 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Fitting Room: On-device Virtual Try-on via Diffusion Models
Feb 02, 2024The growing digital landscape of fashion e-commerce calls for interactive and user-friendly interfaces for virtually trying on clothes. Traditional try-on methods grapple with challenges in adapting to diverse backgrounds, poses, and subjects. While newer methods, utilizing the recent advances of diffusion models, have achieved higher-quality image generation, the human-centered dimensions of mobile interface delivery and privacy concerns remain largely unexplored. We present Mobile Fitting Room, the first on-device diffusion-based virtual try-on system. To address multiple inter-related technical challenges such as high-quality garment placement and model compression for mobile devices, we present a novel technical pipeline and an interface design that enables privacy preservation and user customization. A usage scenario highlights how our tool can provide a seamless, interactive virtual try-on experience for customers and provide a valuable service for fashion e-commerce businesses.
Wordflow: Social Prompt Engineering for Large Language Models
Jan 25, 2024

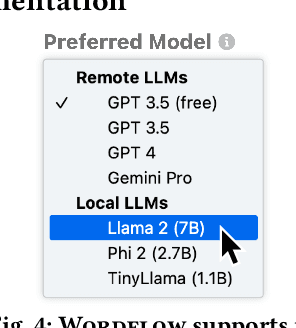

Large language models (LLMs) require well-crafted prompts for effective use. Prompt engineering, the process of designing prompts, is challenging, particularly for non-experts who are less familiar with AI technologies. While researchers have proposed techniques and tools to assist LLM users in prompt design, these works primarily target AI application developers rather than non-experts. To address this research gap, we propose social prompt engineering, a novel paradigm that leverages social computing techniques to facilitate collaborative prompt design. To investigate social prompt engineering, we introduce Wordflow, an open-source and social text editor that enables everyday users to easily create, run, share, and discover LLM prompts. Additionally, by leveraging modern web technologies, Wordflow allows users to run LLMs locally and privately in their browsers. Two usage scenarios highlight how social prompt engineering and our tool can enhance laypeople's interaction with LLMs. Wordflow is publicly accessible at https://poloclub.github.io/wordflow.
SuperNOVA: Design Strategies and Opportunities for Interactive Visualization in Computational Notebooks
May 04, 2023


Computational notebooks such as Jupyter Notebook have become data scientists' de facto programming environments. Many visualization researchers and practitioners have developed interactive visualization tools that support notebooks. However, little is known about the appropriate design of visual analytics (VA) tools in notebooks. To bridge this critical research gap, we investigate the design strategies in this space by analyzing 159 notebook VA tools and their users' feedback. Our analysis encompasses 62 systems from academic papers and 103 systems sourced from a pool of 55k notebooks containing interactive visualizations that we obtain via scraping 8.6 million notebooks on GitHub. We also examine findings from 15 user studies and user feedback in 379 GitHub issues. Through this work, we identify unique design opportunities and considerations for future notebook VA tools, such as using and manipulating multimodal data in notebooks as well as balancing the degree of visualization-notebook integration. Finally, we develop SuperNOVA, an open-source interactive tool to help researchers explore existing notebook VA tools and search for related work.
DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models
Nov 15, 2022With recent advancements in diffusion models, users can generate high-quality images by writing text prompts in natural language. However, generating images with desired details requires proper prompts, and it is often unclear how a model reacts to different prompts and what the best prompts are. To help researchers tackle these critical challenges, we introduce DiffusionDB, the first large-scale text-to-image prompt dataset. DiffusionDB contains 14 million images generated by Stable Diffusion using prompts and hyperparameters specified by real users. We analyze prompts in the dataset and discuss key properties of these prompts. The unprecedented scale and diversity of this human-actuated dataset provide exciting research opportunities in understanding the interplay between prompts and generative models, detecting deepfakes, and designing human-AI interaction tools to help users more easily use these models. DiffusionDB is publicly available at: https://poloclub.github.io/diffusiondb.
Visual Auditor: Interactive Visualization for Detection and Summarization of Model Biases
Jun 25, 2022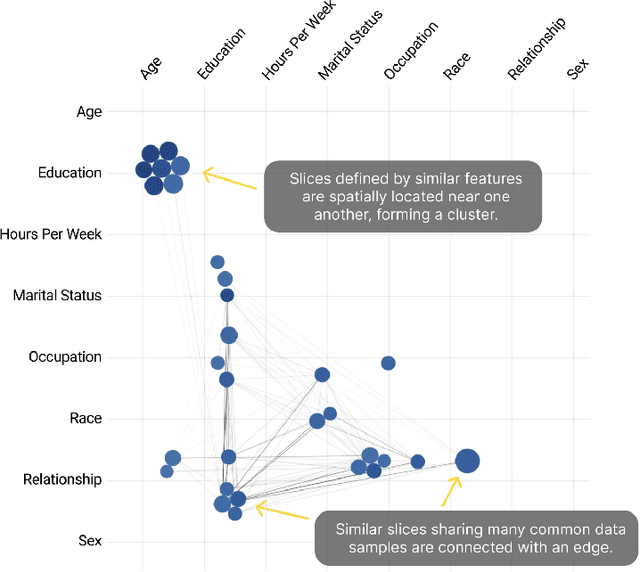

As machine learning (ML) systems become increasingly widespread, it is necessary to audit these systems for biases prior to their deployment. Recent research has developed algorithms for effectively identifying intersectional bias in the form of interpretable, underperforming subsets (or slices) of the data. However, these solutions and their insights are limited without a tool for visually understanding and interacting with the results of these algorithms. We propose Visual Auditor, an interactive visualization tool for auditing and summarizing model biases. Visual Auditor assists model validation by providing an interpretable overview of intersectional bias (bias that is present when examining populations defined by multiple features), details about relationships between problematic data slices, and a comparison between underperforming and overperforming data slices in a model. Our open-source tool runs directly in both computational notebooks and web browsers, making model auditing accessible and easily integrated into current ML development workflows. An observational user study in collaboration with domain experts at Fiddler AI highlights that our tool can help ML practitioners identify and understand model biases.