 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLORE: Jointly Learning the Intrinsic Dimensionality and Relative Similarity Structure From Ordinal Data
Feb 04, 2026Learning the intrinsic dimensionality of subjective perceptual spaces such as taste, smell, or aesthetics from ordinal data is a challenging problem. We introduce LORE (Low Rank Ordinal Embedding), a scalable framework that jointly learns both the intrinsic dimensionality and an ordinal embedding from noisy triplet comparisons of the form, "Is A more similar to B than C?". Unlike existing methods that require the embedding dimension to be set apriori, LORE regularizes the solution using the nonconvex Schatten-$p$ quasi norm, enabling automatic joint recovery of both the ordinal embedding and its dimensionality. We optimize this joint objective via an iteratively reweighted algorithm and establish convergence guarantees. Extensive experiments on synthetic datasets, simulated perceptual spaces, and real world crowdsourced ordinal judgements show that LORE learns compact, interpretable and highly accurate low dimensional embeddings that recover the latent geometry of subjective percepts. By simultaneously inferring both the intrinsic dimensionality and ordinal embeddings, LORE enables more interpretable and data efficient perceptual modeling in psychophysics and opens new directions for scalable discovery of low dimensional structure from ordinal data in machine learning.
Diffusion Explorer: Interactive Exploration of Diffusion Models
Jul 01, 2025Diffusion models have been central to the development of recent image, video, and even text generation systems. They posses striking geometric properties that can be faithfully portrayed in low-dimensional settings. However, existing resources for explaining diffusion either require an advanced theoretical foundation or focus on their neural network architectures rather than their rich geometric properties. We introduce Diffusion Explorer, an interactive tool to explain the geometric properties of diffusion models. Users can train 2D diffusion models in the browser and observe the temporal dynamics of their sampling process. Diffusion Explorer leverages interactive animation, which has been shown to be a powerful tool for making engaging visualizations of dynamic systems, making it well suited to explaining diffusion models which represent stochastic processes that evolve over time. Diffusion Explorer is open source and a live demo is available at alechelbling.com/Diffusion-Explorer.
