 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Visual Neglect and Semantic Drift in Large Multimodal Models for Enhanced Cross-Modal Retrieval
Apr 28, 2026Despite significant progress in Unified Multimodal Retrieval (UMR) powered by Large Multimodal Models (LMMs), existing embedding methods primarily focus on sample-level objectives via contrastive learning while overlooking the crucial subject-level semantics. This limitation hinders the model's ability to group semantically coherent subjects in complex multimodal queries, manifesting as semantic alignment deviation--where models fail to accurately localize salient text-referred regions in visual content. Moreover, without explicit guidance to model salient visual subjects, LMMs tend to over-rely on textual cues, resulting in visual modality neglect and suboptimal utilization of visual knowledge. To this end, we propose Salient Subject-Aware Multimodal Embedding (SSA-ME), a novel framework designed to enhance fine-grained representation learning through saliency-aware modeling. SSA-ME leverages LMMs and visual experts to identify and emphasize salient visual concepts in image-text pairs, and introduces a saliency-guided objective to better align cross-modal attention with semantically meaningful regions. Additionally, a feature regeneration module recalibrates visual features based on the derived saliency maps, ensuring a balanced and semantically coherent integration across modalities. Extensive experiments show that our method achieves state-of-the-art performance on the MMEB benchmark, demonstrating that incorporating subject-level modeling substantially improves multimodal retrieval. Comprehensive qualitative analyses further illustrate the interpretability and effectiveness of our approach.
LoReC: Rethinking Large Language Models for Graph Data Analysis
Apr 20, 2026The advent of Large Language Models (LLMs) has fundamentally reshaped the way we interact with graphs, giving rise to a new paradigm called GraphLLM. As revealed in recent studies, graph learning can benefit from LLMs. However, we observe limited benefits when we directly utilize LLMs to make predictions for graph-related tasks within GraphLLM paradigm, which even yields suboptimal results compared to conventional GNN-based approaches. Through in-depth analysis, we find this failure can be attributed to LLMs' limited capability for processing graph data and their tendency to overlook graph information. To address this issue, we propose LoReC (Look, Remember, and Contrast), a novel plug-and-play method for GraphLLM paradigm, which enhances LLM's understanding of graph data through three stages: (1) Look: redistributing attention to graph; (2) Remember: re-injecting graph information into the Feed-Forward Network (FFN); (3) Contrast: rectifying the vanilla logits produced in the decoding process. Extensive experiments demonstrate that LoReC brings notable improvements over current GraphLLM methods and outperforms GNN-based approaches across diverse datasets. The implementation is available at https://github.com/Git-King-Zhan/LoReC.
Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
Mar 19, 2026While Multimodal Large Language Models demonstrate impressive semantic capabilities, they often suffer from spatial blindness, struggling with fine-grained geometric reasoning and physical dynamics. Existing solutions typically rely on explicit 3D modalities or complex geometric scaffolding, which are limited by data scarcity and generalization challenges. In this work, we propose a paradigm shift by leveraging the implicit spatial prior within large-scale video generation models. We posit that to synthesize temporally coherent videos, these models inherently learn robust 3D structural priors and physical laws. We introduce VEGA-3D (Video Extracted Generative Awareness), a plug-and-play framework that repurposes a pre-trained video diffusion model as a Latent World Simulator. By extracting spatiotemporal features from intermediate noise levels and integrating them with semantic representations via a token-level adaptive gated fusion mechanism, we enrich MLLMs with dense geometric cues without explicit 3D supervision. Extensive experiments across 3D scene understanding, spatial reasoning, and embodied manipulation benchmarks demonstrate that our method outperforms state-of-the-art baselines, validating that generative priors provide a scalable foundation for physical-world understanding. Code is publicly available at https://github.com/H-EmbodVis/VEGA-3D.
