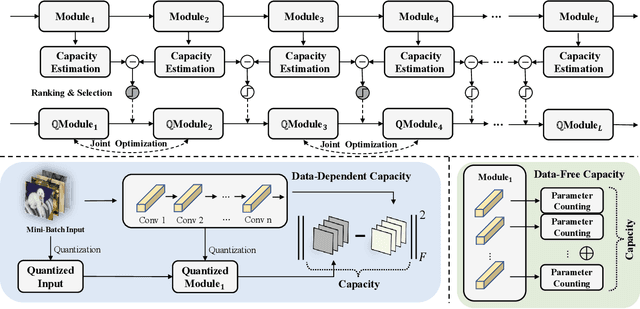
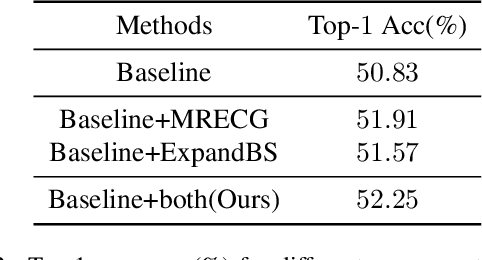
Post-training quantization (PTQ) is widely regarded as one of the most efficient compression methods practically, benefitting from its data privacy and low computation costs. We argue that an overlooked problem of oscillation is in the PTQ methods. In this paper, we take the initiative to explore and present a theoretical proof to explain why such a problem is essential in PTQ. And then, we try to solve this problem by introducing a principled and generalized framework theoretically. In particular, we first formulate the oscillation in PTQ and prove the problem is caused by the difference in module capacity. To this end, we define the module capacity (ModCap) under data-dependent and data-free scenarios, where the differentials between adjacent modules are used to measure the degree of oscillation. The problem is then solved by selecting top-k differentials, in which the corresponding modules are jointly optimized and quantized. Extensive experiments demonstrate that our method successfully reduces the performance drop and is generalized to different neural networks and PTQ methods. For example, with 2/4 bit ResNet-50 quantization, our method surpasses the previous state-of-the-art method by 1.9%. It becomes more significant on small model quantization, e.g. surpasses BRECQ method by 6.61% on MobileNetV2*0.5.
FreeSeg: Unified, Universal and Open-Vocabulary Image Segmentation
Mar 30, 2023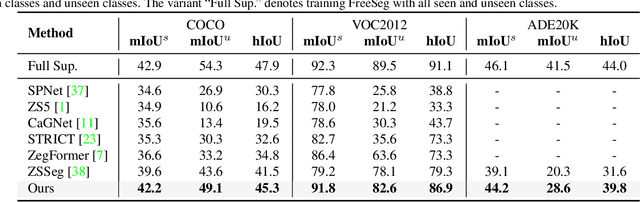
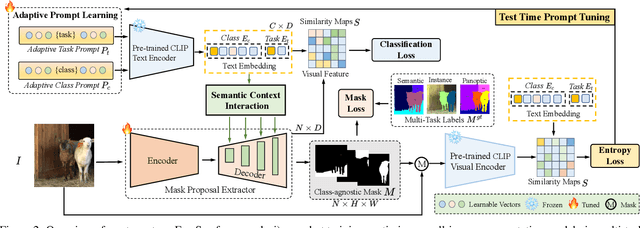
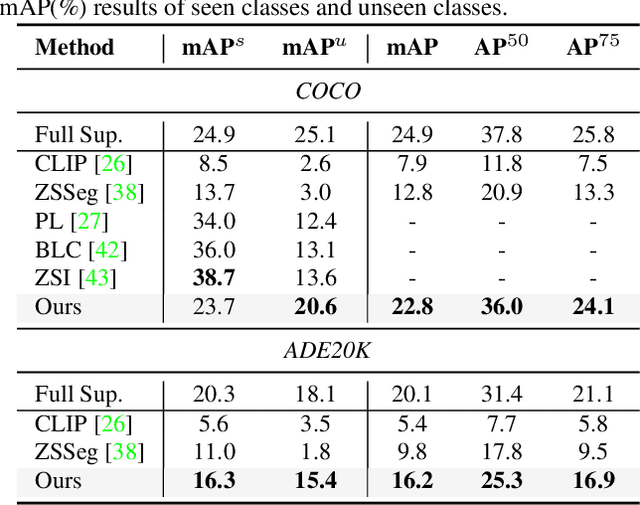
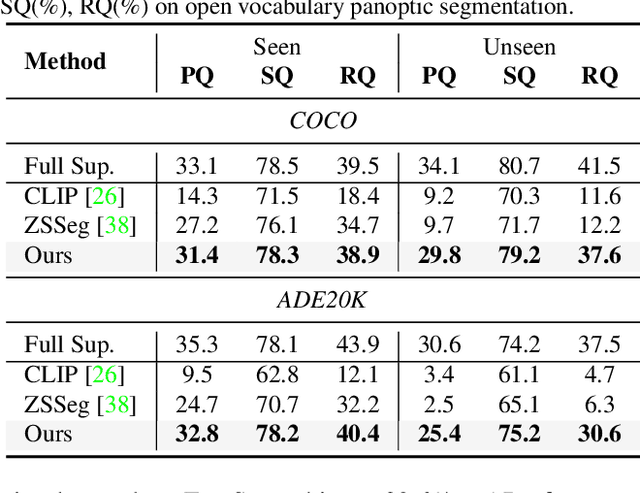
Recently, open-vocabulary learning has emerged to accomplish segmentation for arbitrary categories of text-based descriptions, which popularizes the segmentation system to more general-purpose application scenarios. However, existing methods devote to designing specialized architectures or parameters for specific segmentation tasks. These customized design paradigms lead to fragmentation between various segmentation tasks, thus hindering the uniformity of segmentation