ConceptAttention: Diffusion Transformers Learn Highly Interpretable Features
Feb 06, 2025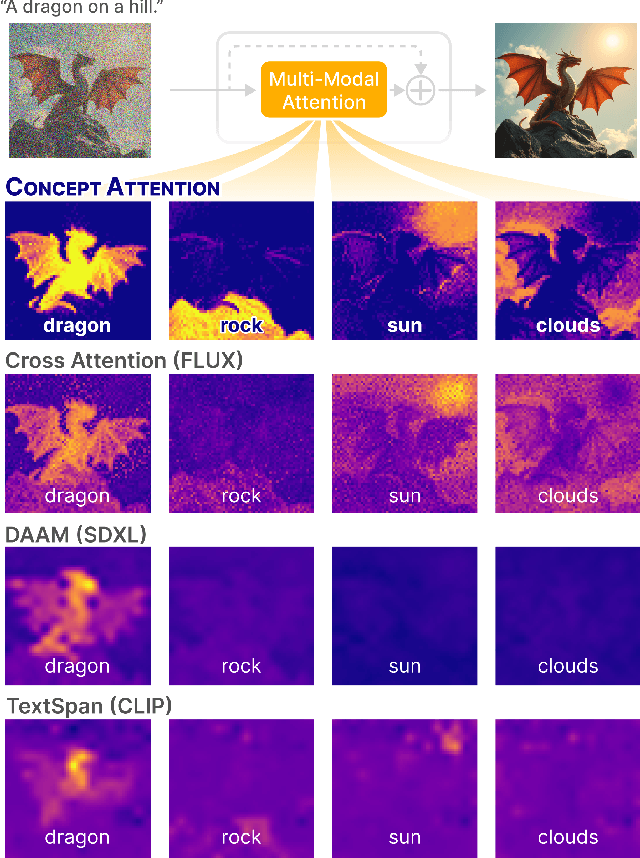
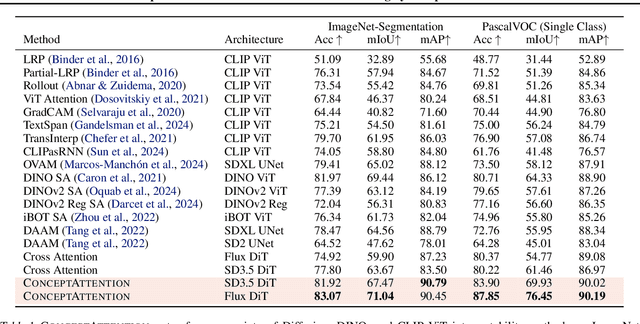
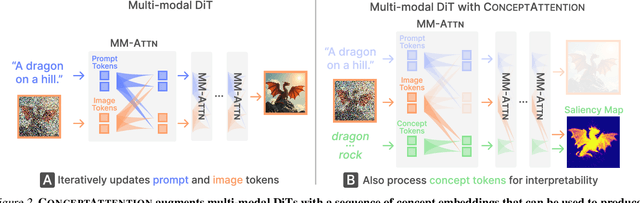
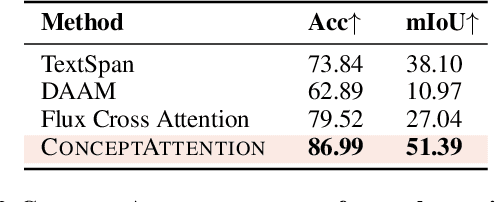
Do the rich representations of multi-modal diffusion transformers (DiTs) exhibit unique properties that enhance their interpretability? We introduce ConceptAttention, a novel method that leverages the expressive power of DiT attention layers to generate high-quality saliency maps that precisely locate textual concepts within images. Without requiring additional training, ConceptAttention repurposes the parameters of DiT attention layers to produce highly contextualized concept embeddings, contributing the major discovery that performing linear projections in the output space of DiT attention layers yields significantly sharper saliency maps compared to commonly used cross-attention mechanisms. Remarkably, ConceptAttention even achieves state-of-the-art performance on zero-shot image segmentation benchmarks, outperforming 11 other zero-shot interpretability methods on the ImageNet-Segmentation dataset and on a single-class subset of PascalVOC. Our work contributes the first evidence that the representations of multi-modal DiT models like Flux are highly transferable to vision tasks like segmentation, even outperforming multi-modal foundation models like CLIP.
Transformer Explainer: Interactive Learning of Text-Generative Models
Aug 08, 2024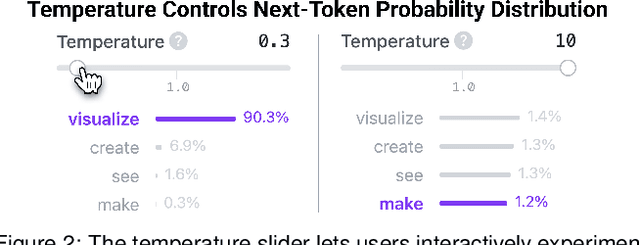
Transformers have revolutionized machine learning, yet their inner workings remain opaque to many. We present Transformer Explainer, an interactive visualization tool designed for non-experts to learn about Transformers through the GPT-2 model. Our tool helps users understand complex Transformer concepts by integrating a model overview and enabling smooth transitions across abstraction levels of mathematical operations and model structures. It runs a live GPT-2 instance locally in the user's browser, empowering users to experiment with their own input and observe in real-time how the internal components and parameters of the Transformer work together to predict the next tokens. Our tool requires no installation or special hardware, broadening the public's education access to modern generative AI techniques. Our open-sourced tool is available at https://poloclub.github.io/transformer-explainer/. A video demo is available at https://youtu.be/ECR4oAwocjs.