Speed3R: Sparse Feed-forward 3D Reconstruction Models
Mar 09, 2026While recent feed-forward 3D reconstruction models accelerate 3D reconstruction by jointly inferring dense geometry and camera poses in a single pass, their reliance on dense attention imposes a quadratic complexity, creating a prohibitive computational bottleneck that severely limits inference speed. To resolve this, we introduce Speed3R, an end-to-end trainable model inspired by the core principle of Structure-from-Motion: that a sparse set of keypoints is sufficient for robust pose estimation. Speed3R features a dual-branch attention mechanism where a compression branch creates a coarse contextual prior to guide a selection branch, which performs fine-grained attention only on the most informative image tokens. This strategy mimics the efficiency of traditional keypoint matching, achieving a remarkable 12.4x inference speedup on 1000-view sequences, while introducing a minimal, controlled trade-off in geometric accuracy. Validated on standard benchmarks with both VGGT and $π^3$ backbones, our method delivers high-quality reconstructions at a fraction of computational cost, paving the way for efficient large-scale scene modeling.
From Intuition to Investigation: A Tool-Augmented Reasoning MLLM Framework for Generalizable Face Anti-Spoofing
Mar 01, 2026Face recognition remains vulnerable to presentation attacks, calling for robust Face Anti-Spoofing (FAS) solutions. Recent MLLM-based FAS methods reformulate the binary classification task as the generation of brief textual descriptions to improve cross-domain generalization. However, their generalizability is still limited, as such descriptions mainly capture intuitive semantic cues (e.g., mask contours) while struggling to perceive fine-grained visual patterns. To address this limitation, we incorporate external visual tools into MLLMs to encourage deeper investigation of subtle spoof clues. Specifically, we propose the Tool-Augmented Reasoning FAS (TAR-FAS) framework, which reformulates the FAS task as a Chain-of-Thought with Visual Tools (CoT-VT) paradigm, allowing MLLMs to begin with intuitive observations and adaptively invoke external visual tools for fine-grained investigation. To this end, we design a tool-augmented data annotation pipeline and construct the ToolFAS-16K dataset, which contains multi-turn tool-use reasoning trajectories. Furthermore, we introduce a tool-aware FAS training pipeline, where Diverse-Tool Group Relative Policy Optimization (DT-GRPO) enables the model to autonomously learn efficient tool use. Extensive experiments under a challenging one-to-eleven cross-domain protocol demonstrate that TAR-FAS achieves SOTA performance while providing fine-grained visual investigation for trustworthy spoof detection.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
LaneDiffusion: Improving Centerline Graph Learning via Prior Injected BEV Feature Generation