models. Hence in this paper, we propose FreeSeg, a generic framework to accomplish Unified, Universal and Open-Vocabulary Image Segmentation. FreeSeg optimizes an all-in-one network via one-shot training and employs the same architecture and parameters to handle diverse segmentation tasks seamlessly in the inference procedure. Additionally, adaptive prompt learning facilitates the unified model to capture task-aware and category-sensitive concepts, improving model robustness in multi-task and varied scenarios. Extensive experimental results demonstrate that FreeSeg establishes new state-of-the-art results in performance and generalization on three segmentation tasks, which outperforms the best task-specific architectures by a large margin: 5.5% mIoU on semantic segmentation, 17.6% mAP on instance segmentation, 20.1% PQ on panoptic segmentation for the unseen class on COCO.
Beyond Self-Supervision: A Simple Yet Effective Network Distillation Alternative to Improve Backbones
Mar 10, 2021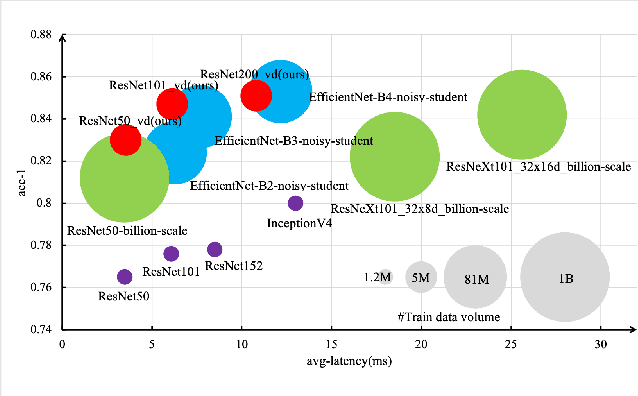
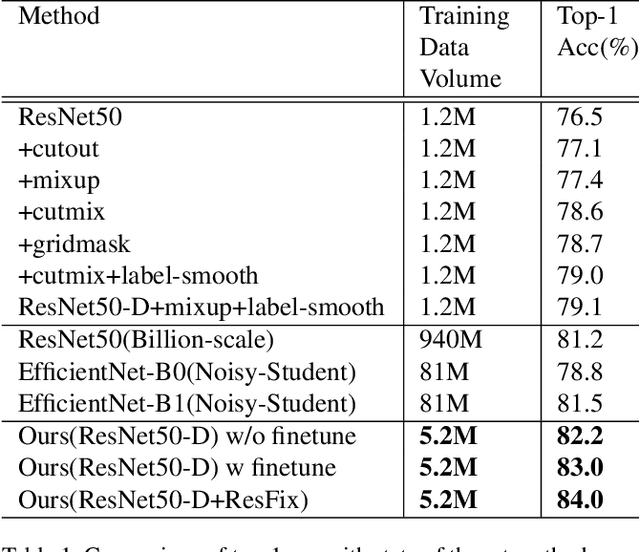
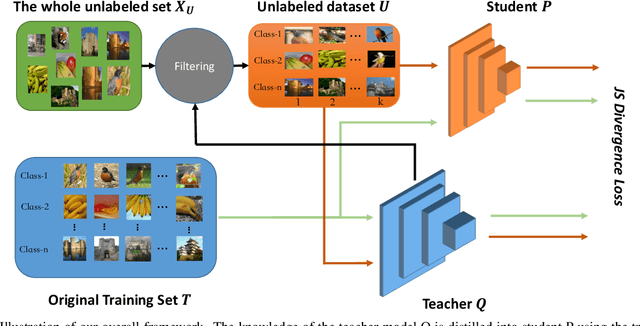
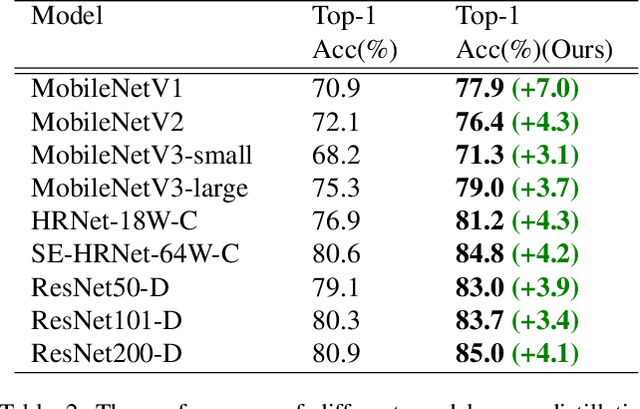
Recently, research efforts have been concentrated on revealing how pre-trained model makes a difference in neural network performance. Self-supervision and semi-supervised learning technologies have been extensively explored by the community and are proven to be of great potential in obtaining a powerful pre-trained model. However, these models require huge training costs (i.e., hundreds of millions of images or training iterations). In this paper, we propose to improve existing baseline networks via knowledge distillation from off-the-shelf pre-trained big powerful models. Different from existing knowledge distillation frameworks which require student model to be consistent with both soft-label generated by teacher model and hard-label annotated by humans, our solution performs distillation by only driving prediction of the student model consistent with that of the teacher model. Therefore, our distillation setting can get rid of manually labeled data and can be