Non-Robust Features are Not Always Useful in One-Class Classification
Jul 08, 2024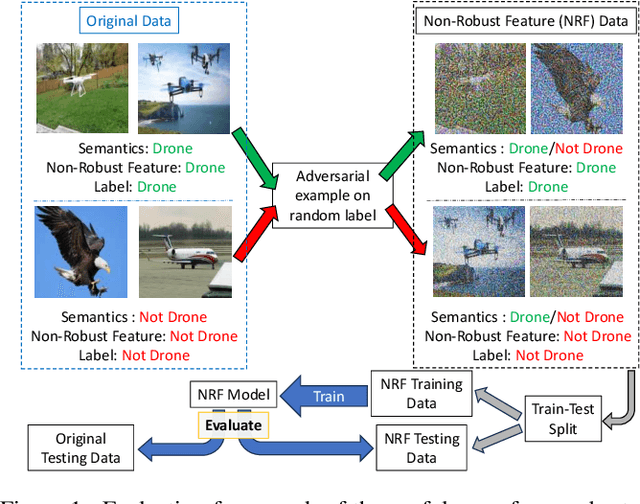

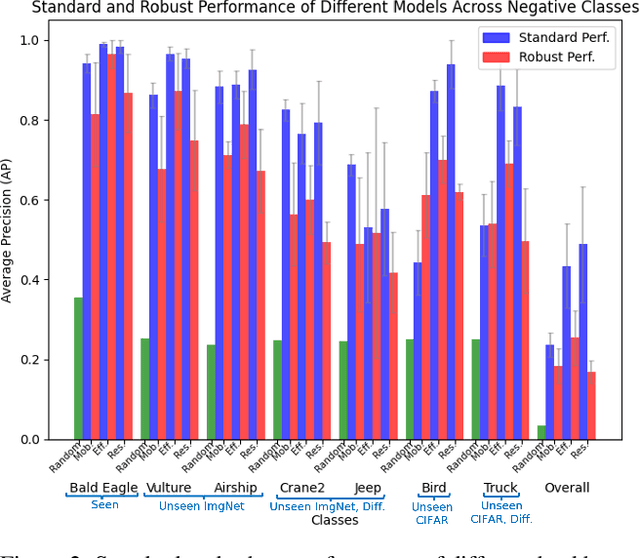
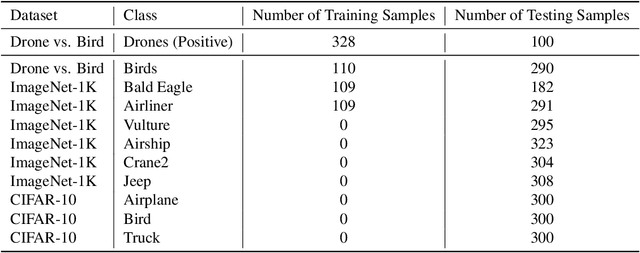
The robustness of machine learning models has been questioned by the existence of adversarial examples. We examine the threat of adversarial examples in practical applications that require lightweight models for one-class classification. Building on Ilyas et al. (2019), we investigate the vulnerability of lightweight one-class classifiers to adversarial attacks and possible reasons for it. Our results show that lightweight one-class classifiers learn features that are not robust (e.g. texture) under stronger attacks. However, unlike in multi-class classification (Ilyas et al., 2019), these non-robust features are not always useful for the one-class task, suggesting that learning these unpredictive and non-robust features is an unwanted consequence of training.
ClickDiffusion: Harnessing LLMs for Interactive Precise Image Editing
Apr 05, 2024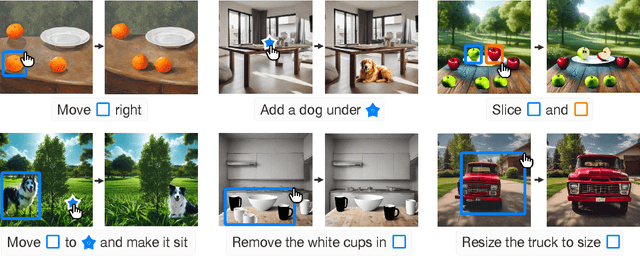


Recently, researchers have proposed powerful systems for generating and manipulating images using natural language instructions. However, it is difficult to precisely specify many common classes of image transformations with text alone. For example, a user may wish to change the location and breed of a particular dog in an image with several similar dogs. This task is quite difficult with natural language alone, and would require a user to write a laboriously complex prompt that both disambiguates the target dog and describes the destination. We propose ClickDiffusion, a system for precise image manipulation and generation that combines natural language instructions with visual feedback provided by the user through a direct manipulation interface. We demonstrate that by serializing both an image and a multi-modal instruction into a textual representation it is possible to leverage LLMs to perform precise transformations of the layout and appearance of an image. Code available at https://github.com/poloclub/ClickDiffusion.
