 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Safety Filter: Towards Safe Flight Control under Sensor Attacks
May 11, 2025Modern autopilot systems are prone to sensor attacks that can jeopardize flight safety. To mitigate this risk, we proposed a modular solution: the secure safety filter, which extends the well-established control barrier function (CBF)-based safety filter to account for, and mitigate, sensor attacks. This module consists of a secure state reconstructor (which generates plausible states) and a safety filter (which computes the safe control input that is closest to the nominal one). Differing from existing work focusing on linear, noise-free systems, the proposed secure safety filter handles bounded measurement noise and, by leveraging reduced-order model techniques, is applicable to the nonlinear dynamics of drones. Software-in-the-loop simulations and drone hardware experiments demonstrate the effectiveness of the secure safety filter in rendering the system safe in the presence of sensor attacks.
Learning In-Distribution Representations for Anomaly Detection
Jan 10, 2025



Anomaly detection involves identifying data patterns that deviate from the anticipated norm. Traditional methods struggle in high-dimensional spaces due to the curse of dimensionality. In recent years, self-supervised learning, particularly through contrastive objectives, has driven advances in anomaly detection. However, vanilla contrastive learning struggles to align with the unique demands of anomaly detection, as it lacks a pretext task tailored to the homogeneous nature of In-Distribution (ID) data and the diversity of Out-of-Distribution (OOD) anomalies. Methods that attempt to address these challenges, such as introducing hard negatives through synthetic outliers, Outlier Exposure (OE), and supervised objectives, often rely on pretext tasks that fail to balance compact clustering of ID samples with sufficient separation from OOD data. In this work, we propose Focused In-distribution Representation Modeling (FIRM), a contrastive learning objective specifically designed for anomaly detection. Unlike existing approaches, FIRM incorporates synthetic outliers into its pretext task in a way that actively shapes the representation space, promoting compact clustering of ID samples while enforcing strong separation from outliers. This formulation addresses the challenges of class collision, enhancing both the compactness of ID representations and the discriminative power of the learned feature space. We show that FIRM surpasses other contrastive methods in standard benchmarks, significantly enhancing anomaly detection compared to both traditional and supervised contrastive learning objectives. Our ablation studies confirm that FIRM consistently improves the quality of representations and shows robustness across a range of scoring methods. The code is available at: https://github.com/willtl/firm.
Non-Robust Features are Not Always Useful in One-Class Classification
Jul 08, 2024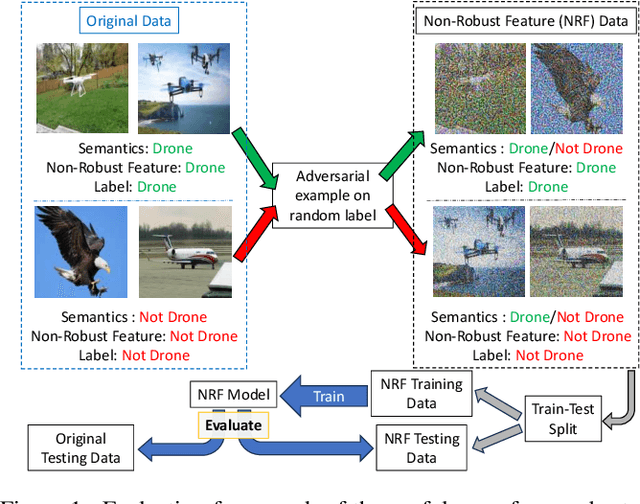

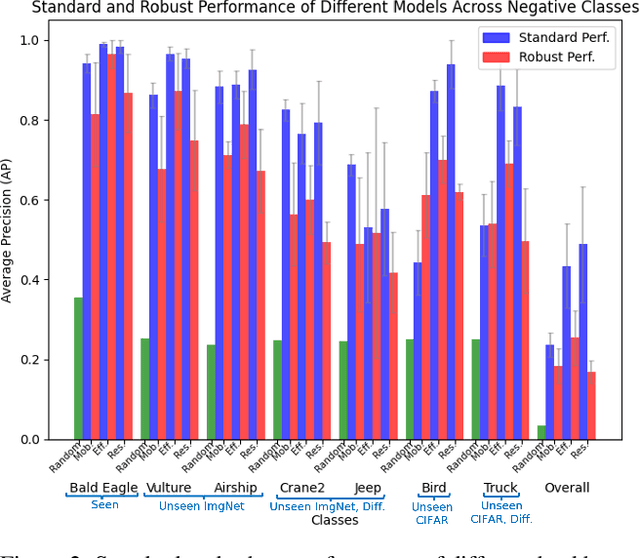
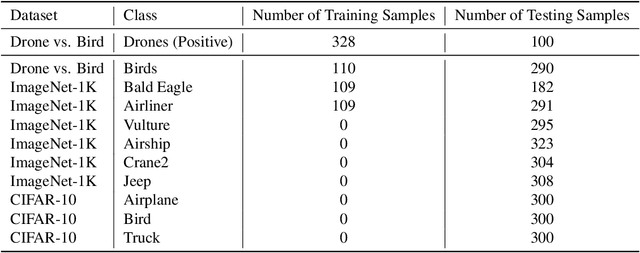
The robustness of machine learning models has been questioned by the existence of adversarial examples. We examine the threat of adversarial examples in practical applications that require lightweight models for one-class classification. Building on Ilyas et al. (2019), we investigate the vulnerability of lightweight one-class classifiers to adversarial attacks and possible reasons for it. Our results show that lightweight one-class classifiers learn features that are not robust (e.g. texture) under stronger attacks. However, unlike in multi-class classification (Ilyas et al., 2019), these non-robust features are not always useful for the one-class task, suggesting that learning these unpredictive and non-robust features is an unwanted consequence of training.