trained with extra unlabeled data to fully exploit capability of teacher model for better learning. We empirically find that such simple distillation settings perform extremely effective, for example, the top-1 accuracy on ImageNet-1k validation set of MobileNetV3-large and ResNet50-D can be significantly improved from 75.2% to 79% and 79.1% to 83%, respectively. We have also thoroughly analyzed what are dominant factors that affect the distillation performance and how they make a difference. Extensive downstream computer vision tasks, including transfer learning, object detection and semantic segmentation, can significantly benefit from the distilled pretrained models. All our experiments are implemented based on PaddlePaddle, codes and a series of improved pretrained models with ssld suffix are available in PaddleClas.
Coherent Loss: A Generic Framework for Stable Video Segmentation
Oct 25, 2020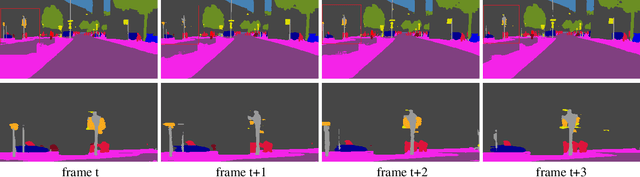

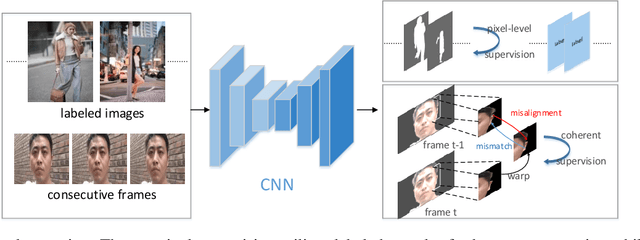
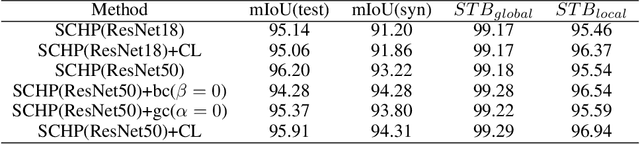
Video segmentation approaches are of great importance for numerous vision tasks especially in video manipulation for entertainment. Due to the challenges associated with acquiring high-quality per-frame segmentation annotations and large video datasets with different environments at scale, learning approaches shows overall higher accuracy on test dataset but lack strict temporal constraints to self-correct jittering artifacts in most practical applications. We investigate how this jittering artifact degrades the visual quality of video segmentation results and proposed a metric of temporal stability to numerically evaluate it. In particular, we propose a Coherent Loss with a generic framework to enhance the performance of a neural network against jittering artifacts, which combines with high accuracy and high consistency. Equipped with our method, existing video object/semantic segmentation approaches achieve a significant improvement in term of more satisfactory visual quality on video human dataset, which we provide for further research in this field, and also on DAVIS and Cityscape.