Nov 09, 2025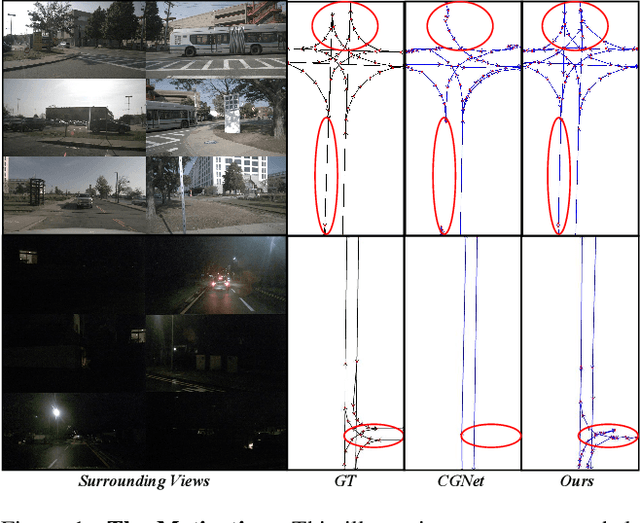
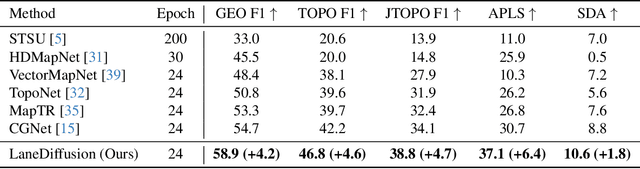
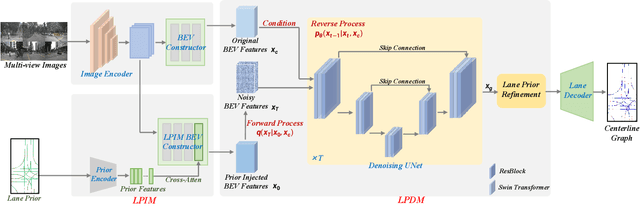
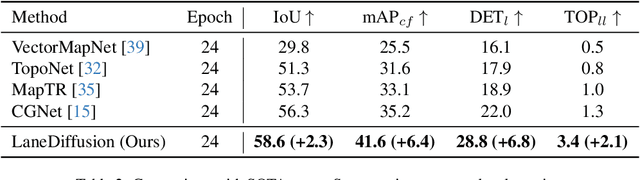
Centerline graphs, crucial for path planning in autonomous driving, are traditionally learned using deterministic methods. However, these methods often lack spatial reasoning and struggle with occluded or invisible centerlines. Generative approaches, despite their potential, remain underexplored in this domain. We introduce LaneDiffusion, a novel generative paradigm for centerline graph learning. LaneDiffusion innovatively employs diffusion models to generate lane centerline priors at the Bird's Eye View (BEV) feature level, instead of directly predicting vectorized centerlines. Our method integrates a Lane Prior Injection Module (LPIM) and a Lane Prior Diffusion Module (LPDM) to effectively construct diffusion targets and manage the diffusion process. Furthermore, vectorized centerlines and topologies are then decoded from these prior-injected BEV features. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that LaneDiffusion significantly outperforms existing methods, achieving improvements of 4.2%, 4.6%, 4.7%, 6.4% and 1.8% on fine-grained point-level metrics (GEO F1, TOPO F1, JTOPO F1, APLS and SDA) and 2.3%, 6.4%, 6.8% and 2.1% on segment-level metrics (IoU, mAP_cf, DET_l and TOP_ll). These results establish state-of-the-art performance in centerline graph learning, offering new insights into generative models for this task.
AdaDrive: Self-Adaptive Slow-Fast System for Language-Grounded Autonomous Driving
Nov 09, 2025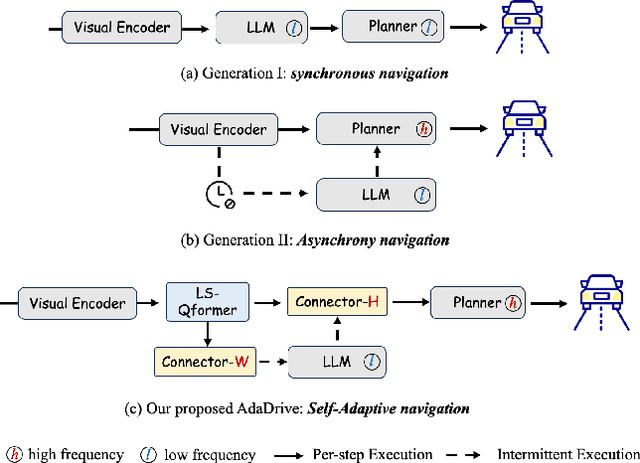
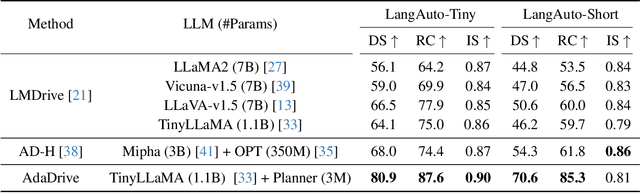
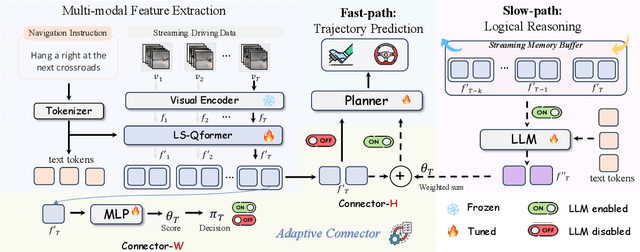
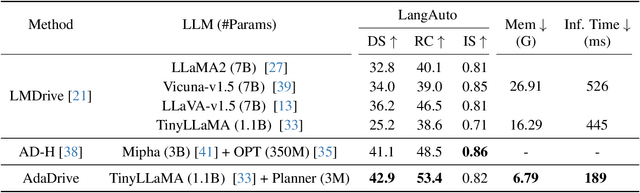
Effectively integrating Large Language Models (LLMs) into autonomous driving requires a balance between leveraging high-level reasoning and maintaining real-time efficiency. Existing approaches either activate LLMs too frequently, causing excessive computational overhead, or use fixed schedules, failing to adapt to dynamic driving conditions. To address these challenges, we propose AdaDrive, an adaptively collaborative slow-fast framework that optimally determines when and how LLMs contribute to decision-making. (1) When to activate the LLM: AdaDrive employs a novel adaptive activation loss that dynamically determines LLM invocation based on a comparative learning mechanism, ensuring activation only in complex or critical scenarios. (2) How to integrate LLM assistance: Instead of rigid binary activation, AdaDrive introduces an adaptive fusion strategy that modulates a continuous, scaled LLM influence based on scene complexity and prediction confidence, ensuring seamless collaboration with conventional planners. Through these strategies, AdaDrive provides a flexible, context-aware framework that maximizes decision accuracy without compromising real-time performance. Extensive experiments on language-grounded autonomous driving benchmarks demonstrate that AdaDrive state-of-the-art performance in terms of both driving accuracy and computational efficiency. Code is available at https://github.com/ReaFly/AdaDrive.