LLM Attributor: Interactive Visual Attribution for LLM Generation
Apr 01, 2024

While large language models (LLMs) have shown remarkable capability to generate convincing text across diverse domains, concerns around its potential risks have highlighted the importance of understanding the rationale behind text generation. We present LLM Attributor, a Python library that provides interactive visualizations for training data attribution of an LLM's text generation. Our library offers a new way to quickly attribute an LLM's text generation to training data points to inspect model behaviors, enhance its trustworthiness, and compare model-generated text with user-provided text. We describe the visual and interactive design of our tool and highlight usage scenarios for LLaMA2 models fine-tuned with two different datasets: online articles about recent disasters and finance-related question-answer pairs. Thanks to LLM Attributor's broad support for computational notebooks, users can easily integrate it into their workflow to interactively visualize attributions of their models. For easier access and extensibility, we open-source LLM Attributor at https://github.com/poloclub/ LLM-Attribution. The video demo is available at https://youtu.be/mIG2MDQKQxM.
Point and Instruct: Enabling Precise Image Editing by Unifying Direct Manipulation and Text Instructions
Feb 05, 2024Machine learning has enabled the development of powerful systems capable of editing images from natural language instructions. However, in many common scenarios it is difficult for users to specify precise image transformations with text alone. For example, in an image with several dogs, it is difficult to select a particular dog and move it to a precise location. Doing this with text alone would require a complex prompt that disambiguates the target dog and describes the destination. However, direct manipulation is well suited to visual tasks like selecting objects and specifying locations. We introduce Point and Instruct, a system for seamlessly combining familiar direct manipulation and textual instructions to enable precise image manipulation. With our system, a user can visually mark objects and locations, and reference them in textual instructions. This allows users to benefit from both the visual descriptiveness of natural language and the spatial precision of direct manipulation.
Mobile Fitting Room: On-device Virtual Try-on via Diffusion Models
Feb 02, 2024The growing digital landscape of fashion e-commerce calls for interactive and user-friendly interfaces for virtually trying on clothes. Traditional try-on methods grapple with challenges in adapting to diverse backgrounds, poses, and subjects. While newer methods, utilizing the recent advances of diffusion models, have achieved higher-quality image generation, the human-centered dimensions of mobile interface delivery and privacy concerns remain largely unexplored. We present Mobile Fitting Room, the first on-device diffusion-based virtual try-on system. To address multiple inter-related technical challenges such as high-quality garment placement and model compression for mobile devices, we present a novel technical pipeline and an interface design that enables privacy preservation and user customization. A usage scenario highlights how our tool can provide a seamless, interactive virtual try-on experience for customers and provide a valuable service for fashion e-commerce businesses.
ObjectComposer: Consistent Generation of Multiple Objects Without Fine-tuning
Oct 10, 2023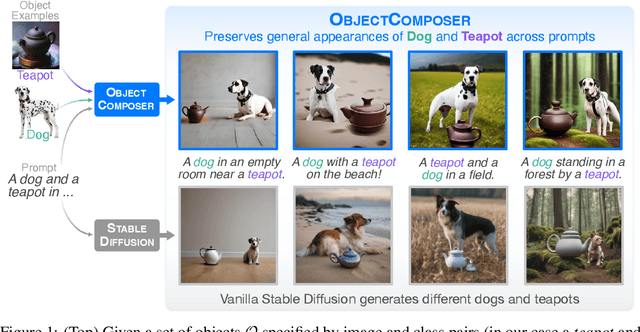
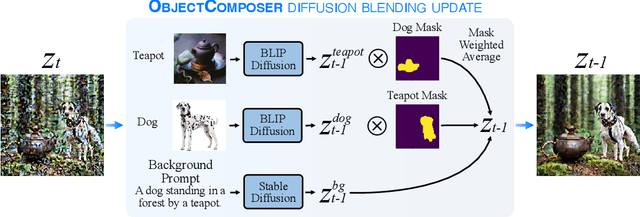

Recent text-to-image generative models can generate high-fidelity images from text prompts. However, these models struggle to consistently generate the same objects in different contexts with the same appearance. Consistent object generation is important to many downstream tasks like generating comic book illustrations with consistent characters and setting. Numerous approaches attempt to solve this problem by extending the vocabulary of diffusion models through fine-tuning. However, even lightweight fine-tuning approaches can be prohibitively expensive to run at scale and in real-time. We introduce a method called ObjectComposer for generating compositions of multiple objects that resemble user-specified images. Our approach is training-free, leveraging the abilities of preexisting models. We build upon the recent BLIP-Diffusion model, which can generate images of single objects specified by reference images. ObjectComposer enables the consistent generation of compositions containing multiple specific objects simultaneously, all without modifying the weights of the underlying models.