VLDrive: Vision-Augmented Lightweight MLLMs for Efficient Language-grounded Autonomous Driving
Nov 09, 2025Recent advancements in language-grounded autonomous driving have been significantly promoted by the sophisticated cognition and reasoning capabilities of large language models (LLMs). However, current LLM-based approaches encounter critical challenges: (1) Failure analysis reveals that frequent collisions and obstructions, stemming from limitations in visual representations, remain primary obstacles to robust driving performance. (2) The substantial parameters of LLMs pose considerable deployment hurdles. To address these limitations, we introduce VLDrive, a novel approach featuring a lightweight MLLM architecture with enhanced vision components. VLDrive achieves compact visual tokens through innovative strategies, including cycle-consistent dynamic visual pruning and memory-enhanced feature aggregation. Furthermore, we propose a distance-decoupled instruction attention mechanism to improve joint visual-linguistic feature learning, particularly for long-range visual tokens. Extensive experiments conducted in the CARLA simulator demonstrate VLDrive`s effectiveness. Notably, VLDrive achieves state-of-the-art driving performance while reducing parameters by 81% (from 7B to 1.3B), yielding substantial driving score improvements of 15.4%, 16.8%, and 7.6% at tiny, short, and long distances, respectively, in closed-loop evaluations. Code is available at https://github.com/ReaFly/VLDrive.
Safe Navigation under State Uncertainty: Online Adaptation for Robust Control Barrier Functions
Aug 26, 2025Measurements and state estimates are often imperfect in control practice, posing challenges for safety-critical applications, where safety guarantees rely on accurate state information. In the presence of estimation errors, several prior robust control barrier function (R-CBF) formulations have imposed strict conditions on the input. These methods can be overly conservative and can introduce issues such as infeasibility, high control effort, etc. This work proposes a systematic method to improve R-CBFs, and demonstrates its advantages on a tracked vehicle that navigates among multiple obstacles. A primary contribution is a new optimization-based online parameter adaptation scheme that reduces the conservativeness of existing R-CBFs. In order to reduce the complexity of the parameter optimization, we merge several safety constraints into one unified numerical CBF via Poisson's equation. We further address the dual relative degree issue that typically causes difficulty in vehicle tracking. Experimental trials demonstrate the overall performance improvement of our approach over existing formulations.